[論文レビュー] Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
要約: 本論文は大規模言語モデルを用いたインコンテキスト学習によるFew-shot Text-to-SQLの性能向上を目指し、構文ベースのデモ選択、スキーマ拡張、投票を提案してSpiderでの実行精度を向上させる。最適プロンプトは最先端を2.5ポイント、最良のファインチューニング済みシステムを5.1ポイント上回る。
In-context learning (ICL) has emerged as a new approach to various natural language processing tasks, utilizing large language models (LLMs) to make predictions based on context that has been supplemented with a few examples or task-specific instructions. In this paper, we aim to extend this method to question answering tasks that utilize structured knowledge sources, and improve Text-to-SQL systems by exploring various prompt design strategies for employing LLMs. We conduct a systematic investigation into different demonstration selection methods and optimal instruction formats for prompting LLMs in the Text-to-SQL task. Our approach involves leveraging the syntactic structure of an example's SQL query to retrieve demonstrations, and we demonstrate that pursuing both diversity and similarity in demonstration selection leads to enhanced performance. Furthermore, we show that LLMs benefit from database-related knowledge augmentations. Our most effective strategy outperforms the state-of-the-art system by 2.5 points (Execution Accuracy) and the best fine-tuned system by 5.1 points on the Spider dataset. These results highlight the effectiveness of our approach in adapting LLMs to the Text-to-SQL task, and we present an analysis of the factors contributing to the success of our strategy.
