[논문 리뷰] Robust instrumental variable methods using multiple candidate instruments with application to Mendelian randomization
이 논문은 다수의 후보 유전적 도구변수를 사용하는 메디컬 랜덤라이제이션에서 강건한 도구변수 방법을 평가하며, 강건한 회귀, 가중치 페널티, L1 페널티와 같은 확장 방법을 제안하고 시험한다. 연구 결과, 강건한 회귀와 단순 중앙값 추정이 최대 30%의 도구변수가 비효율적일 경우에도 정확한 제1종 오류 비율(약 5%)을 유지함을 발견하였으며, 이는 이질성 하에서 전통적 방법과 MR-Egger 방법보다 뛰어난 성능을 보였다.
Mendelian randomization is the use of genetic variants to make causal inferences from observational data. The field is currently undergoing a revolution fuelled by increasing numbers of genetic variants demonstrated to be associated with exposures in genome-wide association studies, and the public availability of summarized data on genetic associations with exposures and outcomes from large consortia. A Mendelian randomization analysis with many genetic variants can be performed relatively simply using summarized data. However, a causal interpretation is only assured if each genetic variant satisfies the assumptions of an instrumental variable. To provide some protection against failure of these assumptions, robust methods for instrumental variable analysis have been proposed. Here, we develop three extensions to instrumental variable methods using: i) robust regression, ii) the penalization of weights from candidate instruments with heterogeneous causal estimates, and iii) L1 penalization. Results from a wide variety of robust methods, including the recently-proposed MR-Egger and median-based methods, are compared in an extensive simulation study. We demonstrate that two methods, robust regression in an inverse-variance weighted method and a simple median of the causal estimates from the individual variants, have considerably improved Type 1 error rates compared with conventional methods in a wide variety of scenarios when up to 30% of the genetic variants are invalid instruments. While the MR-Egger method gives unbiased estimates when its assumptions are satisfied, these estimates are less efficient than those from other methods and are highly sensitive to violations of the assumptions. Methods that make different assumptions should be used routinely to assess the robustness of findings from applied Mendelian randomization investigations with multiple genetic variants.
연구 동기 및 목표
- 다수의 유전자 변이를 사용할 경우 비효율적 도구변수의 위험을 다루기 위해.
- 도구변수의 유효성과 이질성의 다양한 시나리오 하에서 강건한 도구변수 방법의 성능을 평가하기 위해.
- 최근 제안된 페널티 및 강건한 회귀를 사용한 확장 방법과 기존의 MR-Egger 및 중앙값 기반 방법을 비교하기 위해.
- 도구변수 가정 위반 시 통계적 타당성을 유지하는 방법 선택에 실용적 지침을 제공하기 위해.
- 대규모 콈터니아에서의 요약 유전 데이터를 사용하여 이러한 방법의 효과성을 평가하여 관찰 연구에서 널리 적용 가능하게 하기 위해.
제안 방법
- 후보 도구변수에 대해 가중치를 페널티 처리한 역분산가중 평균 방법을 사용하여 강건한 회귀를 적용해 인과 효과를 추정한다.
- 이질적인 인과 추정을 생성하는 도구변수의 가중치를 페널티 처리하여 잠재적으로 비효율적인 도구변수의 영향을 감소시킨다.
- L1 페널티(라소 유형)를 사용해 일致한 인과 추정을 보이는 도구변수의 부분집합을 선택함으로써 효율성과 강건성을 향상시킨다.
- 대규모 유전자 콈터니아에서의 요약 데이터(베타계수 및 표준오차)를 사용하는 이중표본 메디컬 랜덤라이제이션 프레임워크를 적용한다.
- 다양한 비율의 비효율적 도구변수(0–30%)와 다양한 인과 효과 크기 하에서 광범위한 시뮬레이션 연구를 수행하여 방법을 비교한다.
- 다양한 시뮬레이션 시나리오에서 제1종 오류 비율, 검정력, 편향, 평균제곱오차를 사용해 성능을 평가한다.
