[논문 리뷰] Simple random search provides a competitive approach to reinforcement learning
저자들은 선형 정책의 매개변수 공간에서의 간단한 augmentation된 무작위 탐색이 MuJoCo 보행 태스크에서 상태-최신 샘플 효율성을 달성하거나 이를 능가할 수 있으며, Evolution Strategies보다 계산 효율성이 현저히 높다. 또한 RL 벤치마크에서 시드 및 하이퍼파라미터 간의 큰 분산을 강조한다.
A common belief in model-free reinforcement learning is that methods based on random search in the parameter space of policies exhibit significantly worse sample complexity than those that explore the space of actions. We dispel such beliefs by introducing a random search method for training static, linear policies for continuous control problems, matching state-of-the-art sample efficiency on the benchmark MuJoCo locomotion tasks. Our method also finds a nearly optimal controller for a challenging instance of the Linear Quadratic Regulator, a classical problem in control theory, when the dynamics are not known. Computationally, our random search algorithm is at least 15 times more efficient than the fastest competing model-free methods on these benchmarks. We take advantage of this computational efficiency to evaluate the performance of our method over hundreds of random seeds and many different hyperparameter configurations for each benchmark task. Our simulations highlight a high variability in performance in these benchmark tasks, suggesting that commonly used estimations of sample efficiency do not adequately evaluate the performance of RL algorithms.
연구 동기 및 목표
- 모델 프리 RL에서 매개변수 공간의 탐색이 행동 공간 탐색과 같은 효과를 낼 수 있는지 해명한다.
- 미분 없이 계산적으로 효율적인 선형 정책 학습 방법을 개발한다.
- ARS를 표준 MuJoCo 보행 벤치마크와 도전적인 LQR 인스턴스에서 평가하여 시드 전반에 걸친 성능과 강건성을 판단한다.
- RL 벤치마킹 관행에 정보를 제공하기 위해 RL 성능의 변동성을 강조한다.
제안 방법
- RL에서 도함수 없는 최적화를 위한 기본 랜덤 탐색(BRS) 기반선을 제시한다.
- 보상 표준편차로 스케일링, 온라인 상태 정규화, 성능이 좋지 않은 방향 버리기(ARS)로 BRS를 보강한다.
- 상태 정규화 및 위상 선택을 포함하는 V1, V1-t, V2, V2-t의 네 가지 ARS 변형을 도입한다. V2에는 상태 표백이 포함되고 V1/V2-t는 최상 방향 선택을 사용한다.
- 공유 노이즈 표와 독립적인 롤아웃으로 임의 방향으로의 그래디언트를 추정하는 병렬 구현을 사용한다.
- 환경에 대한 롤아웃(쿼리)의 수로 샘플 복잡도를 논의하기 위한 RL용 오라클 모델을 형식화한다.
- MuJoCo 태스크에서 ARS를 NG, TRPO, ES, PPO, A2C, CEM, SAC와 비교하고 샘플 효율성과 월시계 시간을 분석한다.
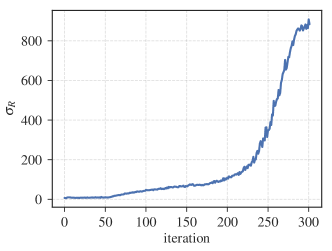
실험 결과
연구 질문
- RQ1정책 매개변수 공간에서의 간단한 랜덤 탐색이 연속 제어 태스크에서 경쟁력 있는 샘플 효율성을 달성할 수 있는가?
- RQ2보상 스케일링, 상태 정규화, 상위 방향 선택과 같은 보강이 ARS 성능을 향상시키는가?
- RQ3MuJoCo 벤치마크에서 ARS가 샘플 효율성과 계산 비용 측면에서 주류 RL 방법들과 어떻게 비교되는가?
- RQ4평가 시드 변동성 및 하이퍼파라미터 민감도가 RL 벤치마킹 관행에 어떤 영향을 미치는가?
