[論文レビュー] A Context-Aware Citation Recommendation Model with BERT and Graph Convolutional Networks
本論文は、文脈的テキスト符号化にBERTを用い、引用関係をモデル化するためにグラフ畳み込みネットワーク(GCN)を用いた文脈に配慮した引用推薦モデルを提案する。このモデルは、平均平均精度(MAP)とrecall@kで28%の向上を達成し、最先端の性能を示している。また、本研究では、引用推薦のための文脈文と論文メタデータを組み合わせた、最初の整理されたベンチマークデータセット「FullTextPeerRead」を提供する。
With the tremendous growth in the number of scientific papers being published, searching for references while writing a scientific paper is a time-consuming process. A technique that could add a reference citation at the appropriate place in a sentence will be beneficial. In this perspective, context-aware citation recommendation has been researched upon for around two decades. Many researchers have utilized the text data called the context sentence, which surrounds the citation tag, and the metadata of the target paper to find the appropriate cited research. However, the lack of well-organized benchmarking datasets and no model that can attain high performance has made the research difficult. In this paper, we propose a deep learning based model and well-organized dataset for context-aware paper citation recommendation. Our model comprises a document encoder and a context encoder, which uses Graph Convolutional Networks (GCN) layer and Bidirectional Encoder Representations from Transformers (BERT), which is a pre-trained model of textual data. By modifying the related PeerRead dataset, we propose a new dataset called FullTextPeerRead containing context sentences to cited references and paper metadata. To the best of our knowledge, This dataset is the first well-organized dataset for context-aware paper recommendation. The results indicate that the proposed model with the proposed datasets can attain state-of-the-art performance and achieve a more than 28% improvement in mean average precision (MAP) and recall@k.
研究の動機と目的
- 文脈に配慮した引用推薦のための標準化されたベンチマークデータセットの不足が、再現可能性の研究やモデル評価を妨げているという問題に対処すること。
- BERTによる文脈的理解とGCNを用いた構造的引用ネットワークモデリングを統合することで、引用推薦のパフォーマンスを向上させること。
- 文脈文、参照メタデータ、および科学論文からの引用リンクを含む、再現可能で整理されたデータセット「FullTextPeerRead」を構築すること。
- 文脈長と引用頻度が引用推薦タスクにおけるモデルパフォーマンスに与える影響を調査すること。
- MAP、MRR、recall@kの指標で既存手法を上回る、新しい最先端のモデルを提供すること。
提案手法
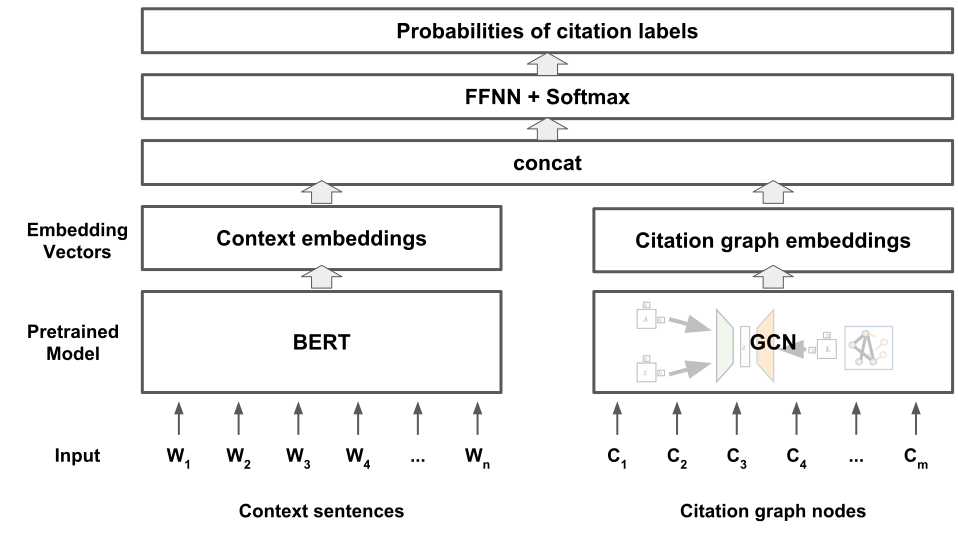
- モデルは二重エンコーダー構造を採用:引用プレースホルダーの周囲のテキストを符号化するBERTベースの文脈エンコーダー。
- グラフ畳み込みネットワーク(GCN)層が引用ネットワークデータを処理し、論文の引用グラフから潜在的表現を学習する。
- 変動的グラフオートエンコーダー(VGAE)を適用して、GCNエンコーダーを正則化し、局所的文脈パターンへの過学習を低減する。
- 最終的な表現は、BERTからの文脈埋め込みとGCNからのグラフベースの埋め込みを組み合わせ、候補となる引用の類似度スコアを計算する。
- FullTextPeerReadデータセットは、arXiv Vanityを介してLaTeXベースのPDFを解析し、文脈文とメタデータを抽出することで構築され、PeerReadおよびAANデータセットに文脈に配慮した引用情報が追加されている。
- モデルは対照的学習を用いてエンドツーエンドで訓練され、関連性の高い引用を推薦リストで上位に配置するように最適化される。
実験結果
リサーチクエスチョン
- RQ1BERTとGCNを統合することで、BERT単体を使用する場合と比較して、引用推薦のパフォーマンスがどの程度向上するか?
- RQ2文脈シーケンスの長さが引用推薦タスクにおけるモデルパフォーマンスにどの程度影響を及ぼすか?
- RQ3対象論文の引用頻度が、モデルがそれらを正確に推薦する能力に与える影響は何か?
- RQ4FullTextPeerReadのような統一的で整理されたデータセットは、引用推薦研究における一貫性のあるベンチマーク評価と再現可能性を可能にするか?
- RQ5GCNを用いたグラフベースの引用構造モデリングは、テキストのみの文脈に基づく埋め込みに比べて、関連性推定をどの程度向上させるか?
主な発見
- 提案されたBERT-GCNモデルは、ベースラインモデルと比較して、平均平均精度(MAP)とrecall@kで28%の向上を達成した。
- GCN統合付きのモデルは、BERT単体のモデルを上回り、引用頻度5の状況でMAPが0.6736(BERT単体では0.6593)を記録した。
- 文脈長が100トークンを超えるとパフォーマンス向上の効果が鈍り、ある文脈窓を超えると利得が減少する傾向が見られた。
- 対象論文の引用頻度が高いほど、モデルのパフォーマンスが向上する傾向があり、頻繁に引用される論文はより信頼性の高い学習信号を提供していると考えられる。
- FullTextPeerReadデータセットは、実際の科学論文から得た、整理されたメタデータと文脈文を用いて、正確で一貫性のある文脈抽出を可能にした。
- GCNは引用ネットワーク構造を捉えることで、テキストベースの埋め込みのみに依存する場合と比較して、類似度推定を向上させた。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。