[論文レビュー] AugGPT: Leveraging ChatGPT for Text Data Augmentation
AugGPTは入力文ごとに六つのセマンティックに関連する拡張をChatGPTで生成し、BERTと組み合わせると少数ショットのテキスト分類を改善します。手法は複数データセットで既存の拡張ベースラインを上回ります。
Text data augmentation is an effective strategy for overcoming the challenge of limited sample sizes in many natural language processing (NLP) tasks. This challenge is especially prominent in the few-shot learning scenario, where the data in the target domain is generally much scarcer and of lowered quality. A natural and widely-used strategy to mitigate such challenges is to perform data augmentation to better capture the data invariance and increase the sample size. However, current text data augmentation methods either can't ensure the correct labeling of the generated data (lacking faithfulness) or can't ensure sufficient diversity in the generated data (lacking compactness), or both. Inspired by the recent success of large language models, especially the development of ChatGPT, which demonstrated improved language comprehension abilities, in this work, we propose a text data augmentation approach based on ChatGPT (named AugGPT). AugGPT rephrases each sentence in the training samples into multiple conceptually similar but semantically different samples. The augmented samples can then be used in downstream model training. Experiment results on few-shot learning text classification tasks show the superior performance of the proposed AugGPT approach over state-of-the-art text data augmentation methods in terms of testing accuracy and distribution of the augmented samples.
研究の動機と目的
- NLPにおける小規模なラベル付きデータセットへ対処するデータ拡張の動機づけ。特にfew-shot学習で。
- 忠実で多様なサンプルを生成するChatGPTベースの拡張パイプラインを提案する。
- ChatGPTによる拡張が複数領域で下流分類器の精度を向上させることを示す。
- 拡張サンプルの忠実性と圧縮性を調査する。
提案手法
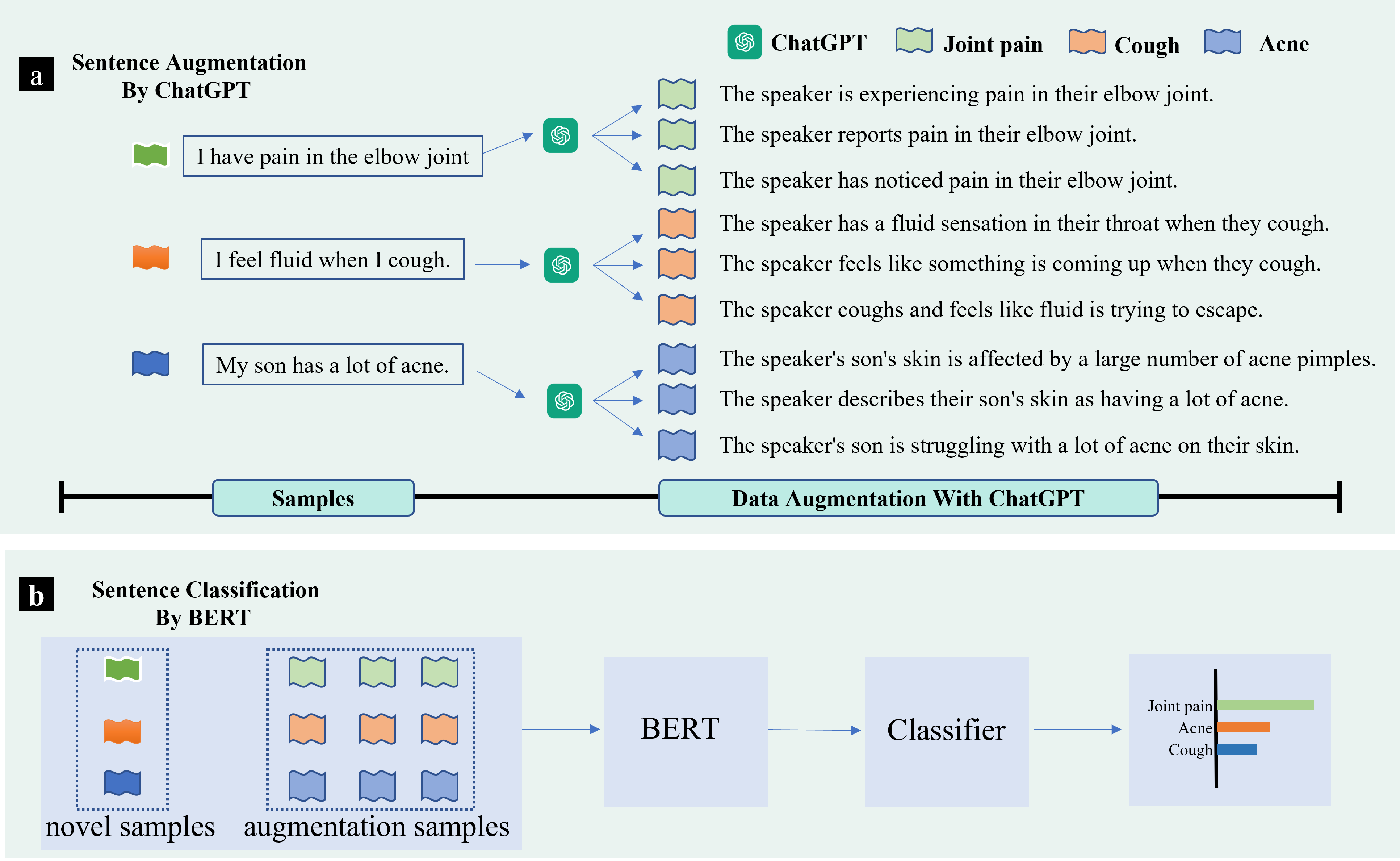
- ChatGPTが生成する6つのパラフレーズ様 variants で各入力文を拡張する。
- 基盤データセットでBERTベースの分類器をファインチューニングし、拡張データ(D_n_aug)で学習する。
- ChatGPT拡張はRLHFを用いるGPT-3/ChatGPTで、SFT、報酬モデリング、PPOベースのRL(PPO-ptx)を含む。
- 目的関数はクロスエントロピー損失とコントラスト損失を組み合わせ、同じクラスの表現を引き寄せ、異なるクラスの表現を引き離す。
- 式に基づく成分:L_CE = クロスエントロピー損失;L_CL = コントラスト損失;L = L_CE + lambda L_CL。
- ベースライン比較には従来および文脈拡張法の幅広いセットを含む。
実験結果
リサーチクエスチョン
- RQ1ChatGPT生成の拡張はセマンティックラベルを保持(忠実性)しつつ多様性(圧縮性)を高めることができるか?
