[論文レビュー] Capabilities of Gemini Models in Medicine
Med-Gemini は Gemini を基盤とする医療専門のマルチモーダルモデルファミリーで、14 の医療ベンチマークのうち 10 で SoTA を達成し、比較可能な箇所では GPT-4 を上回り、ウェブ検索の統合とカスタムエンコーダを備えた長い文脈とマルチモーダル能力を示しています。
Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
研究の動機と目的
- Gemini の基盤を用いて医療AIにおける臨床推論とマルチモーダル理解を進展させる。
- テキスト、マルチモーダル、長い文脈のベンチマーク全般で Med-Gemini を評価し、SoTA パフォーマンスを確立する。
- 医療タスクにおけるウェブ検索グラウンディングとモダリティ固有のエンコーダの利点を示す。
- 医療ノートの要約と紹介状作成における実世界での有用性を評価する。
- 展開前の安全性の配慮と厳格な検証の必要性を強調する。
提案手法
- Gemini 1.0 Ultra および 1.0 Pro をファインチューニングして Med-Gemini L 1.0 (web-search grounded) と Med-Gemini M 1.0/1.5 をマルチモーダルタスク用に作成。
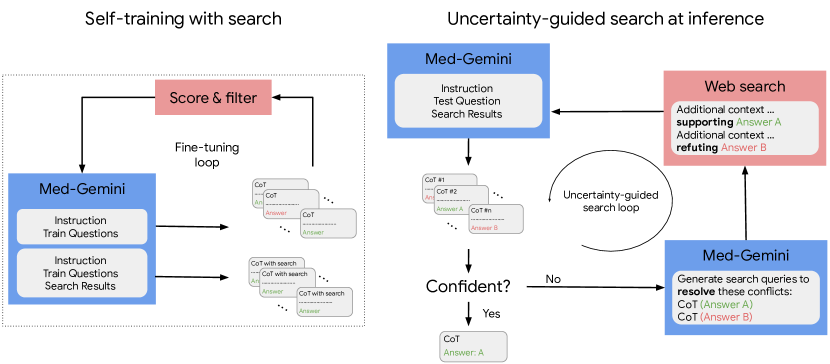
- 推論説明(CoTs)とチェーン・オブ・ソート・プロンプトを含む自己訓練データを開発し、MedQA-R および MedQA-RS データセットを作成。
- 推論時に不確実性誘導検索を実装して必要時にウェブ検索を起動し、取得した結果をプロンプトに組み込む。
- 8つのマルチモーダル医療データセットでファインチューニングして Med-Gemini-M 1.5 を形成し、(例:ECG)など新規モダリティ向けの専門エンコーダを作成。
- 長い文脈構成と推論チェーンを活用して needle-in-a-haystack の EHR 検索と医療動画理解タスクに対処。
- MedQA (USMLE)、NEJM CPC、GeneTuring を含む14の医療ベンチマークにわたる25タスクをベンチマーク。
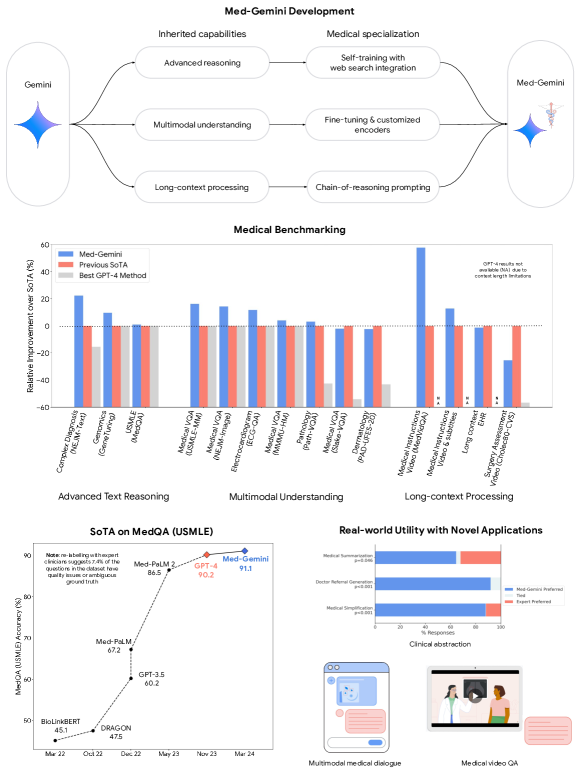
実験結果
リサーチクエスチョン
- RQ1Med-Gemini は幅広い医療タスク(テキスト、マルチモーダル、長い文脈)で最先端の成果を達成できるか。
- RQ2ウェブ検索グラウンディングと不確実性誘導推論は医療推論の精度を向上させるか。
- RQ3モダリティ特化エンコーダは新規医療データ(例:ECG)と長文脈のEHRに Med-Gemini をどれだけ拡張できるか。
- RQ4医療ノート要約や紹介状生成などのタスクにおける Med-Gemini の実世界での有用性は何か。
- RQ5直接比較が可能なベンチマークで Med-Gemini は GPT-4 とどう比較されるか。
主な発見
- Med-Gemini は 14 の医療ベンチマークのうち 10 で SoTA を達成し、比較が可能な箇所では GPT-4 を上回る。
- MedQA (USMLE) では、最良の Med-Gemini モデルが 91.1% の正解率に達し、Med-PaLM 2 を 4.6% 上回る。
- 不確実性誘導検索は NEJM CPC および GeneTuring ベンチマークにも一般化し、SoTA の結果を達成。
- マルチモーダルベンチマークでは 7 タスク中 5 で SoTA を達成し、GPT-4V に対して平均で相対マージン 44.5% 向上。
- 長い文脈の能力により needle-in-a-haystack の EHR 理解と医療動画QAの SoTA 結果を実現。
- ベンチマークを超えて、Med-Gemini は医療ノートの要約と紹介状生成における実世界での実用可能性を示し、定性的なマルチモーダル対話デモンストレーションを含む。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。