- RQ5ARS로 학습된 선형 정책이 어려운 제어 작업과 알려지지 않은 dynamics 문제인 LQR 인스턴스에서 잘 작동하는가?
주요 결과
| 태스크 | 임계값 | ARS V1 | ARS V1-t | ARS V2 | ARS V2-t | NG-lin | NG-rbf | TRPO-nn |
|---|---|---|---|---|---|---|---|---|
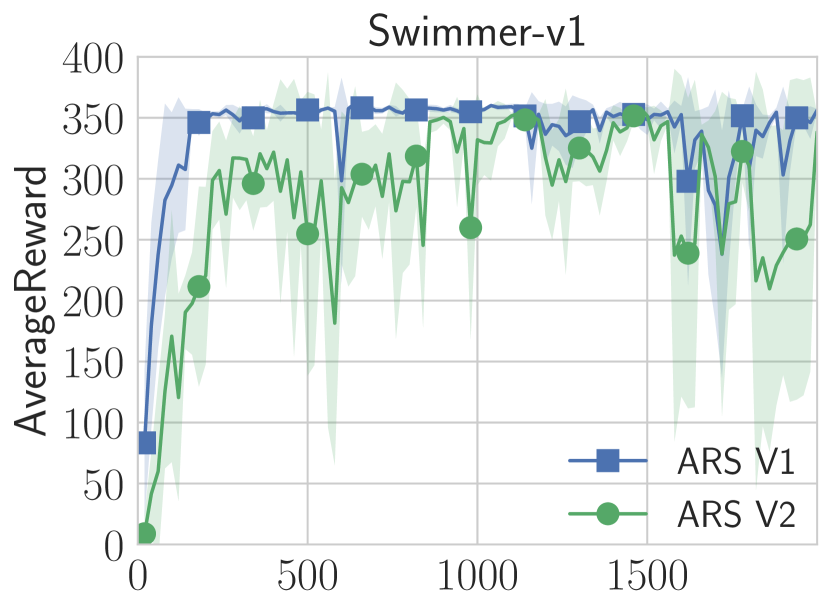
| Swimmer-v1 | 325 | 100 | 100 | 427 | 427 | 1450 | 1550 | N/A |
| Hopper-v1 | 3120 | 89493 | 51840 | 3013 | 1973 | 13920 | 8640 | 10000 |
| HalfCheetah-v1 | 3430 | 10240 | 8106 | 2720 | 1707 | 11250 | 6000 | 4250 |
| Walker2d-v1 | 4390 | 392000 | 166133 | 89600 | 24000 | 36840 | 25680 | 14250 |
| Ant-v1 | 3580 | 101066 | 58133 | 60533 | 20800 | 39240 | 30000 | 73500 |
| Humanoid-v1 | 6000 | N/A | N/A | 142600 | 142600 | ≈130000 | ≈130000 | UNK |
- 선형 정책(신경망 없이)으로 MuJoCo 보행 태스크에서 상태-최신 샘플 효율성에 맞먹거나 이를 초과한다.
- ARS는 Humanoid-v1에서 유사한 성능 임계치에 도달할 때 ES보다 최소 15배 이상 계산 효율적이다.
- ARS는 시드와 하이퍼파라미터 간의 높은 분산을 보여주어 많은 시도와 광범위한 벤치마킹의 필요성을 강조한다.
- ARS V2(상태 정규화/ whitening이 있는)가 Humanoid-v1을 해결하고 V1에 비해 대부분의 MuJoCo 태스크에서 성능을 개선한다.
- ARS는 알려지지 않은 dynamics LQR 문제의 어려운 사례를 거의 최적의 성능으로 해결할 수 있다.
- 다양한 벤치마크 대비 ARS는 일반적으로 샘플 효율이 유리하고 1e6 타임스텝 후에도 최대 보상에서 경쟁력이 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.