[論文レビュー] Delta-LoRA: Fine-Tuning High-Rank Parameters with the Delta of Low-Rank Matrices
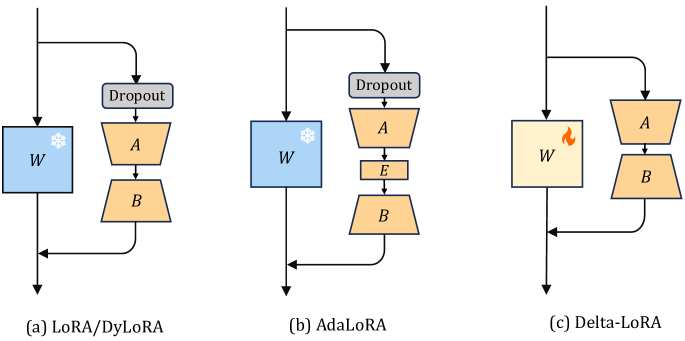
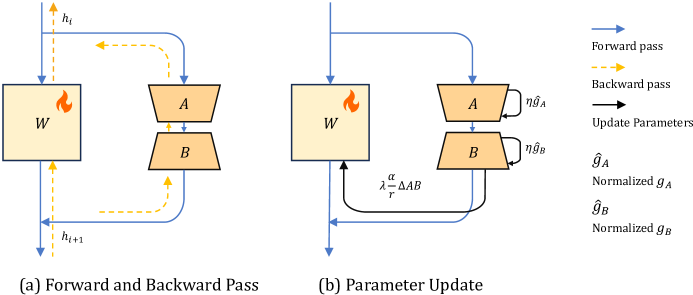
Delta-LoRAはWと2つの低秩アダプタを同時に更新し、ABのデルタを用いてWを調整することで、LoRAと同程度のメモリでタスク性能を改善する
In this paper, we present Delta-LoRA, which is a novel parameter-efficient approach to fine-tune large language models (LLMs). In contrast to LoRA and other low-rank adaptation methods such as AdaLoRA, Delta-LoRA not only updates the low-rank matrices $\bA$ and $\bB$, but also propagate the learning to the pre-trained weights $\bW$ via updates utilizing the delta of the product of two low-rank matrices ($\bA^{(t+1)}\bB^{(t+1)} - \bA^{(t)}\bB^{(t)}$). Such a strategy effectively addresses the limitation that the incremental update of low-rank matrices is inadequate for learning representations capable for downstream tasks. Moreover, as the update of $\bW$ does not need to compute the gradients of $\bW$ and store their momentums, Delta-LoRA shares comparable memory requirements and computational costs with LoRA. Extensive experiments show that Delta-LoRA significantly outperforms existing low-rank adaptation methods. We further support these results with comprehensive analyses that underscore the effectiveness of Delta-LoRA.
研究の動機と目的
- 大規模言語モデル(LLMs)のファインチューニングを、低秩アダプタのみを更新する以上に改善する動機づけ
- Delta-LoRAを提案し、ABのデルタを通じて前知識を持つウェイトへ学習信号を広げる
- LoRAと同等のメモリ効率を維持しつつ表現学習を強化する
- 勾配整列と性能の改善を示す理論的・経験的分析を提供する
提案手法
- ファインチューニング中に全ウェイト行列Wと2つの低秩行列AおよびBの両方を更新する
- デルタAB = A(t+1)B(t+1) − A(t)B(t)を計算し、それを用いてWを制御付き比λとスケールα/rで更新する
- 低秩ブランチのDropout層を削除して勾配を∂L/∂Wと∂L/∂(AB)が揃うようにする
- Wの勾配方向をΔ(AB)の符号で近似する(Wの勾配/モーメントを保存せず)
- AとBは通常どおりAdamWで訓練するが、Wの更新にはABデルタを適用し、Wのoptimizer状態を保存しない
- Delta-LoRAのアルゴリズム的手順(開始ステップK、学習率η、ウェイト減衰β、ランクr、更新比λを含む)を提供する
実験結果
リサーチクエスチョン
- RQ1Δ(AB)を用いたWの更新は、AとBのみを更新する場合と比較して性能向上をもたらすか?
- RQ2Delta-LoRAはLoRAと同等のメモリ・計算コストを維持しつつより良いタスク性能を達成できるか?
- RQ3低秩ブランチからDropoutを除去すると、∂L/∂Wと∂L/∂(AB)の勾配整列にどのような影響があるか?
- RQ4ハイパーパラメータ(λ、K、η)の選択がDelta-LoRAの有効性にNLPタスク間でどのような影響を及ぼすか?
主な発見
- Delta-LoRAは複数のNLPタスクとデータセットでLoRA、AdaLoRA、DyLoRAを一貫して上回る
- アブレーションでは、Δ(AB)を介したWの更新が、ABの更新を単独で拡大・スケーリングするよりも表現を改善する
- 低秩モジュールからDropoutを除去すると勾配整列と最終性能が向上する
- Delta-LoRAはPEFT設定下でGLUE、E2E NLG Challenge、WebNLG Challenge 2017、XSumのベンチマークで最先端を達成
- 実験はDelta-LoRAがLoRAと同程度のメモリ使用量を維持しつつ顕著な性能向上を提供することを示す
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。