QUICK REVIEW
[論文レビュー] ZeroShotDataAug: Generating and Augmenting Training Data with ChatGPT
Solomon Ubani, Suleyman Olcay Polat|arXiv (Cornell University)|Apr 27, 2023
Topic Modeling被引用数 19
ひとこと要約
この論文は、ChatGPTのゼロショット prompting が SST-2, SNIPS, TREC で従来のデータ拡張法を上回る効果的な合成訓練データを生成できることを示し、few-shot ChatGPT との比較も示す。
ABSTRACT
In this paper, we investigate the use of data obtained from prompting a large generative language model, ChatGPT, to generate synthetic training data with the aim of augmenting data in low resource scenarios. We show that with appropriate task-specific ChatGPT prompts, we outperform the most popular existing approaches for such data augmentation. Furthermore, we investigate methodologies for evaluating the similarity of the augmented data generated from ChatGPT with the aim of validating and assessing the quality of the data generated.
研究の動機と目的
- プロンプトを用いた大規模言語モデル(ChatGPT)への入力による低リソース NLP タスクのデータ拡張を動機づける。
- 複数データセットにわたり確立されたベースラインと比較してゼロショット ChatGPT データ拡張を評価する。
- ChatGPT が生成したデータと元データとの類似性を測定する方法を提案・評価して品質を検証する。
- 拡張データ量が性能に与える影響を定量化し、訓練データなしでデータの十分性を探索する。
提案手法
- EDA、Back-Translation、Transformer ベースの拡張ベースラインとゼロショット ChatGPT 拡張を比較する。
- 低リソース設定(各クラス10の例)で3つのデータセット(SST-2、SNIPS、TREC)を使用する。
- ChatGPT のタスク特化型ゼロショット・プロンプトを用いて合成データを生成し、15 回の実行で評価する。
- 拡張データで BERT-base-uncased をファインチューニングし、精度と標準偏差を報告する。
- Sentence Embedding (MiniLM)、TF-IDF、Word Overlap 指標を用いてデータ汚染と類似性を評価する。
- 拡張数を変えて性能傾向を研究する。
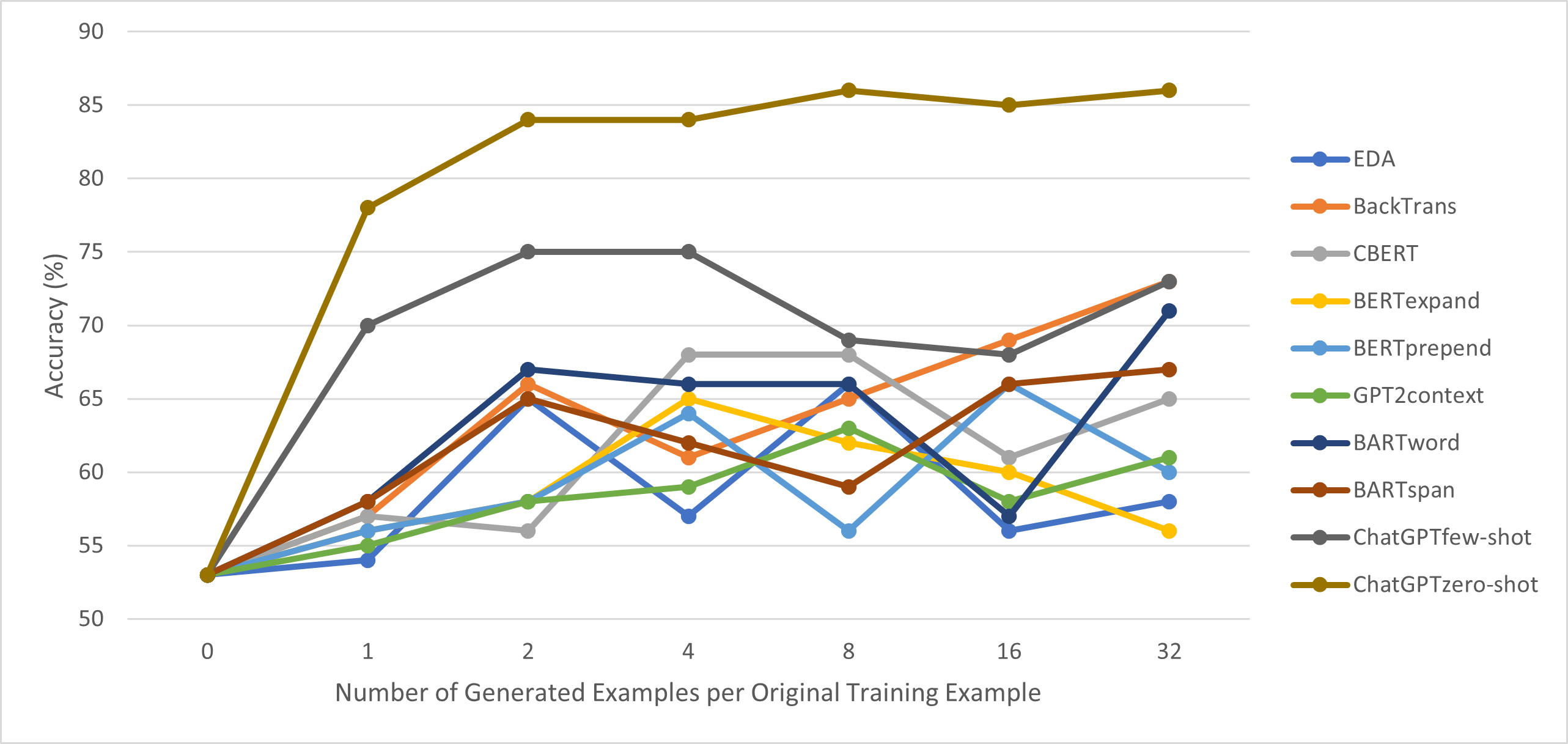
実験結果
