[論文レビュー] CodeV: Empowering LLMs with HDL Generation through Multi-Level Summarization
CodeVは、Verilog生成LLMを指示調整するために逆 prompting によってVerilogコードを多層の自然言語記述に変換し、VerilogEvalとRTLLMのベンチマークでSOTAの結果を達成します。
The design flow of processors, particularly in hardware description languages (HDL) like Verilog and Chisel, is complex and costly. While recent advances in large language models (LLMs) have significantly improved coding tasks in software languages such as Python, their application in HDL generation remains limited due to the scarcity of high-quality HDL data. Traditional methods of adapting LLMs for hardware design rely on synthetic HDL datasets, which often suffer from low quality because even advanced LLMs like GPT perform poorly in the HDL domain. Moreover, these methods focus solely on chat tasks and the Verilog language, limiting their application scenarios. In this paper, we observe that: (1) HDL code collected from the real world is of higher quality than code generated by LLMs. (2) LLMs like GPT-3.5 excel in summarizing HDL code rather than generating it. (3) An explicit language tag can help LLMs better adapt to the target language when there is insufficient data. Based on these observations, we propose an efficient LLM fine-tuning pipeline for HDL generation that integrates a multi-level summarization data synthesis process with a novel Chat-FIM-Tag supervised fine-tuning method. The pipeline enhances the generation of HDL code from natural language descriptions and enables the handling of various tasks such as chat and infilling incomplete code. Utilizing this pipeline, we introduce CodeV, a series of HDL generation LLMs. Among them, CodeV-All not only possesses a more diverse range of language abilities, i.e. Verilog and Chisel, and a broader scope of tasks, i.e. Chat and fill-in-middle (FIM), but it also achieves performance on VerilogEval that is comparable to or even surpasses that of CodeV-Verilog fine-tuned on Verilog only, making them the first series of open-source LLMs designed for multi-scenario HDL generation.
研究の動機と目的
- 自動化されたVerilog/HDLコード生成を動機づけ、ハードウェア設計コストを削減する。
- 実世界のコードから高品質なVerilogに焦点を当てたinstruction-tuningデータセットを構築することでデータ不足を克服する。
- マルチレベルサマリゼーションがHDLタスクにおける記述-コードの整合性を改善することを示す。
- CodeVデータでオープンソースLLMをファインチューニングするとVerilog生成性能がSOTAになることを示す。
提案手法
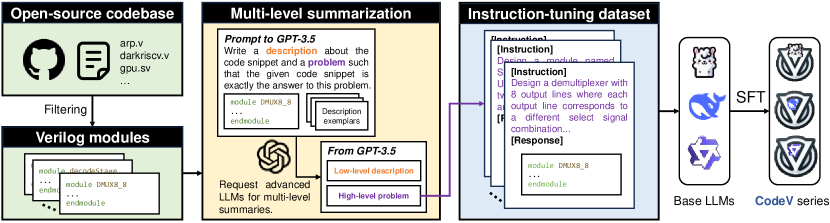
- GitHubから高品質な実世界のVerilogモジュールを収集し、自己完結的な構文正しいコードをフィルタリングする。
- VerilogコードからGPT-3.5に対して細粒度の機能記述と高レベルの要件を生成させることでマルチレベルサマリゼーションを適用する。
- 逆指示生成と Rouge-L に基づくフィルタリングで記述-コードデータセットを構築する。
- CodeVデータセットを基盤LLM(CodeLlama、DeepSeekCoder、CodeQwen)に対して監督学習目的(負の対数尤度)でファインチューニングする。
- VerilogEvalとRTLLMベンチマークでpass@kと構文/機能チェックを用いて評価する。
実験結果
リサーチクエスチョン
- RQ1マルチレベルサマリゼーションはVerilogコードと自然言語記述の間の意味論的ギャップをデータ効率の良い指示チューニングに橋渡しできるか。
- RQ2逆指示生成は伝統的な記述先行アプローチと比べてVerilog記述-コードペアの品質を改善するか。
- RQ3CodeV調整モデルは既存のオープンソースおよび商用SOTAモデルとVerilog生成ベンチマークでどの程度比較されるか。
- RQ4データセットのサイズとMLS(マルチレベルサマリゼーション)がVerilog生成性能に与える影響は何か。
主な発見
- CodeVモデルはVerilogEvalとRTLLMベンチマークでSOTAの結果を達成し、従来のオープンソースSOTAやGPT-4をVerilog生成タスクで上回る。
- マルチレベルサマリゼーションはVerilogの機能に関する推論を大幅に改善し、pass@kと構文/機能正確性を向上させる。
- CodeV-CodeLlamaおよびCodeV-CodeQwenのバリアントは顕著なpass@1と構文/機能スコアを達成し、機械-人間評価ギャップで強力な性能を示す。
- データセットサイズのスケーリングはデータ量を増やすと性能が向上するが、リターンが逓減することを示し、単純な量よりもデータ品質の重要性を強調する。
- このアプローチはVerilogEvalの総合測定でGPT-4に対して22.1%の相対的改善をもたらす。
![Figure 2: GPT-generated Verilog dataset contains unrealistic code. (a) A synthetic description obtained from [ 26 ] , which is unrealistic. (b) The circuit’s block diagram according to the description, contains illegal loops in the circuit. (c) The corresponding incorrect Verilog code in the dataset](https://ar5iv.labs.arxiv.org/html/2407.10424/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。