[論文レビュー] Eliciting Latent Predictions from Transformers with the Tuned Lens
本論文は Tuned Lens を導入する。これはアフィン層翻訳器ベースのプローブで、中間トランスフォーマの隠れ状態を最終層の語彙分布へデコードし、Logit Lens より解釈性を向上させ、因果分析と異常検知を可能にする。
We analyze transformers from the perspective of iterative inference, seeking to understand how model predictions are refined layer by layer. To do so, we train an affine probe for each block in a frozen pretrained model, making it possible to decode every hidden state into a distribution over the vocabulary. Our method, the tuned lens, is a refinement of the earlier "logit lens" technique, which yielded useful insights but is often brittle. We test our method on various autoregressive language models with up to 20B parameters, showing it to be more predictive, reliable and unbiased than the logit lens. With causal experiments, we show the tuned lens uses similar features to the model itself. We also find the trajectory of latent predictions can be used to detect malicious inputs with high accuracy. All code needed to reproduce our results can be found at https://github.com/AlignmentResearch/tuned-lens.
研究の動機と目的
- 逐次推論を通じて、層ごとにトランスフォーマの予測がどのように洗練されるかを調査する。
- 多様な事前学習モデル全体で機能する堅牢な潜在予測デコード法を開発する。
- Bias、パープレキシティ、解釈可能性の観点で、Tuned Lens と Logit Lens を比較する。
- プローブの causal fidelity を示し、悪意のある入力やモデルの変化を検出する有用性を示す。
提案手法
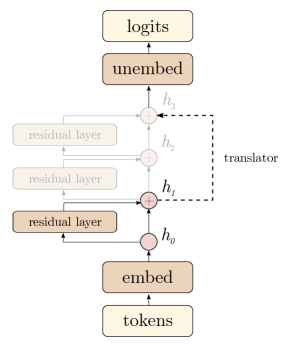
- 各層に対して、hidden states を最終層のアンビエンディング空間へ写像するアフィン翻訳器を訓練する。
- 各層の翻訳された予測を最終層のロジットと整合させるため、蒸留に類似したKL損失を用いる。
- ゼロ残差仮定を学習可能なバイアスに置き換え、Logit Lens の出力の偏りを除去する。
- 複数の自己回帰モデル(最大 20B パラメータ)にわたって評価し、予測軌跡を解析する。
- 出力に影響を与える残差ストリームの方向を特定する因果基底抽出(CBE)を開発する。
- Tuned Lens の介入とモデル出力との刺激-応答の整合性を測るために、Aitchison 幾何を適用する。
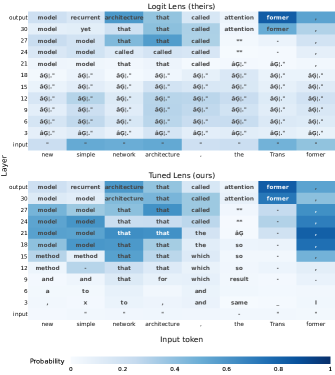
実験結果
リサーチクエスチョン
- RQ1Tuned Lens は、多様なモデルにおいて、Logit Lens よりもより正確で安定した潜在予測を生み出すか?
- RQ2Tuned Lens が選択する特徴は、モデルの最終出力と因果的に整合しているか?
- RQ3Tuned Lens の予測軌跡は異常な入力やプロンプト注入を明らかにできるか?
- RQ4Tuned Lens は層間・モデル・ファインチューニング版間でどれだけうまく転移するか?
- RQ5Tuned Lens に影響を与える潜在方向と、実際のモデル出力に影響を与える方向との関係は何か?
主な発見
- Tuned Lens の予測は、BLOOM、GPT-NeoX-20B、Pythia などのモデル全般において、Logit Lens の予測よりパープレキシティが大幅に低く、バイアスも小さい。
- ある層で訓練されたレンズは近接する層へ低い転送ペナルティで転移し、ファインチューニングされたモデルへ도最小限の劣化で転移する。
- 因果基底抽出は、残差ストリームの方向が Tuned Lens とモデル出力の両方に因果的に影響する方向を明らかにする(高い刺激-応答の整合性)。
- Tuned Lens を用いた予測軌跡は、いくつかのタスクでプロンプト注入攻撃をほぼ完璧な AUROC で検出できる。
- Tuned Lens はファインチューニング中の表現を監視・比較することを可能にし、新しいモデルでプローブを再訓練する必要を最小限に抑える。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。