[논문 리뷰] Unsupervised Predictive Memory in a Goal-Directed Agent
MERLIN은 비지도 예측 모델링으로 학습된 메모리 기반 예측기를 사용하는 AI 에이전트로, 매우 부분적으로 관찰되는 태스크를 해결하고 심리학/신경과학 벤치마크에서 표준 메모리 RL 에이전트보다 우수합니다. 그것은 간결한 상태 변수들을 만들어 메모리에 저장하고, 리턴 예측을 이용해 표현과 메모리 사용을 형성합니다.
Animals execute goal-directed behaviours despite the limited range and scope of their sensors. To cope, they explore environments and store memories maintaining estimates of important information that is not presently available. Recently, progress has been made with artificial intelligence (AI) agents that learn to perform tasks from sensory input, even at a human level, by merging reinforcement learning (RL) algorithms with deep neural networks, and the excitement surrounding these results has led to the pursuit of related ideas as explanations of non-human animal learning. However, we demonstrate that contemporary RL algorithms struggle to solve simple tasks when enough information is concealed from the sensors of the agent, a property called "partial observability". An obvious requirement for handling partially observed tasks is access to extensive memory, but we show memory is not enough; it is critical that the right information be stored in the right format. We develop a model, the Memory, RL, and Inference Network (MERLIN), in which memory formation is guided by a process of predictive modeling. MERLIN facilitates the solution of tasks in 