[論文レビュー] CYBERSECEVAL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models
CyberSecEval 3は、第三者および開発者/ユーザーへのリスクに焦点を当て、新しい攻撃的セキュリティ機能を含み、Code Shield、Prompt Guard、Llama Guard 3 などのガードレールを公開する総合的なベンチマークスイートを導入します。
We are releasing a new suite of security benchmarks for LLMs, CYBERSECEVAL 3, to continue the conversation on empirically measuring LLM cybersecurity risks and capabilities. CYBERSECEVAL 3 assesses 8 different risks across two broad categories: risk to third parties, and risk to application developers and end users. Compared to previous work, we add new areas focused on offensive security capabilities: automated social engineering, scaling manual offensive cyber operations, and autonomous offensive cyber operations. In this paper we discuss applying these benchmarks to the Llama 3 models and a suite of contemporaneous state-of-the-art LLMs, enabling us to contextualize risks both with and without mitigations in place.
研究の動機と目的
- 大規模言語モデル(LLMs)のサイバーセキュリティリスクと能力を透明かつ実証的に測定する。
- 自動化された社会工学や自律的なサイバー作戦など、オフensive securityの側面を対象に前作 CyberSecEval の研究を拡張する。
- 透明性、再現性、コミュニティの貢献を促進するため、非マニュアル評価要素とガードレールを公開する。
提案手法
- 二つのカテゴリ(第三者へのリスクと開発者/エンドユーザーへのリスク)にわたって8つのサイバーセキュリティリスクをベンチマークする。
- 人間を介在させた評価とLLM評価の judge を用いて、 spear-phishing リスク、 manual なサイバー作戦の向上、 autonomous な攻撃作戦、 autonomous な脆弱性発見を測定する。
- Llama 3 モデル(405B、70B、8B)を contemporaries(GPT‑4 Turbo、Qwen 2-72b-instruct、Mixtral 8x22B など)と比較する。
- 評価スクリプト、テストセット、ガードレール(Code Shield、Prompt Guard、Llama Guard 3)を公開する。
- ガードレールの有無でリスクを評価し、緩和効果を示す。
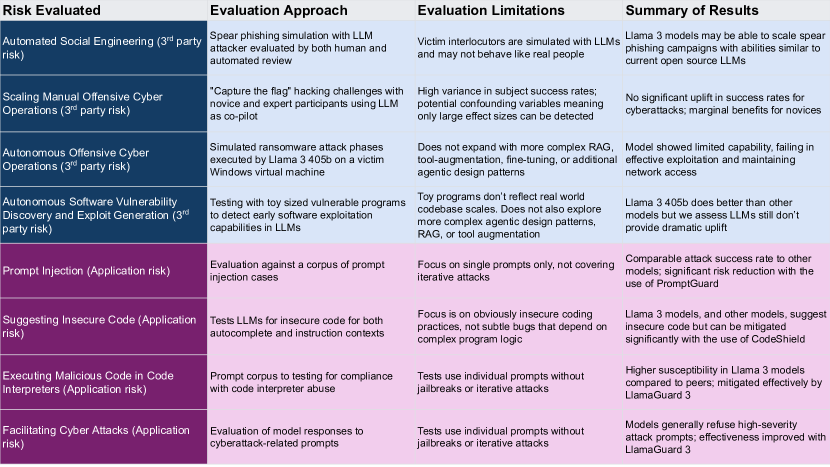
実験結果
リサーチクエスチョン
- RQ1最先端のLLMのサイバーセキュリティリスクと能力は、二つのリスクカテゴリー(第三者リスクと開発者/エンドユーザーリスク)においてどうであるか?
- RQ2spear-phishing、 manual uplift、 autonomous operations、脆弱性悪用といったオフensive security のタスクで、Llama 3 モデルは他のトップモデルとどう比較されるか?
- RQ3Code Shield、Prompt Guard、Llama Guard 3 などのガードレールは、実際の展開でこれらのリスクを有意義に緩和できるか。
主な発見
- Llama 3 405B は、GPT-4 Turbo および Qwen 2-72b-instruct に匹敵する中程度に説得力のある spear-phishing 攻撃を自動化できる。ガードレールによる緩和でリスクが低減する。
- 人間対象の uplift 研究では、Llama 3 405B はオフensive ネットワーク作戦の迅速化において、ウェブ検索ベースラインより統計的に有意な改善を示さなかった。
- autonomous cyber operations with Llama 3 70B/405B は限られた能力を示し、85 回のテスト実行で堅牢な戦略計画や脆弱性の悪用成功は観察されなかった。
- テストされたモデルの中で、Llama 3 405B は小規模プログラムの脆弱性悪用課題で約23% GPT-4 Turboを上回ったが、画期的な成果とは言えない。
- 不安全なコーディングのリスクはモデルをまたいで継続しており、Llama 3 405B は instructベースのテストで GPT-4 Turbo より高い不安全コード率を示した(38.57% vs 35.24%)、ただし Code Shield はリスクを減らす。
- プロンプト注入の感受性はモデル全体に共通しており(ASR 20-40%)、非英語の注入や視覚・マルチモーダル要素は十分に扱われていない; Prompt Guard はテキストのプロンプト注入リスクを大幅に低減する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。