[論文レビュー] Be Your Own Prada: Fashion Synthesis with Structural Coherence
本論文は、被写体のボディシェイプとポーズを保持しながら、一貫性があり領域特化型の衣料テクスチャを生成するテキスト条件付きファッション合成のための2段階GANフレームワークを提案する。空間制約を用いて最初にセマンティックセグメンテーションマップを生成し、その後コンポジショナルマッピング層を用いてテクスチャをレンダリングすることで、ベースラインと比較して優れた構造的整合性と視覚的品質を達成した。定量的指標と平均順位1.544のユーザースタディにより検証された。
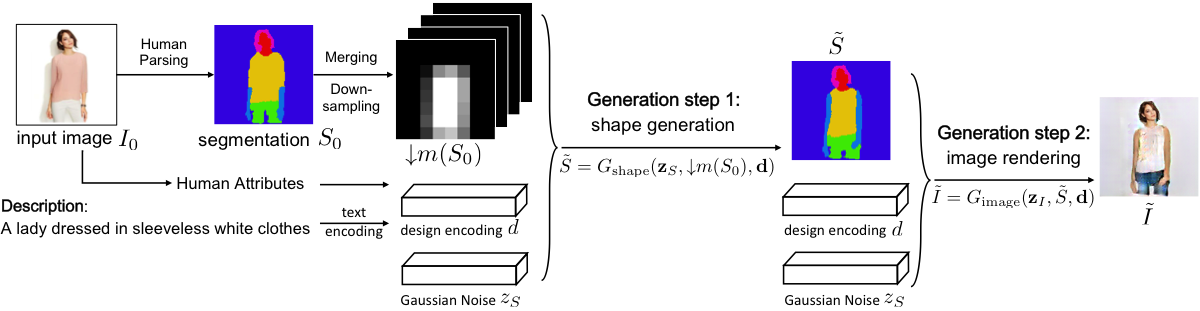
We present a novel and effective approach for generating new clothing on a wearer through generative adversarial learning. Given an input image of a person and a sentence describing a different outfit, our model "redresses" the person as desired, while at the same time keeping the wearer and her/his pose unchanged. Generating new outfits with precise regions conforming to a language description while retaining wearer's body structure is a new challenging task. Existing generative adversarial networks are not ideal in ensuring global coherence of structure given both the input photograph and language description as conditions. We address this challenge by decomposing the complex generative process into two conditional stages. In the first stage, we generate a plausible semantic segmentation map that obeys the wearer's pose as a latent spatial arrangement. An effective spatial constraint is formulated to guide the generation of this semantic segmentation map. In the second stage, a generative model with a newly proposed compositional mapping layer is used to render the final image with precise regions and textures conditioned on this map. We extended the DeepFashion dataset [8] by collecting sentence descriptions for 79K images. We demonstrate the effectiveness of our approach through both quantitative and qualitative evaluations. A user study is also conducted. The codes and the data are available at http://mmlab.ie.cuhk. edu.hk/projects/FashionGAN/.
研究の動機と目的
- 入力画像と自然言語記述に基づいて、被写体のボディシェイプとポーズを保持したまま、新しい衣料をテキスト条件付きで生成すること。
- 入力画像と自然言語記述の両方で条件付けられた場合のファッション合成における構造的整合性の課題に対処すること。
- 画像生成中にグローバル構造を維持できず、曇りやアーチファクトが生じる標準GANの限界を克服すること。
- 欠損している身体部位(例:腕)のホリデーションを可能にしつつ、身体領域の可視性を一貫性を持って保証する手法を開発すること。
- 定量的指標とセグメンテーションの現実性および画像品質に関するユーザースタディを通じて、モデルの性能を評価すること。
提案手法
- 本手法は2段階のGANを用いる:最初に、入力画像とテキストに条件付けられたセマンティックセグメンテーションマップを生成し、次にそのマップとテキストから最終的な画像をレンダリングする。
- 入力画像に基づく新しい空間制約を定式化し、最初段階のGANが被写体のポーズとボディ構造をテキスト記述と矛盾せずに保持できるようにガイドする。
- 2段階目のジェネレータは、領域特化型のテクスチャ合成を可能にする新規なコンポジショナルマッピング層を採用しており、非コンポジショナルGANと比較して整合性を高め、ぼやけを低減している。
- 79,000枚の上半身画像を含み、文の記述と人体部位ラベルがアノテーションされたDeepFashionデータセットの拡張版を用いてモデルを学習した。
- 最初段階のGANは、身体部位と衣類の領域を定義するセグメンテーションマップを生成し、入力との構造的整合性を保証する。
- 2段階目のGANは、セグメンテーションマップとテキスト埋め込みを用いて、正確なテクスチャと一貫性のある身体部位の可視性を持つフォトリアリスティックな画像を生成する。

実験結果
リサーチクエスチョン
- RQ11段階目の入力画像とテキスト記述から、被写体のボディシェイプとポーズを保持しながら、高い構造的整合性を持つファッション画像を2段階GANフレームワークが生成できるか?
- RQ2入力画像から導出された空間制約は、テキスト記述と矛盾しない妥当なセグメンテーションマップの生成を効果的にガイドできるか?
- RQ3非コンポジショナルGANと比較して、コンポジショナルマッピング層はファッション合成における領域特化型テクスチャレンダリングをどの程度向上させるか?
- RQ4人間参加者が、生成されたセグメンテーションマップの現実性と最終画像の視覚的品質をベースラインと比較してどの程度高く評価するか?
- RQ5モデルは、平らな背景を持つデータセットで学習した場合でも、未学習の衣装や背景タイプに一般化できるか、特に背景が模様付きの場合でも有効か?
主な発見
- ユーザースタディにおいて、本手法は平均順位1.544を達成し、2D非パrametric手法(平均順位2.286)を含むすべてのベースラインを大きく上回った。
- 参加者の42%が生成されたセグメンテーションマップを本物と誤認するほど、中間出力の現実性と妥当性が高く、高いリアルさを示した。
- コンポジショナルマッピング層は、ぼやけを効果的に低減し、領域特化型のテクスチャの一貫性を向上させたことが、非コンポジショナルベースラインとの定性的比較で示された。
- 空間制約を備えた2段階フレームワークは、欠損部位のホリデーションが必要なケースにおいても、アーチファクトを著しく低減し、構造的整合性を向上させた。
- ユーザーランキングと定性的な結果から、1段階GANSベースライン(例:One-Step-8-7およびOne-Step-8-4)と比較して、視覚的品質と形状の一貫性の両面で本手法が優れていた。
- 背景に模様があるデータで学習した場合でも、潜在ベクトルが背景の分布を捉えており、明示的な背景モデリングが不要なことから、模様付き背景に対しても一般化可能であることが示された。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。