3D virtual reality environments for which partial observability is severe and memories must be maintained over long durations. Our model demonstrates a single learning agent architecture that can solve canonical behavioural tasks in psychology and neurobiology without strong simplifying assumptions about the dimensionality of sensory input or the duration of experiences.
연구 동기 및 목표
- 중요 정보를 놓치는 센서가 있는 부분 관찰성 하에서 메모리 기반 에이전트를 작동시키도록 동기를 부여한다.
- 관찰을 상태 변수로 압축하고 예측에 사용할 수 있도록 메모리에 저장하는 메모리 기반 예측기 MERLIN을 개발한다.
- 비지도 예측 모델링이 메모리 형성을 이끌고 심리학/신경과학에서 영감을 받은 태스크에서 성능을 향상시킴을 보여준다.
제안 방법
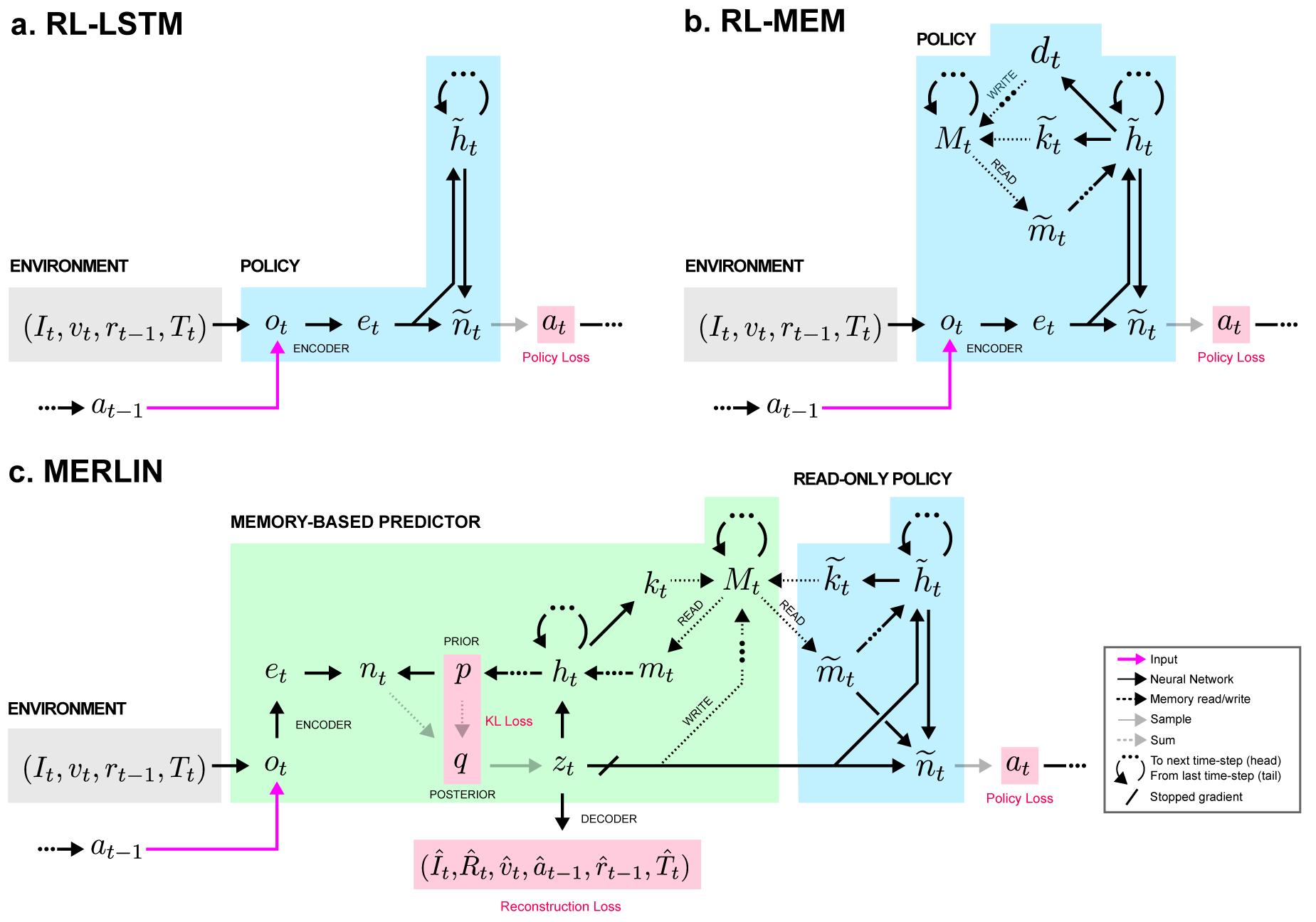
- MERLIN의 도입: 읽기/쓰기 메모리 메커니즘을 가진 정책과 결합된 메모리 기반 예측기(MBP)를 포함하는 에이전트 아키텍처.
- MBP는 다중 모드 관찰을 변분 오토인코더 유사 프레임워크를 통해 저차원 상태 변수 z로 인코딩하고 이를 메모리에 저장한다.
- p(z_t|z_{1:t-1},a_{1:t-1}) 와 q(z_t|z_{1:t-1},a_{1:t-1},o_t)를 사용하여 z_t를 샘플링하고 메모리를 업데이트한다.
- MBP를 다중 모달리티의 재구성 손실과 p와 q 사이의 KL 항으로 구성된 변분 하한(VLB)으로 훈련하고, 보상 관련 정보를 향해 z_t를 이끄는 리턴 예측 디코더를 추가한다.
- 표현학습이 보상만이 아니라 예측 모델링에 의해 이뤄지도록 MBP 최적화를 정책과 분리한다.
- MBP 외에 레트로액티브 메모리 업데이트를 통해 과거 기억에 미래 정보를 붙이고 리턴 예측이 표현을 어떻게 형성하는지 탐색한다.
실험 결과
연구 질문
- RQ1무감독 예측 메모리가 관찰과 결정 사이에 긴 지연이 있는 태스크를 메모리 기반 에이전트가 해결하게 할 수 있는가?
- RQ2예측 모델링을 통해 감각 입력을 상태 변수로 압축하는 것이 엔드-투-엔드 메모리 RL 시스템과 비교해 메모리 형성과 검색을 개선하는가?
- RQ3목표로부터 다른 시간적 거리의 정보에 메모리 읽기가 특화되어 계층적 목표지향적 행동을 가능하게 하는가?
- RQ4MERLIN이 강한 단순화 가정 없이 원시 감각 데이터에서 원샷 내비게이션 및 기타 심리학/신경과학에서 영감을 받은 태스크를 해결할 수 있는가?
