[論文レビュー] Differentially Private Diffusion Models Generate Useful Synthetic Images
この論文は、事前学習と拡張戦略を用いて privately fine-tuned diffusion models が高品質でプライバシーを保護する合成画像を生成し、強力な下流分類性能と効果的なモデル選択を可能にすることを示している。
The ability to generate privacy-preserving synthetic versions of sensitive image datasets could unlock numerous ML applications currently constrained by data availability. Due to their astonishing image generation quality, diffusion models are a prime candidate for generating high-quality synthetic data. However, recent studies have found that, by default, the outputs of some diffusion models do not preserve training data privacy. By privately fine-tuning ImageNet pre-trained diffusion models with more than 80M parameters, we obtain SOTA results on CIFAR-10 and Camelyon17 in terms of both FID and the accuracy of downstream classifiers trained on synthetic data. We decrease the SOTA FID on CIFAR-10 from 26.2 to 9.8, and increase the accuracy from 51.0% to 88.0%. On synthetic data from Camelyon17, we achieve a downstream accuracy of 91.1% which is close to the SOTA of 96.5% when training on the real data. We leverage the ability of generative models to create infinite amounts of data to maximise the downstream prediction performance, and further show how to use synthetic data for hyperparameter tuning. Our results demonstrate that diffusion models fine-tuned with differential privacy can produce useful and provably private synthetic data, even in applications with significant distribution shift between the pre-training and fine-tuning distributions.
研究の動機と目的
- _diffusion models_ がスケール(80M+ パラメータ)で差分プライバシーを用いて有用な合成画像を生成できることを実証する。
- 公開データ(ImageNet)での事前学習 plus DP-SGD による augmentation 戦略が、プライバシー制約下で高い有用性を実現することを示す。
- CIFAR-10 および Camelyon17 にわたる下流分類とモデル選択のための合成データの有用性を評価する。
- 実用的なガイドライン(augmentation の multiplicity、 timestep sampling bias)を提供し、DP 拡散モデルの性能を向上させる。
提案手法
- 公開 ImageNet データ(ImageNet32)で拡散モデルを事前学習し、DP 微調整の学習をブーストする。
- 各例ごとの勾配クリッピングとガウシアンノイズを用いた DP-SGD を適用し、privacy budgets(ε,δ)を可能にする。
- 画像とタイムステップ全体で augmentation multiplicity を用い、DP 下で有用な勾配情報を増幅する。
- 難易度の高い中間タイムステップへ学習を焦点化するように拡散 timestep sampling を bias し、内容学習を改善する。
- CIFAR-10 および Camelyon17 で 80M を超えるパラメータを持つ拡散モデルを privatized optimizer と調整されたハイパーパラメータで微調整する。
- DP 生成画像で下流の分類器を訓練し、実データのベースラインと比較して合成データを評価する。

実験結果
リサーチクエスチョン
- RQ1大規模な拡散モデルを差分プライバシーの下で効果的にファインチューニングして有用な合成画像を生成できるか。
- RQ2ImageNet 事前学習と DP-SGD は distribution shift があるデータセット(CIFAR-10, Camelyon17)に対しても高品質な合成データを提供するか。
- RQ3DP 拡散モデルの性能を最も改善する augmentation および sampling 戦略は何か。
- RQ4プライバシー制約の下で、下流タスクとハイパーパラメータ調整のために合成データをどのように活用できるか。
主な発見
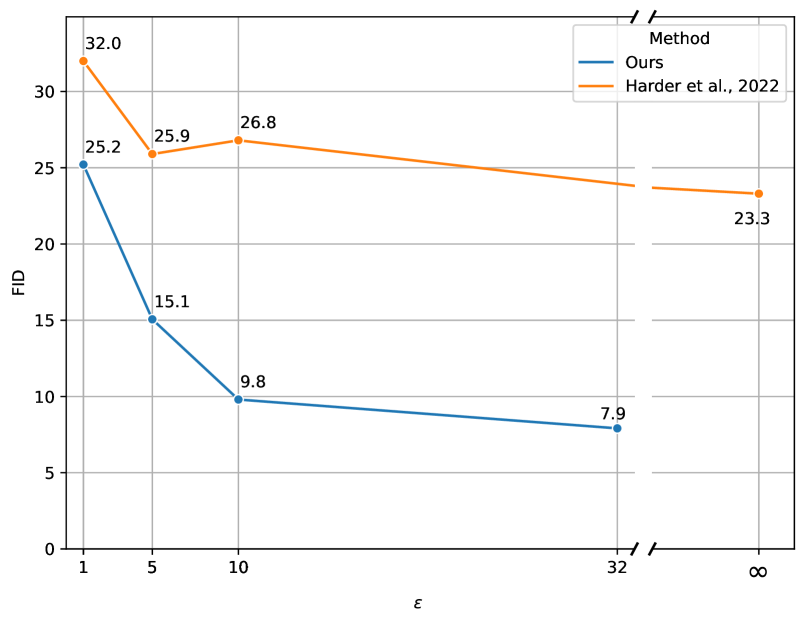
- CIFAR-10 で FID が 26.8(SOTA)から 9.8 に改善した。これは ImageNet 事前学習を用いた DP 拡散モデルによる。
- DP 合成データで訓練した下流分類器の CIFAR-10 精度が 51.0% から 88.0% に上昇。
- Camelyon17 では DP 合成データで下流精度が 91.1% に達し、実データの非プライベート SOTA である 96.5% に近づいた。
- MNIST 実験では DP 拡散で top-1 精度 98.6% を達成し、このタスクにおける従来の DP 結果を上回った。
- より大きな合成データセットとアンサンブルにより、プライバシーコストを増やさずに下流の精度がさらに向上した。
- 公開データでの事前学習と DP-SGD は、 distribution shift があっても高品質な合成データを可能にする(ImageNet32 → CIFAR-10、ImageNet32 → Camelyon17)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。