[論文レビュー] FeCAM: Exploiting the Heterogeneity of Class Distributions in Exemplar-Free Continual Learning
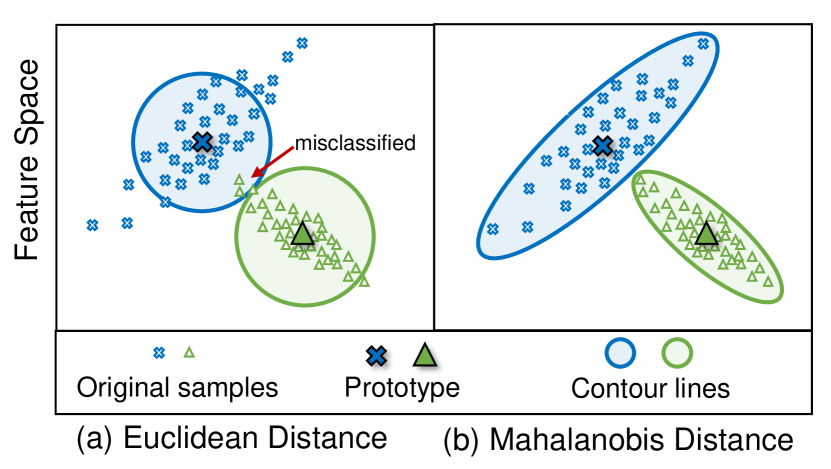
FeCAMは、クラス特異的共分散(マハラノビス距離)を用いるベイズ分類器を導入し、 exemplar-free continual learningにおける特徴分布の異質性を扱い、Euclideanベースのプロトタイプに比べ、多ショット・少ショットのCILおよびドメイン増分タスクで性能を向上させる。
Exemplar-free class-incremental learning (CIL) poses several challenges since it prohibits the rehearsal of data from previous tasks and thus suffers from catastrophic forgetting. Recent approaches to incrementally learning the classifier by freezing the feature extractor after the first task have gained much attention. In this paper, we explore prototypical networks for CIL, which generate new class prototypes using the frozen feature extractor and classify the features based on the Euclidean distance to the prototypes. In an analysis of the feature distributions of classes, we show that classification based on Euclidean metrics is successful for jointly trained features. However, when learning from non-stationary data, we observe that the Euclidean metric is suboptimal and that feature distributions are heterogeneous. To address this challenge, we revisit the anisotropic Mahalanobis distance for CIL. In addition, we empirically show that modeling the feature covariance relations is better than previous attempts at sampling features from normal distributions and training a linear classifier. Unlike existing methods, our approach generalizes to both many- and few-shot CIL settings, as well as to domain-incremental settings. Interestingly, without updating the backbone network, our method obtains state-of-the-art results on several standard continual learning benchmarks. Code is available at https://github.com/dipamgoswami/FeCAM.
研究の動機と目的
- クラス分布の異質性が exemplar-free CILの性能にどのように影響するかを調査する。
- クラス特異的共分散を用いた非等方的(マハラノビス)距離が、Euclidean NCM分類器よりも改善をもたらすかを評価する。
- frozen backbonesと事前訓練特徴量のままでも有効な、共分散を意識したFeCAM分類器を開発する。
- FeCAMの多ショット・少ショット・ドメイン増分連続学習設定への適用性を実証する。
提案手法
- フリーズしたバックボーンを用いてクラスプロトタイプを形成するプロトタイプネットワークを使用する。
- 特徴をクラスプロトタイプと比較する際、非等方的マハラノビス距離(FeCAM)を採用する。
- クラス毎の共分散行列を計算・正規化し、可逆性を確保するため共分散縮小を適用する。
- 共分散推定前に特徴分布を安定化させるため、Tukeyの階段変換を適用する。
- 特徴量間の相関正規化を行い、共分散行列がクラス間・タスク間で比較可能になるようにする。
- クラス共分散を用いたベイズ分類器は、ガウスサンプルから訓練された線形分類器より非線形でより最適な意思決定境界を得られると主張・検証する。
