[論文レビュー] Evaluating Large Language Models on a Highly-specialized Topic, Radiation Oncology Physics
本研究は、4つの大規模言語モデルを100問の放射線腫瘍物理学試験で評価し、医用物理士および非専門家と比較し、プロンプト戦略、explain-first prompting、および演繹推論テストを探究する。
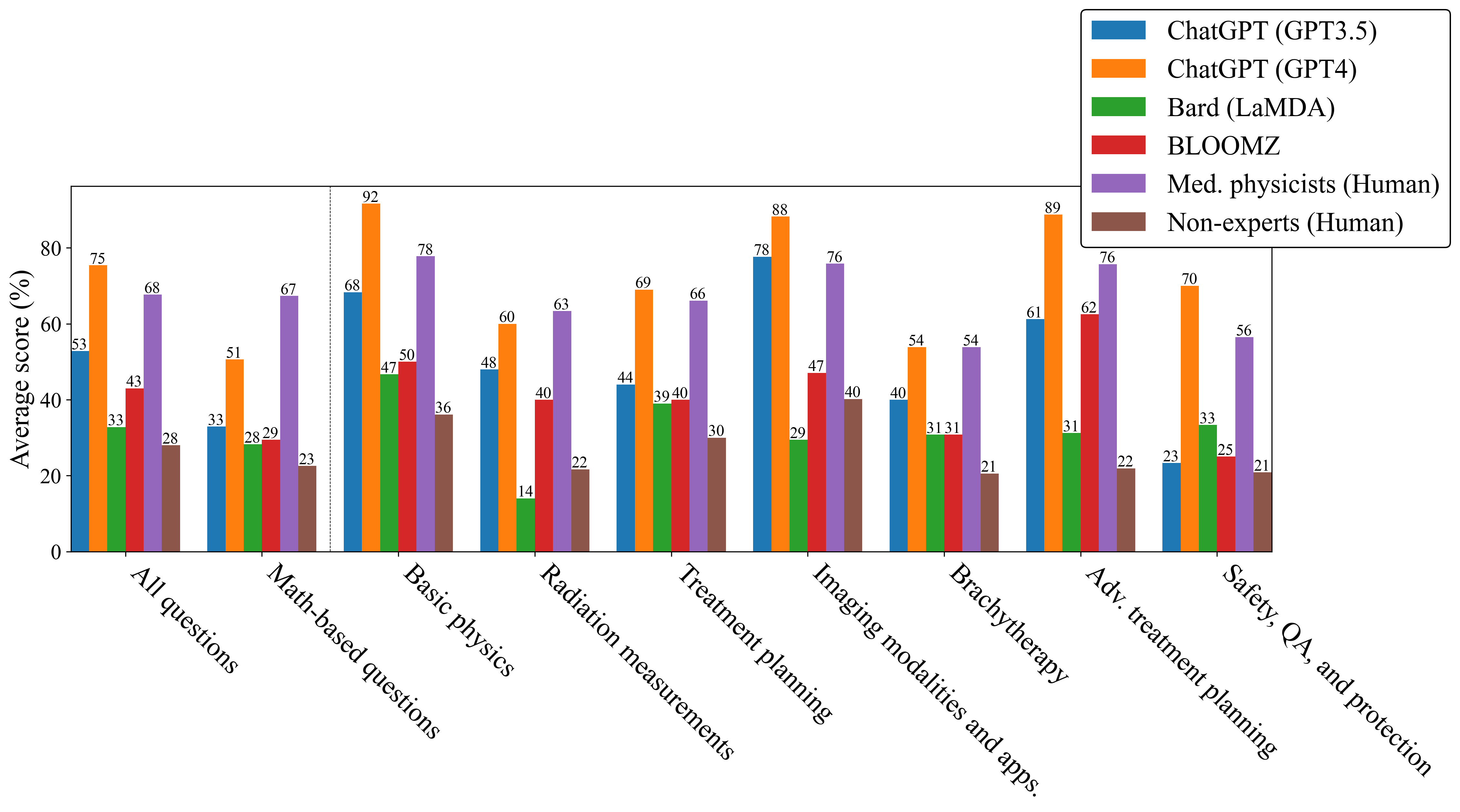
We present the first study to investigate Large Language Models (LLMs) in answering radiation oncology physics questions. Because popular exams like AP Physics, LSAT, and GRE have large test-taker populations and ample test preparation resources in circulation, they may not allow for accurately assessing the true potential of LLMs. This paper proposes evaluating LLMs on a highly-specialized topic, radiation oncology physics, which may be more pertinent to scientific and medical communities in addition to being a valuable benchmark of LLMs. We developed an exam consisting of 100 radiation oncology physics questions based on our expertise at Mayo Clinic. Four LLMs, ChatGPT (GPT-3.5), ChatGPT (GPT-4), Bard (LaMDA), and BLOOMZ, were evaluated against medical physicists and non-experts. ChatGPT (GPT-4) outperformed all other LLMs as well as medical physicists, on average. The performance of ChatGPT (GPT-4) was further improved when prompted to explain first, then answer. ChatGPT (GPT-3.5 and GPT-4) showed a high level of consistency in its answer choices across a number of trials, whether correct or incorrect, a characteristic that was not observed in the human test groups. In evaluating ChatGPTs (GPT-4) deductive reasoning ability using a novel approach (substituting the correct answer with "None of the above choices is the correct answer."), ChatGPT (GPT-4) demonstrated surprising accuracy, suggesting the potential presence of an emergent ability. Finally, although ChatGPT (GPT-4) performed well overall, its intrinsic