[論文レビュー] YaRN: Efficient Context Window Extension of Large Language Models
YaRNは、RoPEベースのLLMの文脈窓を効率的に拡張するための対象を絞ったRoPE補間手法と推論時のアテンション温度スケーリングを組み合わせて、最小の微調整とデータで最先端の拡張を実現します。LLaMA-2モデルで128kの文脈までを可能にし、転移と長シーケンス性能が高いことを示します。
Rotary Position Embeddings (RoPE) have been shown to effectively encode positional information in transformer-based language models. However, these models fail to generalize past the sequence length they were trained on. We present YaRN (Yet another RoPE extensioN method), a compute-efficient method to extend the context window of such models, requiring 10x less tokens and 2.5x less training steps than previous methods. Using YaRN, we show that LLaMA models can effectively utilize and extrapolate to context lengths much longer than their original pre-training would allow, while also surpassing previous the state-of-the-art at context window extension. In addition, we demonstrate that YaRN exhibits the capability to extrapolate beyond the limited context of a fine-tuning dataset. Code is available at https://github.com/jquesnelle/yarn
研究の動機と目的
- RoPEベースのトランスフォーマーモデルの文脈窓を事前学習限界を超えて拡張する動機づけと実現を目指す。
- YaRNを提案する:高周波情報と局所距離を保持するためのRoPE補間のターゲット手法と注意スケーリング(アテンション温度スケーリング)を組み合わせる。
- 計算効率の良い微調整(データ約0.1%程度)と効果的なゼロショット/推論時外挿を実証する。
- 長いシーケンス perplexity、パスキー取得、標準ベンチマークで YaRN を LLaMA/Llama 2 ファミリに対して評価し、堅牢性と転移性を示す。
提案手法
- YaRNを、RoPE周波数全体へのターゲット補間を行うNTK-by-parts補間と、長さスケーリングのトリックとして実装された注意温度スケーリング(対数ロジット温度t)を組み合わせたものとして定式化する。
- λ_dと文脈長Lに基づきRoPE次元を選択的に補間するようにg(m)とh(θ_d)を定義し、補間の有無を決定するランプ関数γを用いる。
- r(d)=L/λ_d によってRoPE次元を分類し、適切な場合に線形補間sを適用しつつ、高周波数の次元はそのまま残すNTK-by-partsを用いる。
- 推論時にDynamic Scalingを適用して前方伝播ごとにスケールsを更新し、事前学習限界を優雅に拡張する(Dynamic NTK)。
- 小規模な微調整データセット(PG19、拡張ステップごとに64kトークン)を用い、低ステップ(s=16で400ステップ、s=32で200ステップ)と標準最適化(AdamW、LR=2e-5)で訓練する。
- Table 2、Figure 1、および Tables 1–5を再現するためのコードと評価ツールを提供し、再現性のあるセットアップを提供する。
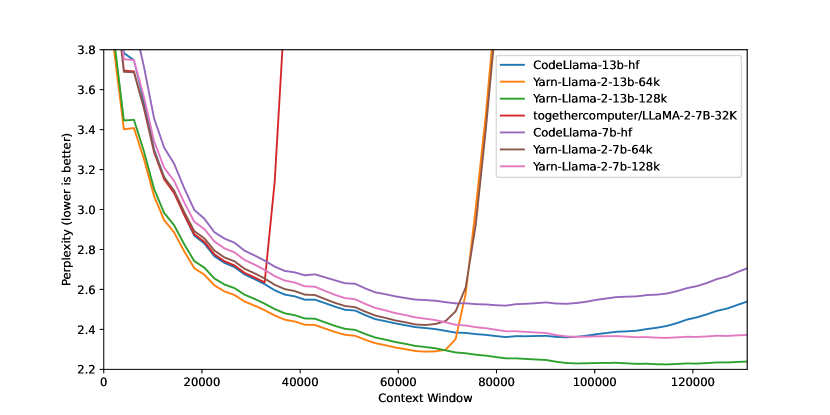
実験結果
リサーチクエスチョン
- RQ1RoPEベースのLLMは、事前学習ウィンドウよりはるかに長い文脈長に対して、計算効率的な補間手法を用いて一般化できるか。
- RQ2ターゲット補間(NTK-by-parts)と推論時スケーリング(YaRN)を組み合わせた場合、長い文脈タスクにおけるPIおよびNTK認識手法と比較してどう機能するか。
- RQ3YaRNの転送と外挿能力は、モデル規模(7B、13B)や限られたデータでの微調整後にどう変化するか。
- RQ4YaRNは標準ベンチマークでの性能を保ちながら、非常に長い文脈窓へ拡張できるか。
- RQ5Dynamic Scalingを用いた再訓練なしでも実用的なゼロショット/推論時の文脈拡張手段はあるか。
主な発見
| 拡張 | 学習済みトークン数 | コンテキストウィンドウ | 2048 | 4096 | 6144 | 8192 | 10240 |
|---|---|---|---|---|---|---|---|
| PI (s=2) | 1B | 8k | 3.92 | 3.51 | 3.51 | 3.34 | 8.07 |
| NTK (θ=20k) | 1B | 8k | 4.20 | 3.75 | 3.74 | 3.59 | 6.24 |
| YaRN (s=2) | 400M | 8k | 3.91 | 3.50 | 3.51 | 3.35 | 6.04 |
- YaRNは事前学習データ約0.1%と400ステップ(s=16)、200ステップ(s=32)という低い学習量で最先端の文脈窓拡張を達成する。
- YaRNはLLaMA/Llama 2モデルを128kの文脈へ外挿させ、128kでの困惑度の改善を継続する(s=32)。
- PIおよびNTK認識ベースのベースラインと比較して、YaRNは長い文脈の困惑度とパスキー取得性能が優れ、標準ベンチマークでの劣化は最小限。
- Dynamic NTK(Dynamic Scaling)により微調整なしで文脈拡張が可能であり、YaRNのNTK-by-partsと温度スケーリングは幅広い文脈長で性能を維持する。
- YaRNは優れた転移学習を示し、s=16モデルから再学習せずに補間埋め込みを移行しつつ、より大きな文脈拡張(sを16から32へ)を可能にする。
- Open LLMベンチマークでは、YaRNモデルはLlama 2ベースラインに対して性能低下がほとんどなく、s=16とs=32の間で平均的な小さな低下のみ。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。