[논문 리뷰] Deep Multi-agent Reinforcement Learning for Highway On-Ramp Merging in Mixed Traffic
본 논문은 혼합 교통에서 고속도로 진입로 합류를 분산형 다중 에이전트 강화학습 문제로 공식화하고, 액션 마스킹, 우선 순위 기반 안전 감독자, 커리큘럼 학습이 포함된 확장 가능한 MARL 프레임워크를 도입하여 벤치마크 대비 안전성과 효율성을 우수하게 달성한다.
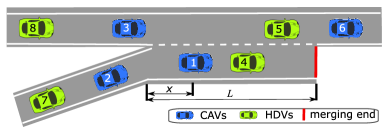
On-ramp merging is a challenging task for autonomous vehicles (AVs), especially in mixed traffic where AVs coexist with human-driven vehicles (HDVs). In this paper, we formulate the mixed-traffic highway on-ramp merging problem as a multi-agent reinforcement learning (MARL) problem, where the AVs (on both merge lane and through lane) collaboratively learn a policy to adapt to HDVs to maximize the traffic throughput. We develop an efficient and scalable MARL framework that can be used in dynamic traffic where the communication topology could be time-varying. Parameter sharing and local rewards are exploited to foster inter-agent cooperation while achieving great scalability. An action masking scheme is employed to improve learning efficiency by filtering out invalid/unsafe actions at each step. In addition, a novel priority-based safety supervisor is developed to significantly reduce collision rate and greatly expedite the training process. A gym-like simulation environment is developed and open-sourced with three different levels of traffic densities. We exploit curriculum learning to efficiently learn harder tasks from trained models under simpler settings. Comprehensive experimental results show the proposed MARL framework consistently outperforms several state-of-the-art benchmarks.
연구 동기 및 목표
- 혼합 교통의 온-램프 진입 합류 문제를 분산형 MARL 문제로 공식화한다.
- 협력을 위한 매개변수 공유 및 지역 보상을 가진 확장 가능한 MARL 프레임워크를 개발한다.
- 액션 마스킹과 우선순위 기반 안전 감독자를 통해 학습 효율성과 안전성을 향상시킨다.
- 더 어려운 합류 시나리오를 효율적으로 마스터하기 위한 커리큘럼 학습을 도입한다.
- 오픈 소스 gym 유사 시뮬레이터를 제공하고 벤치마크보다 우수한 성능을 입증한다.
제안 방법
- 온-램프 합류 시나리오를 AV를 에이전트로 하는 부분 관찰 가능 MARL 문제로 모델링한다.
- 가변 에이전트 수와 동형 정책에 대한 확장성을 가능하게 하려 매개변수 공유를 사용한다.
- 로컬 보상 설계를 도입하여 크레딧 어사인먼트를 다루고 이웃 차량 간의 협력을 촉진한다.
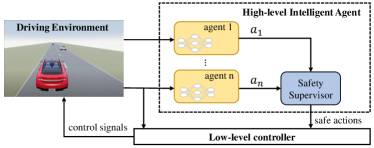
- 유효하지 않은 행동을 제외하기 위해 액션 마스킹을 적용하고 학습 안정성을 높인다.
- 다중 단계 예측(IDM/MOBIL HDV 모델)을 사용하는 우선순위 기반 안전 감독자를 도입하여 충돌을 방지한다.
- 운동학적 자전거 모델과 저수준 PID 제어기를 이용해 고수준 MARL 행동을 구현한다.
실험 결과
연구 질문
- RQ1매개변수 공유를 갖는 분산형 MARL 프레임워크가 혼합 교통에서 안전하고 효율적인 고속도로 진입로 합류를 달성할 수 있는가?
- RQ2액션 마스킹과 우선순위 기반 안전 감독자가 기준 MARL 방법에 비해 학습 효율성을 높이고 충돌을 감소시키는가?
- RQ3더 어려운 합류 시나리오에서 커리큘럼 학습이 학습 효율성과 성능에 어떤 영향을 미치는가?
- RQ4제안된 프레임워크가 동적 토폴로지와 가변 수의 AV에 대해 확장 가능한가?
- RQ5로컬 보상 설계가 크레딧 어사인먼트와 협력 행동에 미치는 영향은 무엇인가?
주요 결과
- 액션 마스킹과 우선순위 기반 안전 감독자가 있는 제안된 MARL 프레임워크는 실험 전반에서 안전성 및 효율성 면에서 여러 최신 벤치마크를 능가한다.
- 로컬 보상 설계가 크레딧 어사인먼트 문제를 완화하고 이웃 차량 간의 협력을 향상시킨다.
- 커리큘럼 학습은 더 간단한 작업을 기반으로 하여 더 어려운 합류 작업의 효율적 숙달을 가능하게 한다.
- 안전 감독자는 학습 중 충돌률을 감소시키고 학습을 가속화하며 실제 실시간 가능성(대략 28 ms당 결정)도 확보한다.
- 프레임워크는 동적 통신 토폴로지를 지원하고 AV 수에 따라 확장되며, 매개변수 공유를 사용해 에이전트 간 하나의 정책을 유지한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.