[論文レビュー] AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
AfriQAはアフリカ諸語向けの最初のクロスリンガルオープンリトリーバルQAデータセットで、10言語にまたがる12,239質問を含み、XORリトリーバルと低資源言語のQAの評価を可能にします。
African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
研究の動機と目的
- アフリカ諸語のQAデータ不足に対応するため、アフリカ諸語に特化したグラウンドアップのXOR QAデータセットを作成する。
- 10のアフリカ諸語を横断するスケーラブルなベンチマークを提供し、クロスリンガルリトリーバルと回答生成を研究する。
- 翻訳、リトリーバル、QAのさまざまなベースラインを評価し、アフリカ諸語のXOR QAにおける現状の課題を特定する。
- 将来のデータセット作成とモデル開発を指針づけるための言語学的特性と注釈の課題の分析を提供する。
提案手法
- AfriQAを12,239問・8,892QAペア・10言語で構築する。
- アフリカ諸語の質問を入力言語とし、パッセージはピボット言語(英語またはフランス語)で取得するクロスリンガルオープンリトリーバル設定を用いる。
- 質問の引出し、ピボット言語への翻訳、ピボット言語での回答ラベリング、元言語への再翻訳の4段階注釈パイプラインでデータを収集する。
- 3つのXOR QAタスク(XOR-Retrieve、XOR-PivotLanguageSpan、XOR-Full)を翻訳、リトリーバル、リーダーモデルを用いて評価する。
- Google Translate、NLLB、M2M-100、BM25、mDPR、スパース-デンスハイブリッドなどのベースラインを比較し、AfroXLMRおよびmBERTベースのリーダーを用いる。
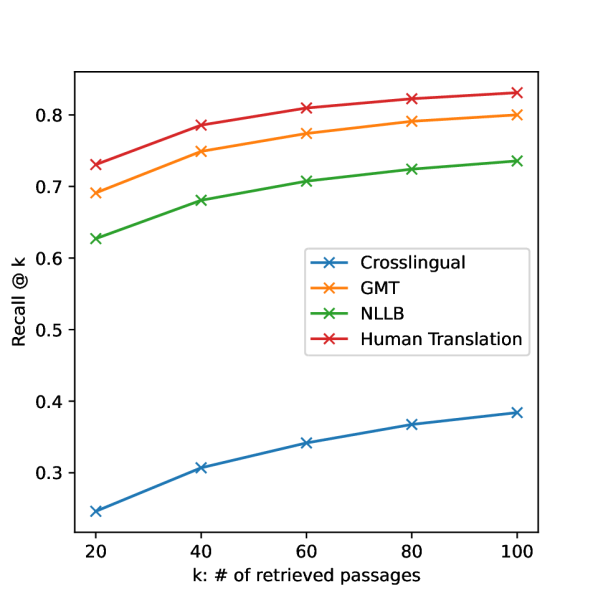
実験結果
リサーチクエスチョン
- RQ1現在の翻訳およびリトリーバルベースラインを用いたアフリカ諸語のクロスリンガルオープンリトリーバルQAの性能はどうか。
- RQ2翻訳品質とリトリーバル戦略が低資源言語のクロスリンガルQA精度にどう影響するか。
- RQ3ハイブリッドなスパース-デンスリトリーバル手法は、翻訳→リトリーブベースラインを超えられるか。
- RQ410言語の言語的特性がQAシステムの設計と評価にどのように影響するか。
主な発見
- 最終的なAfriQAデータセットは、10言語にまたがる12,239問と8,892QAペアを含む。
- 質問のうち回答不能は27%のみであり、Wikipedia制約下でも回答のカバレッジは比較的高い。
- クロスリンガルリトリーバル手法は翻訳ベースのベースラインを下回り、これらの言語における現在のクロスリンガルリトリーバルの欠点を示している。
- スパース-デンスリトリーバルのハイブリッド手法は、BM25またはmDPRのいずれか単独よりも多くの言語で改善を示した。
- 評価は先端QAモデルにとってAfriQAが挑戦的であることを示し、より公平な多言語QAシステムの開発を促している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。