リサーチクエスチョン
- RQ1従来の手法と比較して、テキスト分類タスクにおけるデータ拡張のためのゼロショット ChatGPT prompting はどれくらい効果的か?
- RQ2低リソース設定での ChatGPT 生成データ量がモデル性能に与える影響は?
- RQ3ChatGPT 生成データと実データの類似性を信頼できる方法で評価し、記憶または汚染を排除できるか?
- RQ4元データなしでもゼロショット ChatGPT 拡張は他の手法を上回ることができるか?
主な発見
| モデル | SST-2 | SNIPS | TREC |
|---|---|---|---|
| No Aug | 52.9 (5.0) | 79.4 (3.2) | 48.6 (11.5) |
| EDA | 53.8 (4.4) | 85.8 (3.0) | 52.6 (10.5) |
| BackTrans. | 57.5 (5.6) | 86.5 (2.4) | 66.2 (8.5) |
| CBERT | 57.4 (6.7) | 85.8 (3.5) | 64.3 (10.9) |
| BERTexpand | 56.3 (6.5) | 86.1 (2.7) | 65.3 (6.1) |
| BERTprepend | 56.1 (6.3) | 86.8 (1.6) | 64.7 (9.6) |
| GPT2context | 55.4 (6.7) | 86.6 (2.7) | 54.3 (10.1) |
| BARTword | 58.0 (6.8) | 86.8 (2.6) | 63.7 (9.8) |
| BARTspan | 57.7 (7.1) | 87.2 (1.4) | 67.3 (6.1) |
| ChatGPTfew-shot | 69.6 (5.8) | 91.3 (1.4) | 66.7 (8.0) |
| ChatGPTzero-shot | 78.1 (5.1) | 91.2 (1.3) | 75.3 (4.0) |
- ゼロショット ChatGPT 拡張は SST-2: 78.1%、 SNIPS: 91.2%、 TREC: 75.3% の精度を達成し、SNIPS では few-shot ChatGPT を除くすべてのベースラインを上回る。
- SST-2 と TREC ではゼロショット ChatGPT が最良の非 ChatGPT 拡張をそれぞれ20%、8%上回り、SNIPS では4%上回る。
- 原データ1件あたりの ChatGPT 生成拡張例数を増やすと性能向上が続く(K ∈ {1,2,4,8,16,32})。
- 元データの訓練データが全くなくても、ChatGPT のゼロショット拡張は SST-2 の平均精度 0.80、 SNIPS 0.78、 TREC 0.62 を示し、SST-2 で既存手法に匹敵またはそれを超え、TREC でほぼ最高。
- 類似性分析(Cosine Sentence Embedding、Cosine TF-IDF、Word Overlap)では、ChatGPT 生成データ由来のデータの記憶または汚染の証拠は少ない。
- データ類似性結果は、ChatGPT 生成データが訓練データよりもテストデータに対して平均的にやや類似しており、記憶より一般化を示唆。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。