[論文レビュー] DiffusionSat: A Generative Foundation Model for Satellite Imagery
DiffusionSatは、テキストとメタデータを条件付けして単一画像生成と3D制御を可能にする衛星画像向けの初の大規模潜在拡散生成モデルであり、超解像、時間的生成、およびインペインティングを実現します。
Diffusion models have achieved state-of-the-art results on many modalities including images, speech, and video. However, existing models are not tailored to support remote sensing data, which is widely used in important applications including environmental monitoring and crop-yield prediction. Satellite images are significantly different from natural images -- they can be multi-spectral, irregularly sampled across time -- and existing diffusion models trained on images from the Web do not support them. Furthermore, remote sensing data is inherently spatio-temporal, requiring conditional generation tasks not supported by traditional methods based on captions or images. In this paper, we present DiffusionSat, to date the largest generative foundation model trained on a collection of publicly available large, high-resolution remote sensing datasets. As text-based captions are sparsely available for satellite images, we incorporate the associated metadata such as geolocation as conditioning information. Our method produces realistic samples and can be used to solve multiple generative tasks including temporal generation, superresolution given multi-spectral inputs and in-painting. Our method outperforms previous state-of-the-art methods for satellite image generation and is the first large-scale generative foundation model for satellite imagery. The project website can be found here: https://samar-khanna.github.io/DiffusionSat/
研究の動機と目的
- 衛星画像のスペクトル的、時系列、およびメタデータ特性に合わせた拡散ベースの生成モデルの必要性を動機づける。
- DiffusionSatを提案する。高解像度の公開衛星データセットで訓練された潜在拡散モデルで、 conditioning signalsとしてメタデータを活用する。
- 3D conditioning拡張(ControlNet風)を開発し、マルチスペクトル超解像、時系列生成、インペインティングなどのタスクを可能にする。
- DiffusionSatが衛星画像生成および関連逆問題で最先端の結果を達成することを示す。
- 多様な地理空間タスクに適応可能な公開前訓練データセットと訓練プロトコルを提供する。
提案手法
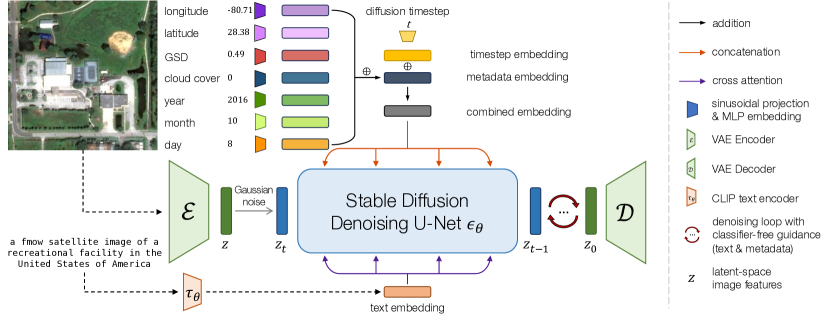
- 潜在拡散フレームワークを使用(VAEによるダウンサンプリング、潜在空間での拡散、デコーダによるアップサンプリング)Stable Diffusionの重みから初期化。
- 数値衛星メタデータを正弦投影と各データ点のMLPで符号化し、 timestep 埋め込みとともに最終的な conditioning ベクトルに加算する。
- キャプションが存在する場合、 denoising ネットワークを CLIP-like テキストキャプションで条件付けする。そうでなければメタデータと timestep 条件付けに依存する。
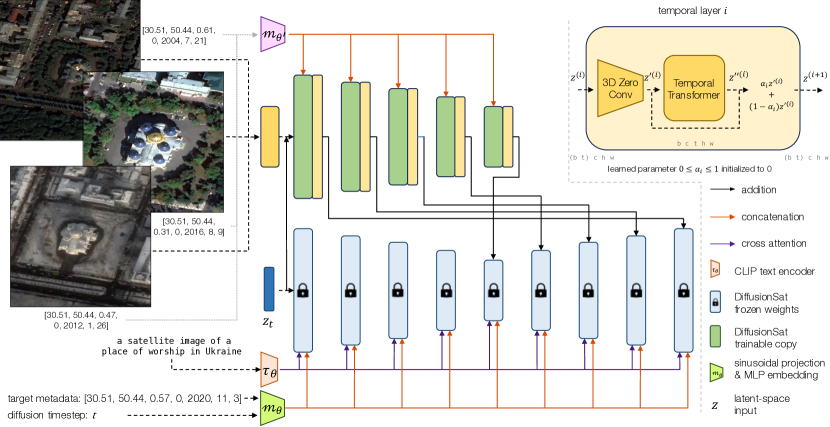
- 3D-ControlNetに触発された条件付け機構を導入し、SDブロック間の3Dゼロ畳み込みや時系列注意機構を含む時系列生成のための画像シーケンスを扱う。
- fMoW、Satlas、SpaceNet などの関連メタデータ(緯度経度、タイムスタンプ、GSD、雲量など)を伴う複数データセットの衛星画像で訓練。
- 単一画像生成および下流の条件付きタスク(超解像、時系列予測、インペインティング)にモデルを適用し、 baselines よりも改善した指標を示す。
実験結果
リサーチクエスチョン
- RQ1メタデータを conditioning 信号として使用して衛星画像で拡散ベースの基盤モデルを効果的に訓練し、単一画像生成の品質を高められるか?
- RQ23D conditioning フレームワークは、超解像、時系列予測、インペインティングを含むリモートセンシングデータでの信頼性の高いマルチタスク生成を実現できるか?
- RQ3メタデータを意識した条件付けとテキストのみの条件付けは、衛星画像の生成品質と制御にどのような影響を与えるか?
- RQ4衛星データに適合させた事前訓練済み潜在拡散ウェイトは、ゼロから訓練したモデルより逆問題の下流性能を向上させるか?
- RQ5異なるGSDとスペクトル帯を持つ多様な衛星データセット(fMoW、Satlas、SpaceNet)でモデルはどれだけ一般化できるか?
主な発見
- DiffusionSatは単一画像の衛星生成において強力な視覚的および知覚的品質を達成し、FID、IS、clipスコアでベースラインを上回る。
- 数値メタデータを正弦埋め込みと各データ点のMLPを介して取り入れることで、キャプションのみの条件付けより生成品質が向上する。
- 3D条件付けアプローチは、マルチスペクトル超解像、時系列生成、インペインティングを含む下流タスクで最先端または競争力のある性能を実現する。
- DiffusionSatは、時系列予測とインペインティングのベンチマークで、STSRやMCVDなどのベースラインと比較してより良い LPIPS および競争力の SSIM/PSNR を示し、複数のデータセットで一致する。
- 大規模な公開衛星データセットでの事前訓練と、ほとんどのStable Diffusionウェ weightsを固定し、デノイジングネットとメタデータエンコーダのみ訓練することで、収束を速め、既存のウェイトを活用する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。