주요 결과
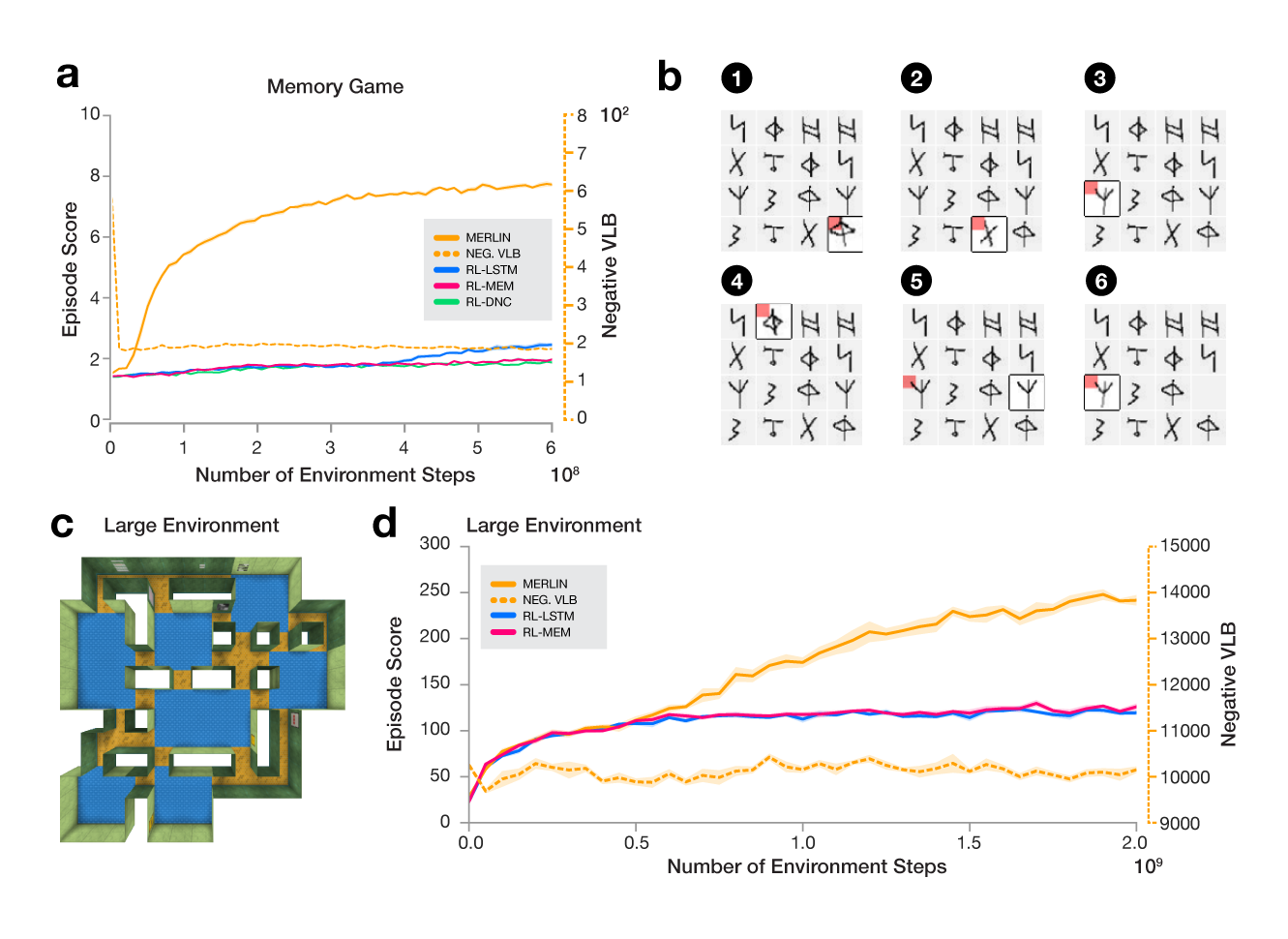
- MERLIN은 메모리 요구가 큰 태스크(예: Memory game, 대환경 내비게이션)에서 RL-LSTM과 RL-MEM이 고전하거나 실패하는 상황에서도 해결한다.
- MBP는 고차원 감각 입력을 약 10^2 정도의 상태 변수로 압축하고 예측 모델링을 통해 태스크 관련 정보를 유지한다.
- MBP의 메모리 읽기는 목표와 다른 거리에서 형성된 기억에 특화되어 계층적이고 목표지향적인 전략을 지원한다.
- MERLIN은 빠른 배중심(goal localization) 위치 추정과 메모리 사용 및 계획을 이끄는 견고한 리턴 예측을 보여준다.
- 임의의 시각운동 매핑과 빠른 보상 평가를 포함한 많은 태스크에서 MERLIN은 엔드-투-엔드 메모리 베이스라인보다 우수하며 경우에 따라 인간 성능에 근접하거나 능가한다.
- 잠재 학습과 레트로액티브 메모리 업데이트는 MERLIN이 필요할 때 더 일찍 획득한 정보를 기억하고 활용하게 하며, 기존의 Backpropagation-through-time 창을 넘어서도 가능하게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.