[論文レビュー] Yi: Open Foundation Models by 01.AI
Yiは、チャット、長文コンテキスト(200K)、深さの拡張、視覚言語バリアントへと拡張した6Bおよび34B言語モデルを提示し、データ品質とスケーラブルなインフラストラクチャを強調して、低コストでGPT-3.5レベルの性能を達成する。
We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language models, then we extend them to chat models, 200K long context models, depth-upscaled models, and vision-language models. Our base models achieve strong performance on a wide range of benchmarks like MMLU, and our finetuned chat models deliver strong human preference rate on major evaluation platforms like AlpacaEval and Chatbot Arena. Building upon our scalable super-computing infrastructure and the classical transformer architecture, we attribute the performance of Yi models primarily to its data quality resulting from our data-engineering efforts. For pretraining, we construct 3.1 trillion tokens of English and Chinese corpora using a cascaded data deduplication and quality filtering pipeline. For finetuning, we polish a small scale (less than 10K) instruction dataset over multiple iterations such that every single instance has been verified directly by our machine learning engineers. For vision-language, we combine the chat language model with a vision transformer encoder and train the model to align visual representations to the semantic space of the language model. We further extend the context length to 200K through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. We show that extending the depth of the pretrained checkpoint through continual pretraining further improves performance. We believe that given our current results, continuing to scale up model parameters using thoroughly optimized data will lead to even stronger frontier models.
研究の動機と目的
- 高品質にトレーニングされた大規模で慎重にフィルタリングされたバイリンガルコーパスを用いた6Bおよび34B言語モデルの高性能を実証する。
- チャット、長文コンテキスト(200K)、深さの拡張、視覚言語バリアントへの拡張を披露する。
- データ品質、前処理、アライメント戦略が強力なベンチマークと人間の好みを可能にすることを調査する。
- 事前学習、微調整、効率的な提供を支援するスケーラブルなインフラと最適化技術を提供する。
提案手法
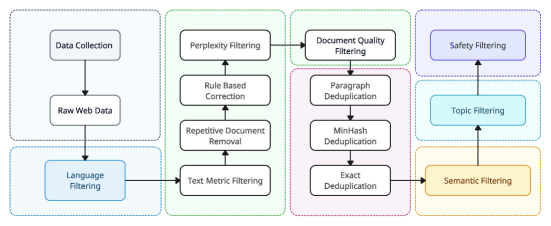
- 3.1Tの英語/中国語のバイリンガルトークンで、階層型デデュプリケーションと品質フィルタリングを用いて6Bおよび34Bデコーダー・Onlyトランスフォーマーを事前学習する。
- 長文コンテキスト拡張のため、Grouped-Query Attention (GQA)、SwiGLU活性化、Rotary/RoPEベースの位置エンベディングとRoPE ABFを組み込み。
- ChatML形式のプロンプトを用いた少量で高品質な指示データセット(<10K)で微調整を行う。
- 長シーケンス事前学習、視覚エンコーダによる視覚言語整合、継続的事前学習による深さの拡張を通じた能力拡張。
- クロスクラウドスケジューリング、堅牢なトレーニング、効率的な推論のための4-bit/8-bit量子化、ダイナミックバッチ処理、PagedAttentionを用いたフルスタックインフラを構築する。
実験結果
リサーチクエスチョン
- RQ1小規模から中規模のモデル(6B/34B)が、データ厳選を重ねた標準ベンチマークでGPT-3.5レベルの性能に匹敵できるか。
- RQ2文脈長を200Kに増やし、視覚言語整合を追加することで、検索能力とマルチモーダル機能が著しく向上するか。
- RQ3継続的事前学習による深さの拡張がモデル性能に与える影響は何か。
- RQ4データ品質とターゲットを絞った微調整が、タスク全体で人間の好みと自動評価にどのように影響するか。
- RQ5大規模言語モデルの事前学習、微調整、提供をコスト効率良く実現するインフラと最適化技術は何か。
主な発見
| Model | Size | MMLU | BBH | C-Eval | CMMLU | Gaokao | CR | RC | Code | Math |
|---|---|---|---|---|---|---|---|---|---|---|
| Yi | 6B | 63.2 | 42.8 | 72.0 | 75.5 | 72.2 | 72.2 | 68.7 | 21.1 | 18.6 |
| Yi | 34B | 76.3 | 54.3 | 81.4 | 83.7 | 82.8 | 80.7 | 76.5 | 32.1 | 40.8 |
- Yi-34Bは多くのベンチマークでGPT-3.5と同等の性能を達成し、評価時に強い人間の嗜好信号を提供する。
- Yi-34Bは長文コンテキスト訓練と量子化後も最小限の性能低下で200Kの文脈長を達成。
- 8ビットKVキャッシュ付き4ビット量子化は、MMLU/CMMLUなどのベンチマークで大きな精度低下なく顕著なメモリ節約をもたらす。
- インコンテキスト学習の実験では、より大きなスケールで現れる新たな能力が示唆され、Yi-34Bは多パラメータ推論タスクで強い性能を示す。
- 視覚言語拡張は視覚表現を言語意味空間に整合させ、マルチモーダル機能を可能にする。
- Yi-34B-Chatは自動評価と人間評価の両方で強い結果を示し、特に数学関連・コード様のタスクで小規模ベースラインと比較して顕著。
![Figure 2: Yi’s pre-training data mixture. Overall our data consist of 3.1T high-quality tokens in Both English and Chinese, and come from various sources. Our major differences from existing known mixtures like LLaMA [ 76 ] and Falcon [ 56 ] are that we are bilingual, and of higher quality due to ou](https://ar5iv.labs.arxiv.org/html/2403.04652/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。