[論文レビュー] A Comparative Study of Quality Evaluation Methods for Text Summarization
本論文は patent document summarization における eight automatic metrics と人間の評価を比較し、人間の判断と密接に一致するLLMベースの評価フレームワークを提案して、ROUGE, BERTScore, SummaC のような従来の指標を上回ることを示している。
Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
研究の動機と目的
- 長尺の特許テキストに対する既存の自動要約評価指標の有効性を評価する。
- 要約品質を判断する際に、人的評価と自動指標がどのように比較されるかを評価する。
- 要約の自動評価指標としてのLLMsの実現可能性を探る。
- 要約を自動評価し反復的に改善するLLM主導のフレームワークを提案する。
提案手法
- 特許コーパス上でSOTA要約モデル(T5, XLNet, BART, BigBird, Pegasus, GPT-3.5, LongT5, Llama-3)を eight automatic metrics と人間の評価を用いて評価する。
- 長い特許テキストに対して広く用いられる自動指標(ROUGE-1/2/L, BLEU, BERTScore, SummaC, FRE, DCR)を再評価する。
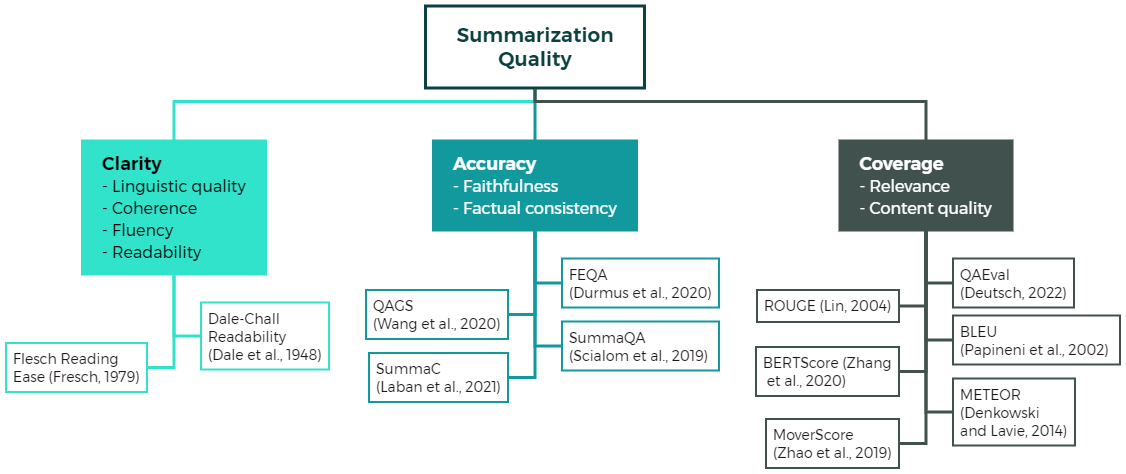
- 領域に配慮した審査員を用いて、明瞭性、正確性、網羅性、総合品質の4つの品質次元で manual human evaluation を実施する。
- 人間の指示と同一のプロンプトを用いて要約品質を評価するLLMベースの評価手法を実装する。
- 自動指標、人間の評価、LLMベースの評価を比較するメタ分析(Kendall Tau-b, Spearman, Pearson)を実施する。
- LLMのフィードバックが次の要約生成を導く反復的改善ループを実証する。
実験結果
リサーチクエスチョン
- RQ1長尺の特許要約に対する現在の自動評価指標は、人間の判断とどれくらい良く相関するか?
- RQ2LLMベースの評価は、要約品質の判断において人間の評価を再現または凌駕できるか?
- RQ3反復的でLLM主導の改善ループは、主要な次元で要約品質を向上させるか?
主な発見
- ROUGE-2, BERTScore, SummaC は特許要約における人間の評価と非常に弱い、または有意でない相関を示す。
- 可読性指標(FRE, DCR)はほとんどの指標および人間の判断と負の相関を示す。
- LLMs(オープンソースの Llama-3-8B および GPT-4 を含む)は、正確性、網羅性、総合品質の各面で人間の評価と強い整合性を示す(高い Kendall/Spearman 相関)。
- GPT-3.5-turbo-16k は、人間とLLMの評価で評価されたモデルの中で最も総合的な要約品質を示した。
- 反復的改善のための prompts に LLM の口頭フィードバックを組み込むと、明瞭性と網羅性が大幅に改善される一方、正確性はわずかに低下する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。