- RQ2拡張は従来手法と比較して少数ショットのテキスト分類精度を改善するか?
- RQ3AugGPTは一般領域および生物医学領域データセットでどう機能するか?
- RQ4拡張とコントラスト学習を組み合わせると表現品質にどのような影響があるか?
主な発見
| データ拡張 | Amazon (BERT) | Amazon (BERT+C) | Symptoms (BERT) | Symptoms (BERT+C) | PubMed20K (BERT) | PubMed20K (BERT+C) |
|---|---|---|---|---|---|---|
| 生データ | 0.734 | 0.745 | 0.636 | 0.606 | 0.792 | 0.798 |
| バック翻訳拡張 | 0.757 | 0.748 | 0.778 | 0.747 | 0.812 | 0.83 |
| Bertを用いた文脈語拡張(挿入) | 0.761 | 0.750 | 0.697 | 0.677 | 0.802 | 0.811 |
| Bertを用いた文脈語拡張(置換) | 0.745 | 0.730 | 0.727 | 0.667 | 0.782 | 0.782 |
| DistilBERTを用いた文脈語拡張(挿入) | 0.759 | 0.762 | 0.707 | 0.747 | 0.796 | 0.796 |
| DistilBERTを用いた文脈語拡張(置換) | 0.787 | 0.766 | 0.667 | 0.646 | 0.797 | 0.800 |
| RoBERTaを用いた文脈語拡張(挿入) | 0.775 | 0.768 | 0.758 | 0.707 | 0.815 | 0.814 |
| RoBERTaを用いた文脈語拡張(置換) | 0.745 | 0.730 | 0.727 | 0.667 | 0.782 | 0.782 |
| CounterFittedEmbedding拡張 | 0.754 | 0.741 | 0.667 | 0.626 | 0.805 | 0.805 |
| InsertChar拡張 | 0.771 | 0.775 | 0.404 | 0.475 | 0.826 | 0.831 |
| Googleニュース埋め込みを用いた語の挿入 | 0.816 | 0.794 | 0.636 | 0.677 | 0.786 | 0.784 |
| Keyboard拡張 | 0.764 | 0.766 | 0.545 | 0.505 | 0.809 | 0.815 |
| OCR拡張 | 0.775 | 0.782 | 0.768 | 0.778 | 0.789 | 0.789 |
| PPDB同義語拡張 | 0.691 | 0.690 | 0.697 | 0.758 | 0.795 | 0.829 |
| スペリング拡張 | 0.727 | 0.736 | 0.697 | 0.707 | 0.808 | 0.811 |
| SubstituteChar拡張 | 0.762 | 0.768 | 0.535 | 0.586 | 0.816 | 0.821 |
| SubstituteWordをGoogleニュース埋め込みで拡張 | 0.729 | 0.741 | 0.727 | 0.727 | 0.807 | 0.822 |
| SwapChar拡張 | 0.762 | 0.766 | 0.475 | 0.485 | 0.797 | 0.801 |
| SwapWord拡張 | 0.771 | 0.766 | 0.687 | 0.727 | 0.798 | 0.794 |
| WordNet同義語拡張 | 0.805 | 0.798 | 0.616 | 0.758 | 0.761 | 0.757 |
| ChatGPT(2ショット) | 0.753 | 0.980 | 0.748 | - | - | - |
| AugGPT | 0.816 | 0.826 | 0.889 | 0.899 | 0.835 | 0.835 |
- AugGPTはAmazon、Symptoms、PubMed20Kのデータセット全体で最先端の拡張ベースラインよりも高い検証精度を達成。
- ChatGPTによる拡張サンプルは多様性を改善しつつ元のラベルとの整合性(忠実性)を維持。
- アブレーション研究では、AugGPTは多くの非LLM拡張技術(例:バック翻訳、文脈的語の拡張、同義語ベース手法)を上回る。
- この手法は2ショットのChatGPT設定でも、拡張データでのBERTベースファインチューニングと組み合わせても sizable gains を生み出す。
- 一般領域および臨床/NLPベンチマークの両方で強い性能向上を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。