properties did not allow for further improvement when scoring based on a majority vote across trials. In contrast, a team of medical physicists were able to greatly outperform ChatGPT (GPT-4) using a majority vote. This study suggests a great potential for LLMs to work alongside radiation oncology experts as highly knowledgeable assistants.
研究の動機と目的
- データ豊富な試験バイアスを避けるために、非常に専門的なトピックでLLMsの評価を促す。
- 研修医カリキュラムを反映した100問の放射線腫瘍物理学試験を作成する。
- 複数のLLMを医用物理士および非専門家と比較する。
- プロンプト、説明してから解答する戦略、推論能力を調査する。
提案手法
- 基本物理、測定、治療計画、画像診断、近接療法、高度な計画、QA/安全性を含む100問の多肢選択式試験を設計する。
- 4つのLLM(ChatGPT GPT-3.5, ChatGPT GPT-4, Bard LaMDA, BLOOMZ)を5回の試行で評価(BLOOMZは1回のみ)。
- 初期化および指示プロンプトを用いて回答形式を制御し、可能な場合は20問ずつのバッチで質問を実行する。
- LLMのスコアを医用物理士と非専門家の二つの人間グループと比較し、平均スコア、標準偏差、平均試行相関を用いる。
- LLMと人間の一貫性を評価し、グループのパフォーマンスを評価するために多数決集約を適用する。
- 最初に説明を求め、次に解答させることでGPT-4の精度を向上させる方法を検討し、正解をNone of the aboveに置き換える変換で演繹推論をテストする。

実験結果
リサーチクエスチョン
- RQ1LLMsは医用物理士および非専門家と比較して、非常に専門的な放射線腫瘍物理学の試験に正確に解答できるか?
- RQ2プロンプト設計と explain-first prompting は、専門的な医用物理学内容におけるGPT-4の精度を向上させるか?
- RQ3文脈を減少させた問題に直面したとき、LLMsは演繹推論能力を示すか?
- RQ4人間間またはLLM間の多数決協力は、正確性の向上に有益か?
- RQ5高度に専門的な領域におけるLLMの演繹推論における出現的性質は何か?
主な発見
- GPT-4は100問の試験で平均して他のすべてのLLMと医用物理士を上回った。
- Prompting GPT-4 to explain first, then answer, improved overall accuracy by about 5 percentage points.
- GPT-4 showed notable deductive reasoning in a test where correct answers were replaced with None of the above, achieving 55% overall with explain-then-answer prompting.
- Humans using majority vote substantially outperformed individual LLMs, with medical physicists gaining a 23% boost.
- LLMs exhibited high consistency across trials, whereas non-experts resembled random guessing; medical physicists benefited from group agreement.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。