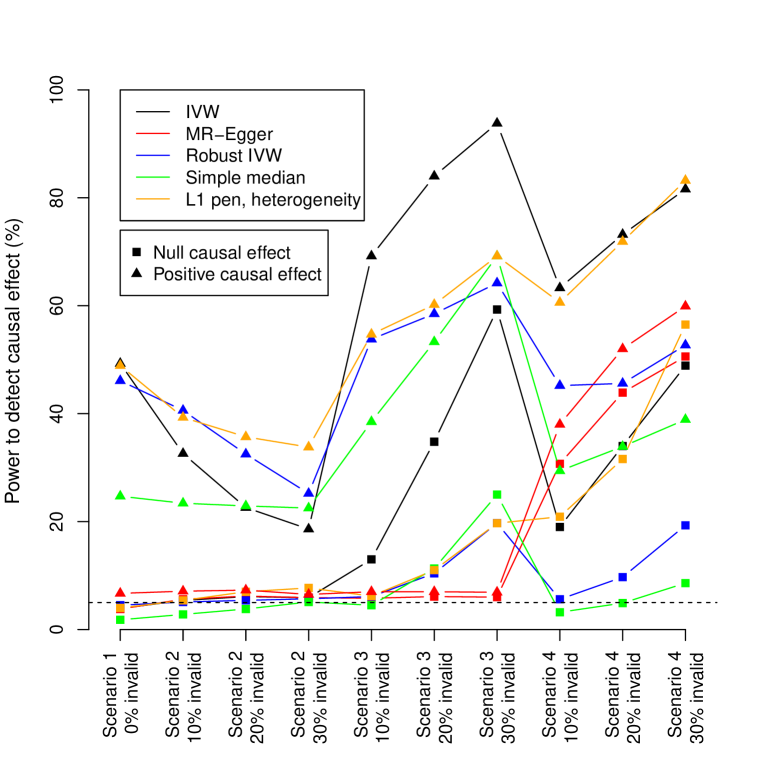
실험 결과
연구 질문
- RQ1최대 30%의 후보 도구변수가 비효율적일 경우 강건한 도구변수 방법은 어떻게 성능을 보이는가?
- RQ2도구변수 가정 위반 상황에서 어떤 방법이 적절한 제1종 오류 비율을 유지하는가?
- RQ3MR-Egger 방법은 단순 중앙값 기반 및 강건한 회귀 방법과 비교해 편향과 효율성 측면에서 어떻게 성능을 보이는가?
- RQ4이질적이거나 비효율적인 도구변수 존재 시 페널티 기법이 인과 추정의 신뢰성을 향상시킬 수 있는가?
- RQ5실제 메디컬 랜덤라이제이션 적용에서 강건성, 효율성, 정확성의 최적의 균형을 제공하는 방법은 무엇인가?
주요 결과
- 역분산가중 프레임워크 내 강건한 회귀는 최대 30%의 도구변수가 비효율적일 경우에도 정확한 제1종 오류 비율(약 5%)을 유지한다.
- 개별 변이의 인과 추정치 중앙값은 전통적 방법과 비교해 특히 높은 비효율적 도구변수 비율 하에서 뛰어난 제1종 오류 통제 성능(시뮬레이션에서 3.0–8.4%)을 보인다.
- MR-Egger는 가정이 충족될 경우 편향 없는 추정치를 제공하지만, 높은 제1종 오류 비율(최대 20%)과 낮은 효율성으로 인해 실무에서 신뢰도가 떨어진다.
- 도구변수의 이질성이 존재할 경우, 가중치 페널티 또는 L1 페널티 기법을 적용한 방법이 표준 역분산가중 평균 방법보다 향상된 성능을 보인다.
- 가중치 중앙값 방법은 중간 수준의 성능을 보이지만, 제1종 오류 비율이 높고(최대 11.0%), 강건한 회귀 및 중앙값 기반 방법보다 검정력이 낮다.
- 양의 인과 효과가 존재하는 시나리오(θ = 0.1)에서, 강건한 회귀 및 중앙값 기반 방법은 비효율적 도구변수 조건 하에서도 전통적 방법보다 높은 통계적 검정력(25–37%)을 유지한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.