研究の動機と目的
- LLMsを用いたインコンテキスト学習でText-to-SQLの性能を改善する。
- 類似性と多様性のバランスを取るデモンストレーション選択基準を検討する。
- データベーススキーマ表現と知識拡張でプロンプトを強化する。
- Text-to-SQLにおける成功するプロンプト設計の要因を分析する。
提案手法
- SQL構文の構造を用いてデモを選択し、質問の類似性のみを用いるのではなく比較する。
- データベースを生テキストではなくコード(CREATEクエリ)として表現し、プロンプト構築に用いる。
- 離散的なSQL構文ベクトルを用いたk-meansクラスタリングで多様性を確保しデモを選択する。
- 意味的・構造的なスキーマ情報(オントロジー、列定義、ERサマリ)を用いてプロンプトを拡充する。
- 異なるショット設定からの予測を投票して複数プロンプトを組み合わせ、実行エラーを減らす。
- Codex(code-davinci-002)およびgpt-3.5-turboを用いてSpider他データセットでプロンプトを評価し、実行精度を報告する。
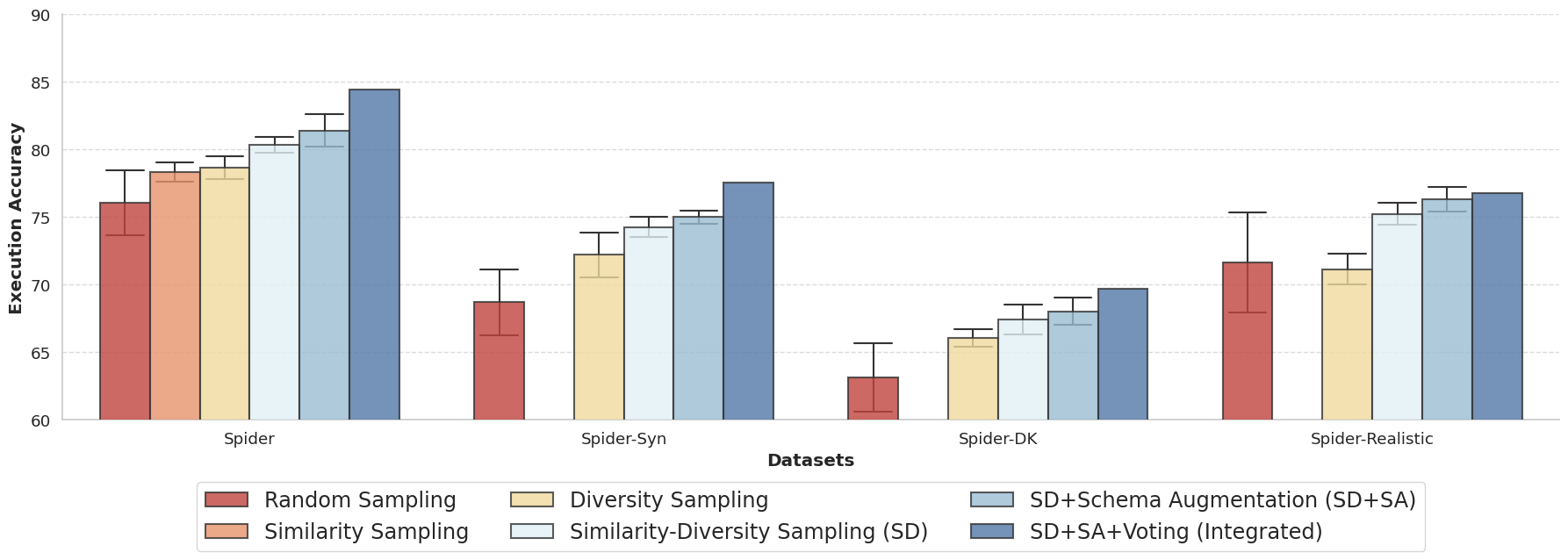
実験結果
リサーチクエスチョン
- RQ1SQL構文に基づくデモ選択はFew-shot Text-to-SQLの性能にどう影響するか。
- RQ2デモンストレーションにおける類似性と多様性のバランスは、Text-to-SQLデータセット全体の実行精度を改善するか。
- RQ3スキーマ関連の知識拡張はゼロショットおよびFew-shot設定でプロンプトの有効性にどのような影響を与えるか。
- RQ4統合投票戦略は異なるプロンプト構成でのロバスト性を向上させるか。
主な発見
| Cov. | Sim. | Score |
|---|---|---|
| Random | 0.38 | 76.03 |
| Similarity | 0.35 | 78.33 |
| Diversity | 0.43 | 78.64 |
| Similarity-Diversity | 0.50 | 80.32 |
- 類似性・多様性のデモ戦略は、ランダム・類似性のみ・多様性のみのアプローチより高い実行精度を示す。
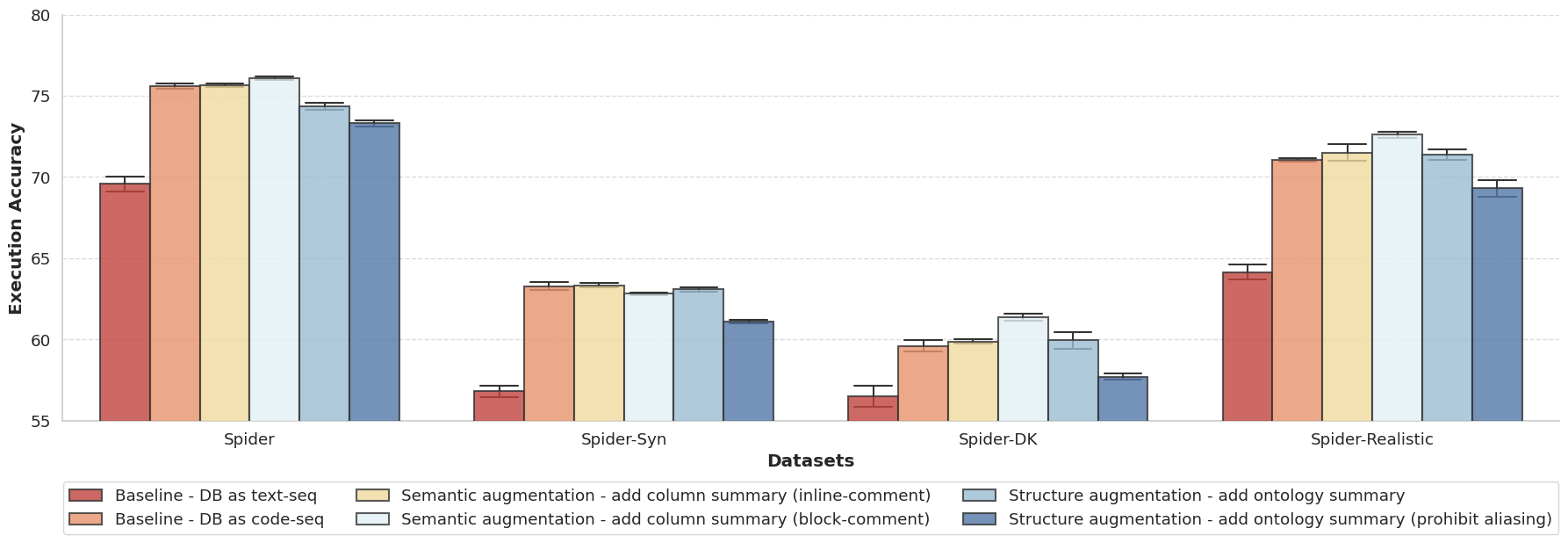
- スキーマ拡張は性能を改善し、意味的拡張(列説明)はゼロショット設定および一部のFew-shotケースで有益。
- データベースを表すのにSQL CREATEクエリを用いる(コード系列)はテキスト系列よりもプロンプト構築において有効。
- 複数のショット設定を跨いだ統合投票アプローチは一貫して結果を改善し、実行エラーを減らす。
- Spider上で提案手法はExecution Accuracy 84.4を達成し、SOTAを2.5ポイント、最良のファインチューニング済みシステムを5.1ポイント上回る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。