[논문 리뷰] REFINER: Reasoning Feedback on Intermediate Representations
REFINER는 생성기가 중간 추론 단계를 산출하고 평가자가 세밀한 피드백을 제공하도록 하여 수학 단어 문제, 합성 자연어 추론, 도덕 이야기 생성 등 다양한 추론 태스크에서 추론을 개선합니다.
Language models (LMs) have recently shown remarkable performance on reasoning tasks by explicitly generating intermediate inferences, e.g., chain-of-thought prompting. However, these intermediate inference steps may be inappropriate deductions from the initial context and lead to incorrect final predictions. Here we introduce REFINER, a framework for finetuning LMs to explicitly generate intermediate reasoning steps while interacting with a critic model that provides automated feedback on the reasoning. Specifically, the critic provides structured feedback that the reasoning LM uses to iteratively improve its intermediate arguments. Empirical evaluations of REFINER on three diverse reasoning tasks show significant improvements over baseline LMs of comparable scale. Furthermore, when using GPT-3.5 or ChatGPT as the reasoner, the trained critic significantly improves reasoning without finetuning the reasoner. Finally, our critic model is trained without expensive human-in-the-loop data but can be substituted with humans at inference time.
연구 동기 및 목표
- 언어 모델에서 중간 추론 단계를 명시적으로 생성하도록 동기를 부여하고 잘못된 추론을 완화합니다.
- 중간 표현에 대해 미세한 피드백을 제공하는 생성기와 평가자 간의 상호작용 루프를 제안합니다.
- 구조화된 피드백이 다중 태스크와 다양한 모델 스케일에서 추론을 개선하는지 보여줍니다.
- 훈련된 평가자가 GPT-3.5 및 ChatGPT와 같은 외부 LLM의 추론도 향상시킬 수 있음을 시연합니다.
- 피드백의 역할, 평가자 품질, 추론 시 사용에 대한 분석 및 구성 요소의 아블레이션(ablations)을 제공합니다.
제안 방법
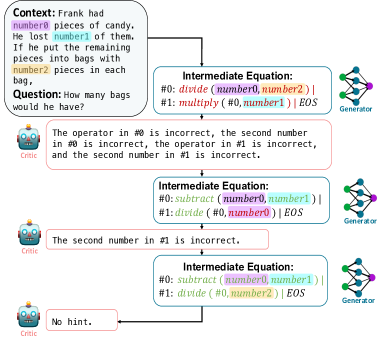
- 생성기와 평가자로 구성된 Two-model REFINER 프레임워크.
- 추론 오류를 설명하는 자동으로 구성된 미세한 피드백 데이터로 평가자 학습.
- 생성기는 중간 표현 생성을 미세하게 조정하고 평가자 피드백으로 정제합니다.
- 피드백은 오류 유형 템플릿에서 파생된 반구조화된 텍스트를 자연어로 변환한 것입니다.
- 다양한 피드백에 노출되도록 상승분포 탐색(nucleus sampling)을 통한 학습 중 탐색.
- 추론 단계에서 평가자를 이용해 생성기의 중간 단계를 가이드하거나 수정합니다.
실험 결과
연구 질문
- RQ1중간 추론 단계에 대한 미세하고 구조화된 피드백이 스칼라 보상보다 최종 태스크 성능을 향상시키는가?
- RQ2태스크 특화된 평가자가 중간 표현과 최종 답변을 다양한 추론 태스크에서 향상시키는가?
- RQ3훈련 없이 외부 LLM(GPT-3.5, ChatGPT)의 성능 향상에 훈련된 평가자가 도움을 주는가?
- RQ4REFINER가 자기 수정(self-refine)이나 자기 일관성(self-consistency) 같은 다른 정제 방법과 비교해 어떻게 성능이 다른가?
- RQ5불완전한(노이즈가 있는) 평가자나 추론 시 사용에 대해 REFINER의 이점은 얼마나 견고한가?
주요 결과
| 모델 | IR (z) | 답( y ) |
|---|---|---|
| UQA-base | 34.1 | – |
| UQA-base + PPO | 31.5 | – |
| REFINER base | 47.2 | – |
| UQA-large | 46.7 | – |
| UQA-large + PPO | 48.2 | – |
| REFINER large | 53.8 | – |
| GPT-3.5 + CoT | 64.1 | 67.1 |
| GPT-3.5 + CoT + REFINER critic | 67.3 | 70.6 |
- REFINER는 수학 단어 문제, 합성 자연어 추론, 도덕 이야기 생성에서 동등한 크기의 기준선 대비 유의한 이득을 제공합니다.
- MWP에서 IR(z)는 REFINER 기본 구성으로 47.2에서 53.8로 향상되며, GPT-3.5 + CoT + REFINER 평가자는 67.3 IR 및 70.6 최종 정확도로 도달합니다.
- sNLR에서 REFINER는 IR을 46.7의 기준에서 53.8로, 최종 답변 정확도를 53.8로 향상시키며(표에 IR=53.8, Con=?) 대형 모델에서 +2.9 EM, GPT-3.5 대비 +6.8 EM의 이득을 보여줍니다.
- MS에서 REFINER는 UQA-대형 기준선 대비 도덕적 규범 및 행동 관련성 측면에서 약 20포인트 향상을 보이며 크리포덴드로프의 α 값으로 더 높은 합의도를 보여줍니다.
- REFINER의 훈련된 평가자만으로도 GPT-3.5의 적은 샘플 추론을 주목할 만한 마진으로 향상시킵니다(+3.5, +6.8) MW P와 sNLR에서 각각.
- REFINER는 자기 수정 방식(Self-refinement) 대비 더 나은 성능을 보이며, 연결된(CoT 기반) 방법들과 함께 사용할 때도 성능을 개선합니다(자기 일관성, ReACT 등).
- 아블레이션 연구는 추론 시 평가자 피드백의 중요성과 탐색 단계의 중요성을 보여주며, 불완전한 평가자도 이득을 주는 반면 노이즈가 큰 평가자는 성능을 해칠 수 있습니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.