[論文レビュー] ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Image
ZeroNVS は diverse real-world scene data 上で 3D-aware diffusion model を訓練し、1 枚の画像から 360 度の新規ビューを合成します。カメラ conditioning と SDS anchoring を導入し、DTU および Mip-NeRF 360 ベンチマークでゼロショット性能を最先端へ。
We introduce a 3D-aware diffusion model, ZeroNVS, for single-image novel view synthesis for in-the-wild scenes. While existing methods are designed for single objects with masked backgrounds, we propose new techniques to address challenges introduced by in-the-wild multi-object scenes with complex backgrounds. Specifically, we train a generative prior on a mixture of data sources that capture object-centric, indoor, and outdoor scenes. To address issues from data mixture such as depth-scale ambiguity, we propose a novel camera conditioning parameterization and normalization scheme. Further, we observe that Score Distillation Sampling (SDS) tends to truncate the distribution of complex backgrounds during distillation of 360-degree scenes, and propose "SDS anchoring" to improve the diversity of synthesized novel views. Our model sets a new state-of-the-art result in LPIPS on the DTU dataset in the zero-shot setting, even outperforming methods specifically trained on DTU. We further adapt the challenging Mip-NeRF 360 dataset as a new benchmark for single-image novel view synthesis, and demonstrate strong performance in this setting. Our code and data are at http://kylesargent.github.io/zeronvs/
研究の動機と目的
- 野外シーンで複数オブジェクトと複雑な背景を持つゼロショットの 360 度新規ビュー合成に対処する。
- 多様な幾何学と背景に対応するため、実データセットの大規模ミックス(CO3D, RealEstate10K, ACID)で訓練された拡散ベースの prior を開発する。
- スケールの曖昧さを解消し3Dの一貫性を高めるため、頑健なカメラ conditioning スキームとシーン正規化を作成する。
