[논문 리뷰] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
논문은 이미지 패치를 시퀀스로 다루는 순수 Transformer(비전 트랜스포머, ViT)가 대규모로 트레이닝될 때 CNN 기반 방법과 다수의 이미지 인식 벤치마크에서 대응하거나 이를 능가할 수 있음을 보여주며, 강력한 전이 성능을 제공합니다.
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
연구 동기 및 목표
- CNN의 유도 편향 없이 표준 트랜스포머를 이미지에 직접 적용하는 것을 고무한다.
- ViT의 대규모 이미지 데이터셋에 대한 확장 가능한 사전 학습과 다양한 벤치마크로의 전이를 입증한다.
- 다양한 데이터 및 컴퓨트 예산 하에서 ViT를 CNN 기본선 및 하이브리드와 비교한다.
- 사전 학습 데이터 크기와 계산량이 ViT 성능에 미치는 영향을 분석한다.
- 학습된 표현 및 어텐션 패턴에 대한 정성적 인사이트를 탐구한다.
제안 방법
- 고정 크기의 패치로 이미지를 분할하고 이를 공유 차원으로 선형 투영한다.
- 학습 가능한 분류 토큰을 맨 앞으로 추가하고 1D 위치 임베딩을 더해 토큰 시퀀스를 형성한다.
- 레이어 정규화와 잔여 연결이 있는 표준 Transformer 인코더(MSA + MLP 블록)로 패치 임베딩을 처리한다.
- 다운스트림 작업에서 분류 헤드를 사용해 미세 조정하거나 학습한다; 필요에 따라 2D 위치 임베딩 보간으로 이미지 해상도를 조정한다.
- 필요에 따라 원시 패치 대신 CNN 피처 맵이 패치 시퀀스를 형성하는 하이브리드 입력을 사용할 수 있다.
- 대규모 데이터셋(ImageNet, ImageNet-21k, JFT-300M)에서 비전 트랜스포머 변형(Base, Large, Huge)을 학습하고 벤치마크로 전이한다; ResNet 기본선 및 Noisy Student와 비교한다.
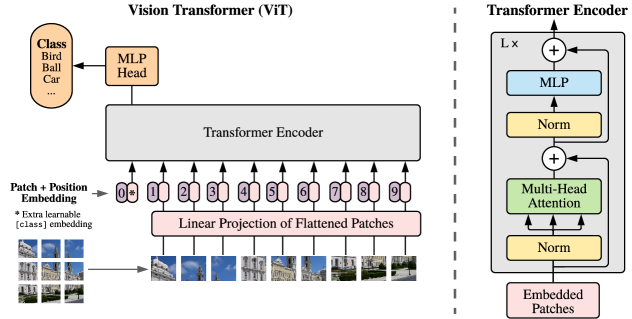
실험 결과
연구 질문
- RQ1CNN 특유의 유도 편향 없이 이미지 패치 시퀀스에 직접 적용된 일반적인 Transformer가 경쟁력 있는 이미지 분류 성능을 달성할 수 있는가?
- RQ2사전 학습 데이터의 규모와 계산량이 ViT의 다양한 벤치마크에서의 전이 성능에 어떤 영향을 미치는가?
- RQ3정확도와 학습 비용 측면에서 순수 ViT, 하이브리드, CNN 기본선 간의 트레이드오프는 무엇인가?
- RQ4어텐션 패턴과 학습된 임베딩이 ViT가 이미지 구조를 다루는 방식에 대해 어떤 통찰을 제공하는가?
주요 결과
| 데이터세트 | Ours-JFT (ViT-H/14) | Ours-JFT (ViT-L/16) | Ours-I21k (ViT-L/16) | BiT-L (ResNet152x4) | Noisy Student (EfficientNet-L2) |
|---|---|---|---|---|---|
| ImageNet | 88.55 | 87.76 | 85.30 | 87.54 | 88.4/88.5 |
| ImageNet ReaL | 90.72 | 90.54 | 88.62 | 90.54 | 90.55 |
| CIFAR-10 | 99.50 | 99.42 | 99.15 | 99.37 | - |
| CIFAR-100 | 94.55 | 93.90 | 93.25 | 93.51 | - |
| Oxford-IIIT Pets | 97.56 | 97.32 | 94.67 | 96.62 | - |
| Oxford Flowers-102 | 99.68 | 99.74 | 99.61 | 99.63 | - |
| VTAB (19 tasks) | 77.63 | 76.28 | 72.72 | 76.29 | - |
- 비전 트랜스포머는 대규모로 사전 학습할 때 강력한 전이 성능을 달성해 여러 데이터셋에서 최첨단 CNN에 근접하거나 이를 능가한다.
- ViT 모델은 JFT-300M에서 사전 학습된 경우 보고된 모든 데이터셋에서 CNN 기본선보다 우수하고 사전 학습에 필요한 계산이 크게 적다; ImageNet-21k에서 사전 학습된 ViT-L/16도 좋은 성능을 보인다.
- ImageNet에서 ViT-H/14는 88.55% top-1 정확도에 도달; ImageNet-ReaL에서 90.72%; CIFAR-100 94.55%; VTAB 77.63% (19개 작업).
- ViT-H/14 및 ViT-L/16은 유사한 계산 하에서 BiT-L 및 Noisy Student 기본선에 비해 우수한 성능을 보이며, 더 큰 모델이 결과를 더 향상시킨다.
- 사전 학습 데이터 규모가 중요하다: ViT는 매우 큰 데이터세트(JFT-300M)에서 크게 이익을 얻지만, 더 작은 데이터로는 CNN이 더 잘할 수 있으며, 충분한 데이터로 ViT가 따라잡고 이를 넘어선다.
- 자기지도 사전 학습은 ViT에 가능성을 보이며, 패치 예측 마스크 학습이 처음부터 학습하는 것보다 측정 가능한 이점을 제공한다(예: ViT-B/16의 ImageNet에서 79.9%).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.