![Figure 1 : Illustration of feature representations in CIL settings. In Joint Training (a), deep neural networks learn good isotropic spherical representations [ 17 ] and thus the Euclidean metric can be used effectively. However, it is challenging to learn isotropic representations of both old and n](https://ar5iv.labs.arxiv.org/html/2309.14062/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1エピソード的な特徴分布の異質性は、特に新しいクラスに対して、 exemplar-free CILにおけるEuclidean NCMの性能を低下させるか。
- RQ2クラスごとの共分散を持つ共分散認識型マハラノビス距離は、従来のEuclidean距離に比べて exemplar-free CILの分類を改善できるか。
- RQ3FeCAMの性能向上には共分散正規化、縮小、Tukey変換といった要素が必須か。
- RQ4FeCAMはバックボーンを更新せずに、多ショット・少ショット・ドメイン増分のベンチマーク全体にわたって一般化しますか。
主な発見
| CIL Method | CIFAR-100 (T=5) Avg Acc | CIFAR-100 (T=10) Avg Acc | CIFAR-100 (T=20) Avg Acc | TinyImageNet (T=5) Avg Acc | TinyImageNet (T=10) Avg Acc | TinyImageNet (T=20) Avg Acc | ImageNet-Subset (T=5) Avg Acc | ImageNet-Subset (T=10) Avg Acc | ImageNet-Subset (T=20) Avg Acc |
|---|---|---|---|---|---|---|---|---|---|
| EWC | 24.5 | 21.2 | 15.9 | 18.8 | 15.8 | 12.4 | - | 20.4 | - |
| LwF-MC | - | - | - | - | - | - | - | - | - |
| DeeSIL | 60.0 | 50.6 | 38.1 | 49.8 | 43.9 | 34.1 | 67.9 | 60.1 | 50.5 |
| MUC | 49.4 | 30.2 | 21.3 | 32.6 | 26.6 | 21.9 | - | - | - |
| SDC | 56.8 | 57.0 | 58.9 | - | - | - | - | - | - |
| PASS | 63.5 | 61.8 | 58.1 | 49.6 | 47.3 | 42.1 | 64.4 | 61.8 | 51.3 |
| IL2A | 66.0 | 60.3 | 57.9 | 47.3 | 44.7 | 40.0 | - | - | - |
| SSRE | 65.9 | 65.0 | 61.7 | 50.4 | 48.9 | 48.2 | - | - | - |
| FeTrIL* | 67.6 | 66.6 | 63.5 | 55.4 | 54.3 | 53.0 | 73.1 | 71.9 | 69.1 |
| Eucl-NCM | 64.8 | 64.6 | 61.5 | 54.1 | 53.8 | 53.6 | 72.2 | 72.0 | 68.4 |
| FeCAM (Σ^{1:t}) | 68.8 | 68.6 | 67.4 | 56.0 | 55.7 | 55.5 | 75.8 | 75.6 | 73.5 |
| FeCAM (Σ_y) | 70.9 | 70.8 | 69.4 | 59.6 | 59.4 | 59.3 | 78.3 | 78.2 | 75.1 |
- 共分散行列Σ^{1:t}を用いたFeCAMは、CIFAR-100、TinyImageNet、ImageNet-Subsetの従来の exemplar-free CIL 手法を既に上回っている。
- クラスごとの共分散行列(Σ_y)を用いると、平均増分精度がさらに改善され、共分散を共通とする変種を上回る。
- クラスごとの共分散を用いたFeCAMは、エンドタスクの精度を高く保ちつつ、ドメイン増分CoRe50を含む全タスクで強力な性能を維持する。
- 共分散情報を活用するベイズ分類器は、ガウス特徴をサンプリングして線形分類器を訓練する方法よりも、著しく高い精度を発揮する。
- 共分散正規化(式7)と共分散縮小(式8)は、旧クラスと新クラス間の分散シフトを処理し、可逆性を確保するうえで重要である。
- FeCAMは事前訓練済みバックボーン(ViT)にも良くスケールし、バックボーン更新なしで複数のベンチマークで最先端の結果を達成する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。