[論文レビュー] Enabling Factorized Piano Music Modeling and Generation with the MAESTRO\n Dataset
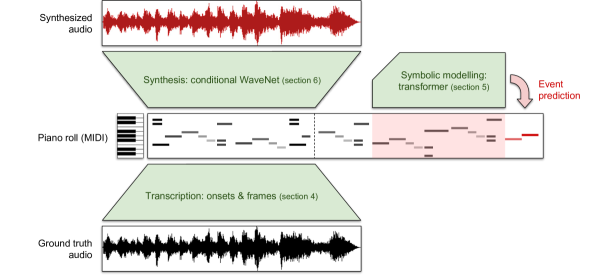
本論文は Wave2Midi2Wave を提案する。因子化されたパイプラインで音声を MIDI に転写し、MIDI を音楽トランスフォーマーでモデル化し、WaveNet を用いて MIDI から音声を合成する。MAESTRO データセットは、整列されたピアノの音声と MIDI の大規模データセットで、正確なアラインメントを可能にする。
Generating musical audio directly with neural networks is notoriously\ndifficult because it requires coherently modeling structure at many different\ntimescales. Fortunately, most music is also highly structured and can be\nrepresented as discrete note events played on musical instruments. Herein, we\nshow that by using notes as an intermediate representation, we can train a\nsuite of models capable of transcribing, composing, and synthesizing audio\nwaveforms with coherent musical structure on timescales spanning six orders of\nmagnitude (~0.1 ms to ~100 s), a process we call Wave2Midi2Wave. This large\nadvance in the state of the art is enabled by our release of the new MAESTRO\n(MIDI and Audio Edited for Synchronous TRacks and Organization) dataset,\ncomposed of over 172 hours of virtuosic piano performances captured with fine\nalignment (~3 ms) between note labels and audio waveforms. The networks and the\ndataset together present a promising approach toward creating new expressive\nand interpretable neural models of music.\n
研究の動機と目的
- 安定で解釈しやすいピアノ音楽生成を、転写・記号モデリング・合成へと問題を因子化して実現・促進する。
- 転写・モデリング・合成の研究を進めるための、大規模で高品質な整列済みピアノ音声-MIDI データセットを提供する。
- ラベルなしの音声から転写 MIDI を介して、最先端のピアノ転写を実証し、エンドツーエンド生成能力を示す。
提案手法
- Factorized modeling: P(audio) ≈ P(audio|notes) P(notes) P(notes|audio) with discrete note latent codes.
- Modules: (1) Encoder: transcription model (Onsets and Frames) to convert audio to MIDI; (2) Prior: autoregressive Music Transformer to model MIDI; (3) Decoder: WaveNet conditioned on MIDI to synthesize audio.
- MAESTRO: a large, aligned dataset of >172 hours of piano performance with ~3 ms audio-MIDI alignment, nine years of International Piano-e-Competition data.
- Dataset alignment: automated audio-MIDI alignment via minimizing distance between real audio CQT frames and synthesized MIDI CQT, followed by segmentation into pieces.
- Training augmentations: audio augmentation during transcription training to improve robustness, with specific parameter ranges.
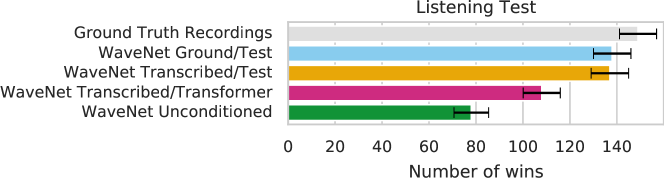
- Evaluation: piano transcription benchmarks; listening tests comparing real, ground-truth-conditioned synthesis, and conditioned WaveNet variants.
実験結果
リサーチクエスチョン
- RQ1長時間スケールで一貫性があり現実的なピアノ音楽を、転写・MIDI 言語モデリング・MIDI 条件付き音声合成へと因子化したパイプラインで生成できるか。
- RQ2MAESTRO は最先端のピアノ転写を可能にし、大規模なラベルなしデータセット上で言語モデリングおよび合成モデルのスケーラブルな訓練を支援するか。
- RQ3オーディオ条件付き WaveNet は MIDI を条件として、音色と長距離の音楽構造をどれだけうまく捉えるか。
- RQ4転写品質とデータ拡張が、転写・言語モデリング・合成の性能に与える影響はどうなるか。
主な発見
- Wave2Midi2Wave システムは、転写・言語モデリング・合成を因子化することで約1分程度の一貫したピアノ音楽を生成できる。
- MAESTRO は172時間超の整列された音声と MIDI を公開しており、転写とエンドツーエンド生成実験を可能にする。
- 転写モデルはピアノ転写ベンチマークで最先端の結果を達成し、MAPS の修正済み Onsets and Frames 設定で従来のベースラインを上回る。
- MAESTRO および転写(MAESTRO-T)で訓練された Music Transformer は検証セットで競争力のあるネガティブ対数尤度を示す(MAESTRO 1.84、MAESTRO-T 1.72)。
- リスニングテストでは、 MIDI で条件付けされた WaveNet ベースの合成が実ピアノ録音のリアリズムに近づくことが示され、特定の構成(Ground/Test、Transcribed/Test)でリスナーに高く評価された。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。