[論文レビュー] Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box\n Machine Learning Models
Boundary Attack は、黒-boxモデル上で動作する単純で効果的な決定ベースの敵対的攻撃であり、最初に大きな敵対的摂動から始め、決定境界に沿って反復的にそれを縮小する。標準的なビジョンタスクでは勾配ベースの攻撃と同程度の性能を示す。
Many machine learning algorithms are vulnerable to almost imperceptible\nperturbations of their inputs. So far it was unclear how much risk adversarial\nperturbations carry for the safety of real-world machine learning applications\nbecause most methods used to generate such perturbations rely either on\ndetailed model information (gradient-based attacks) or on confidence scores\nsuch as class probabilities (score-based attacks), neither of which are\navailable in most real-world scenarios. In many such cases one currently needs\nto retreat to transfer-based attacks which rely on cumbersome substitute\nmodels, need access to the training data and can be defended against. Here we\nemphasise the importance of attacks which solely rely on the final model\ndecision. Such decision-based attacks are (1) applicable to real-world\nblack-box models such as autonomous cars, (2) need less knowledge and are\neasier to apply than transfer-based attacks and (3) are more robust to simple\ndefences than gradient- or score-based attacks. Previous attacks in this\ncategory were limited to simple models or simple datasets. Here we introduce\nthe Boundary Attack, a decision-based attack that starts from a large\nadversarial perturbation and then seeks to reduce the perturbation while\nstaying adversarial. The attack is conceptually simple, requires close to no\nhyperparameter tuning, does not rely on substitute models and is competitive\nwith the best gradient-based attacks in standard computer vision tasks like\nImageNet. We apply the attack on two black-box algorithms from Clarifai.com.\nThe Boundary Attack in particular and the class of decision-based attacks in\ngeneral open new avenues to study the robustness of machine learning models and\nraise new questions regarding the safety of deployed machine learning systems.\nAn implementation of the attack is available as part of Foolbox at\nhttps://github.com/bethgelab/foolbox .\n
研究の動機と目的
- 現実世界の黒箱モデルに対する決定ベースの攻撃の関連性を強調する。
- Boundary Attack を複雑なデータセットに対する最初の効果的な決定ベース法として導入する。
- 決定ベースの攻撃が特定の防御戦略を破ることができることを示す。
- Clarifai などの実世界の黒箱APIおよび標準的なビジョンベンチマークへの適用性を示す。
提案手法
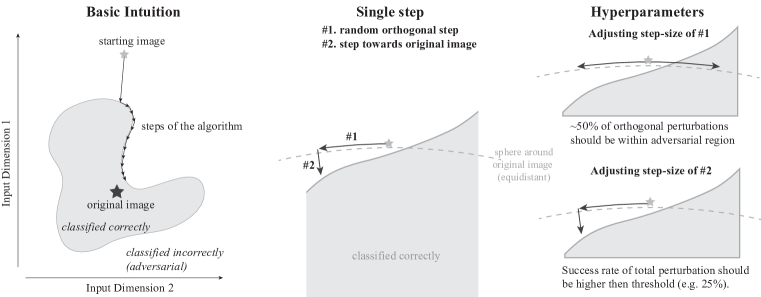
- 敵対的例から開始し、境界追従攻撃を提案して拒否サンプリングを行い、最小摂動へ向かって境界沿いに移動する。
- 単純な提案分布を使用:ガウス方向をサンプルし、球面に射影して元の入力へ向かって移動させる。2つの調整可能なステップサイズ(直交と原点への方向)を用いる。
- 最終モデルの決定のみを要求し、信頼度や勾配は不要で、任意の敵対的基準を許容する。
- 局所境界幾何に基づく信頼領域風のスキームを用いて摂動長とステップサイズを動的に調整する。
- 標準的なアーキテクチャ(VGG-19、ResNet-50、Inception-v3)を用いて MNIST、CIFAR-10、ImageNet の未ターゲットおよびターゲット設定で評価する。
- 摂動サイズと防御耐性の点で勾配ベースの攻撃(FGSM、DeepFool、Carlini & Wagner)と比較する。

実験結果
リサーチクエスチョン
- RQ1勾配や信頼度スコアにアクセスせずとも、複雑で実世界のモデルに対して決定ベースの攻撃が信頼性のある敵対例を生成できるか?
- RQ2MNIST、CIFAR-10、ImageNet における未ターゲットおよびターゲット設定で Boundary Attack は勾配ベースの手法と比較してどのように性能を示すか?
- RQ3Boundary Attack は勾配マスキングや防御蒸留といった防御に対して頑健か?
- RQ4Boundary Attack は最終決定のみを観測する black-box な実世界API(例:Clarifai)で効果的に動作できるか?
主な発見
| 攻撃タイプ | MNIST | CIFAR | VGG-19 | ResNet-50 | Inception-v3 |
|---|---|---|---|---|---|
| FGSM gradient-based | 4.2e-02 | 2.5e-05 | 1.0e-06 | 1.0e-06 | 9.7e-07 |
| DeepFool gradient-based | 4.3e-03 | 5.8e-06 | 1.9e-07 | 7.5e-08 | 5.2e-08 |
| Carlini & Wagner gradient-based | 2.2e-03 | 7.5e-06 | 5.7e-07 | 2.2e-07 | 7.6e-08 |
| Boundary (our) decision-based | 3.6e-03 | 5.6e-06 | 2.9e-07 | 1.0e-07 | 6.5e-08 |
- Boundary Attack は未ターゲット設定において MNIST、CIFAR、ImageNet の各データセットで勾配ベースの攻撃と比較して競合的な最小摂動を達成する。
- 未ターゲットの ImageNet 実験では Boundary (ours) は MNIST で 3.6e-3、CIFAR で 5.6e-6、VGG-19 で 2.9e-7、ResNet-50 で 1.0e-7、Inception-v3 で 6.5e-8 の中央値摂動を取得。
- ターゲット設定では Boundary (ours) は MNIST で 6.5e-3、CIFAR で 3.3e-5、ImageNet(VGG-19)で 9.9e-06 の摂動を示す。
- Boundary Attack は防御蒸留などの防御を適用しても有効性を維持し、勾配マスキングに対して頑健であることを示す。
- Clarifai の二つのブラックボックスモデル(ブランド認識と有名人認識)では、Boundary Attack は通常 1e-2 から 1e-3 程度の摂動で敵対例を生成できたが、誤分類のためにより大きな摂動を要するサンプルもあった。
- この攻撃は勾配を用いず、前方推論回数を勾配ベースの攻撃より大幅に多く必要とするため、勾配ではなくモデルの決定に依存していることを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。