[論文レビュー] Diff-Instruct: A Universal Approach for Transferring Knowledge From Pre-trained Diffusion Models
Diff-Instructは、拡散プロセス全体に渡る積分KL発散を最小化することにより、事前学習済み拡散モデルから任意の暗黙的生成モデルへデータフリーで知識を移転し、拡散蒸留とGAN生成器の改善を可能にする。ベンチマークで強力な結果を示す。
Due to the ease of training, ability to scale, and high sample quality, diffusion models (DMs) have become the preferred option for generative modeling, with numerous pre-trained models available for a wide variety of datasets. Containing intricate information about data distributions, pre-trained DMs are valuable assets for downstream applications. In this work, we consider learning from pre-trained DMs and transferring their knowledge to other generative models in a data-free fashion. Specifically, we propose a general framework called Diff-Instruct to instruct the training of arbitrary generative models as long as the generated samples are differentiable with respect to the model parameters. Our proposed Diff-Instruct is built on a rigorous mathematical foundation where the instruction process directly corresponds to minimizing a novel divergence we call Integral Kullback-Leibler (IKL) divergence. IKL is tailored for DMs by calculating the integral of the KL divergence along a diffusion process, which we show to be more robust in comparing distributions with misaligned supports. We also reveal non-trivial connections of our method to existing works such as DreamFusion, and generative adversarial training. To demonstrate the effectiveness and universality of Diff-Instruct, we consider two scenarios: distilling pre-trained diffusion models and refining existing GAN models. The experiments on distilling pre-trained diffusion models show that Diff-Instruct results in state-of-the-art single-step diffusion-based models. The experiments on refining GAN models show that the Diff-Instruct can consistently improve the pre-trained generators of GAN models across various settings.
研究の動機と目的
- 実データなしで事前学習済み拡散モデル(DM)からの学習を動機付ける。
- DMの知識を用いて暗黙的生成モデルを指示する普遍的なフレームワークを開発する。
- 拡散プロセスに合わせた積分KL(IKL)発散を導入する。
- Diff-InstructがDMの知識を単一ステップ生成器へ蒸留しGAN生成器を改善できることを示す。
- DreamFusionおよび敵対的トレーニングとの関連を強調する。
提案手法
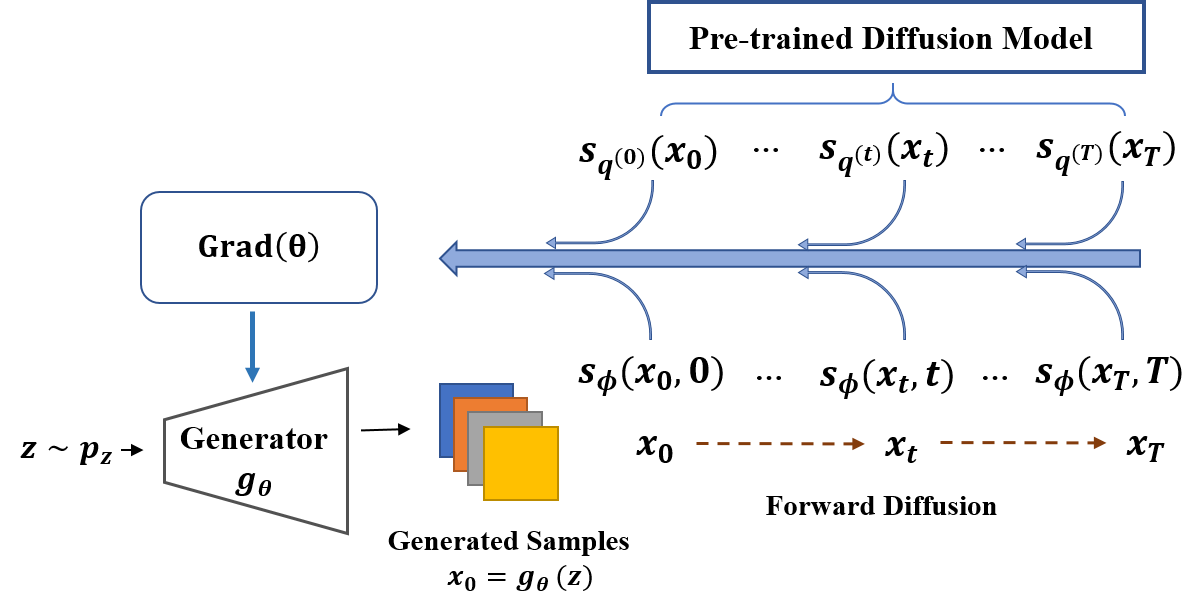
- 暗黙の生成器出力と事前学習済みDMの両方を同じ前向き拡散プロセスで拡散することにより普遍的な指示目的を定義する。
- 目的関数としてIKL発散を導入し、拡散時間を重み付け関数で積分したKL発散を用いる。
- 拡散プロセスの周辺スコア関数のモジュラーみに依存するIKL勾配を導出し、データフリーの監督を可能にする。
- 交互最適化を提案する: (a) 生成サンプルの周辺スコアネットワークを訓練、 (b) IKL勾配(式3.2)を用いて生成器パラメータを更新。
- Diff-Instructは生成器出力がディラックデルタの場合、SDSがDiff-Instructの特別なケースであることを示す(補題3.4)。
- Diff-InstructをGANトレーニングに関連付ける:IKLが時間重みゼロのKL最小化に縮約することを指摘(補題3.5)。
実験結果
リサーチクエスチョン
- RQ1事前学習済み拡散モデルの知識を、実データなしで任意の暗黙的生成モデルへ転移できるか。
- RQ2前方拡散プロセスをどのように利用して、IKL発散を介して学生生成器を監督できるか。
- RQ3Diff-Instruct、DreamFusion、従来のGANトレーニングとの関係は何か。
主な発見
- Diff-Instructは拡散蒸留においてImageNet64×64で単一ステップ拡散ベースモデルの中で最先端の性能を達成。
- GAN風生成器への蒸留時、Diff-Instructは事前学習済みGAN生成器(例:CIFAR-10のStyleGAN-2)を一貫して改善。
- CIFAR-10の無条件生成ではDiff-Instructは競争力のあるFIDを達成し、条件付き生成では一部の拈拶拡散ベースよりも上回ることがある。
- CIFAR-10とImageNet64での単一ステップ拡散蒸留で、Diff-Instructは収束を速め、サンプリング速度の大幅な改善をもたらすことがある(例:強いFID/ISを示す1ステップ生成器)。
- 本手法はデータフリーのままであり、リアルデータを必要とせず、事前学習DMのスコア関数を用いて学生を更新する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。