[論文レビュー] Deep Multi-agent Reinforcement Learning for Highway On-Ramp Merging in Mixed Traffic
論文は混雑した交通における高速道路入口合流を分散型マルチエージェント強化学習問題として定式化し、アクションマスキング、優先度ベースの安全監視者、カリキュラム学習を備えたスケーラブルなMARLフレームワークを導入。ベンチマークに対して安全性と効率性で優越。
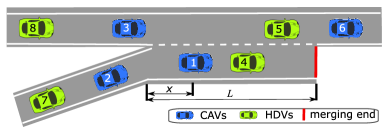
On-ramp merging is a challenging task for autonomous vehicles (AVs), especially in mixed traffic where AVs coexist with human-driven vehicles (HDVs). In this paper, we formulate the mixed-traffic highway on-ramp merging problem as a multi-agent reinforcement learning (MARL) problem, where the AVs (on both merge lane and through lane) collaboratively learn a policy to adapt to HDVs to maximize the traffic throughput. We develop an efficient and scalable MARL framework that can be used in dynamic traffic where the communication topology could be time-varying. Parameter sharing and local rewards are exploited to foster inter-agent cooperation while achieving great scalability. An action masking scheme is employed to improve learning efficiency by filtering out invalid/unsafe actions at each step. In addition, a novel priority-based safety supervisor is developed to significantly reduce collision rate and greatly expedite the training process. A gym-like simulation environment is developed and open-sourced with three different levels of traffic densities. We exploit curriculum learning to efficiently learn harder tasks from trained models under simpler settings. Comprehensive experimental results show the proposed MARL framework consistently outperforms several state-of-the-art benchmarks.
研究の動機と目的
- 混雑交通の入口合流問題を分散型MARL問題として定式化する。
- 協力のためのパラメータ共有と局所報酬を備えたスケーラブルなMARLフレームワークを開発する。
- アクションマスキングと優先度ベースの安全監視者を通じて学習効率と安全性を向上させる。
- 難しい合流シナリオを効率的に習得するためにカリキュラム学習を取り入れる。
- オープンソースの gym のようなシミュレータを提供し、ベンチマークに対して卓越した性能を実証する。
提案手法
- AVをエージェントとする部分観測MARL問題として入口合流シナリオをモデル化する。
- スケーラビリティを実現するためパラメータ共有を用い、エージェント数の変動と均質ポリシーを可能にする。
- クレジット割当を扱い協調を促進するため局所報酬設計を組み込む。
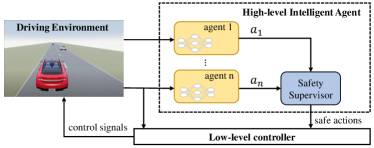
- 無効なアクションを除外し学習の安定性を向上させるためアクションマスキングを適用する。
- 多段予測(IDM/MOBIL HDVモデル)を用いる優先度ベースの安全監視者を導入し衝突を防ぐ。
- 運動学的自転車モデルと低レベルPIDコントローラを用いて高レベルMARLアクションを実現する。
実験結果
リサーチクエスチョン
- RQ1分散型MARLフレームワークとパラメータ共有は混雑交通の高速道路入口合流を安全かつ効率的に達成できるか?
- RQ2アクションマスキングと優先度ベースの安全監視者は学習効率を改善し、ベースラインMARL手法と比較して衝突を減らせるか?
- RQ3カリキュラム学習は難易度の高い合流シナリオで訓練の効率と性能にどのような影響を及ぼすか?
- RQ4提案フレームワークは動的トポロジーとAV数の変動に対してスケールするか?
- RQ5局所報酬設計がクレジット割当と協力行動に与える影響は?
主な発見
- アクションマスキングと優先度ベースの安全監視者を備えた提案MARLフレームワークは、実験を通じて安全性と効率性の点で複数の最先端ベンチマークを上回る。
- 局所報酬設計はクレジット割当問題を緩和し、隣接車両間の協力を改善する。
- カリキュラム学習はより難しい合流タスクを、より簡単なタスクを積み重ねることで効率的に習得させる。
- 安全監視者は訓練中の衝突率を低減し学習を加速させる。実用的なリアルタイム実現性(約28 ms/決定)。
- フレームワークは動的な通信トポロジーをサポートし、AV数の増減にスケールし、パラメータ共有によりエージェント間で単一のポリシーを維持する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。