- SDS アンカリングを用いて多様で妥当な背景を促進するため、SDS に基づく蒸留における背景多様性の損失を緩和する。
- 強力なゼロショット一般化を実証し、シーンレベルの単一画像 NVS の新しいベンチマーク(Mip-NeRF 360)を確立する。
提案手法
- 1 枚の画像から 3D 一貫性のある新規ビューを得るため、2D 条件付き拡散モデルを訓練し、続いて 3D SDS 蒸留を適用する。
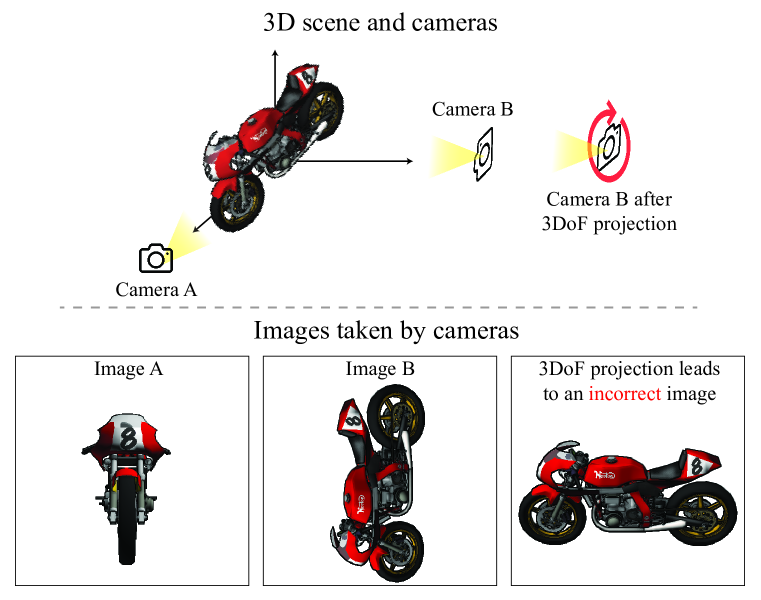
- 6DoF+1 カメラ conditioning 表現(視野角を含む相対姿勢)と viewer-centric 正規化スキームを導入し、野外データ全体のスケールと姿勢の変動に対処する。
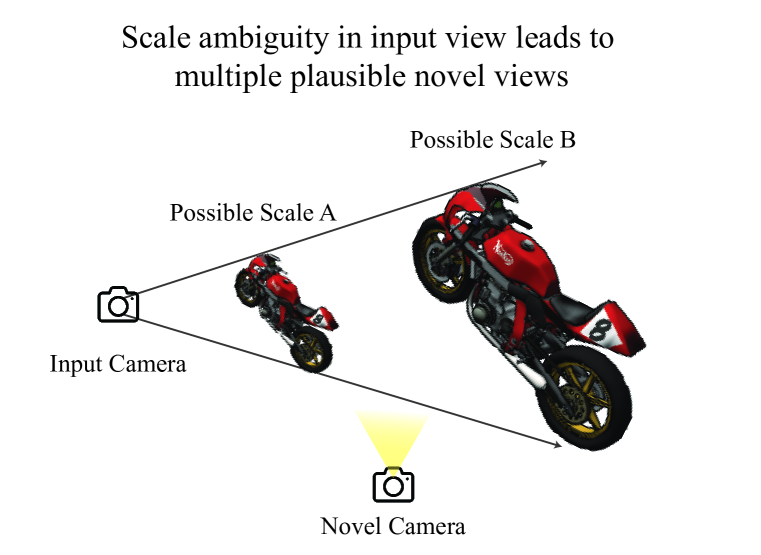
- 深度統計からのシーンスケールパラメータ q を用いてカメラ平移を正規化し、スケールの曖昧さを低減する。
- 新規正規化手法 6DoF+1, viewer を用い、訓練時の一貫したスケール推定のために 深度補填済み密マップを適用してデータセット間で conditioning を統一する。
- SDS アンカリングを提案:DDIM で複数のアンカー視点をサンプリングし、SDS 最適化中に最も近いアンカーを条件付けとして使用して背景多様性を高める。
- DTU で LPIPS、PSNR、SSIM によりゼロショット評価を行い、Mip-NeRF 360 を新しいゼロショットのシーンレベル NVS ベンチマークとして導入する。
実験結果
リサーチクエスチョン
- RQ1多様な実景で訓練された拡散ベース priors が、単一画像からのゼロショットの 360 度新規ビュー合成をどのように可能にするか?
- RQ2野外シーンにおけるスケールと姿勢の曖昧さに最も適切に対処するカメラ conditioning および正規化戦略は何か?
- RQ33D の一貫性を犠牲にすることなく、SDS ベースの蒸留でシーンレベルNVSの背景多様性を高めることができるか?
主な発見
| データセット / 手法 | LPIPS ↓ | PSNR ↑ | SSIM ↑ |
|---|---|---|---|
| DS-NeRF (Deng et al., 2022b) | 0.649 | 12.17 | 0.410 |
| PixelNeRF (Yu et al., 2021) | 0.535 | 15.55 | 0.537 |
| SinNeRF (Xu et al., 2022) | 0.525 | 16.52 | 0.560 |
| DietNeRF (Jain et al., 2021) | 0.487 | 14.24 | 0.481 |
| NeRDi (Deng et al., 2022a) | 0.421 | 14.47 | 0.465 |
| ZeroNVS (ours) | 0.380 | 13.55 | 0.469 |
- ZeroNVS は DTU でゼロショット設定において最先端の LPIPS を達成し、DTU で訓練された手法を上回る。
- Mip-NeRF 360 では、ゼロショットのベースラインの中で最高の LPIPS を達成。
- 深度情報を用いたスケール正規化を伴う viewer-centric 6DoF+1 conditioning は、2D-to-3D の conditioning と多様なデータセット(CO3D, ACID, RealEstate10K)での一般化を向上させる。
- SDS アンカリングは背景の多様性を高め、現実感と創造性の点でユーザ調査で好まれる。
- アブレーションにより、CO3D、ACID、RealEstate10K の混合で訓練すると、評価されたデータセット全体で性能が向上することが示された。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。