[論文レビュー] FedAIoT: A Federated Learning Benchmark for Artificial Intelligence of Things
FedAIoTを導入し、AIoT向けのFLベンチマークを提供。 eight IoT-derived datasetsとエンドツーエンドのフレームワークを用い、データヘテロ次性、FLオプティマ、クライアントサンプリング、ラベルノイズ、量子化を分析する。
There is a significant relevance of federated learning (FL) in the realm of Artificial Intelligence of Things (AIoT). However, most existing FL works do not use datasets collected from authentic IoT devices and thus do not capture unique modalities and inherent challenges of IoT data. To fill this critical gap, in this work, we introduce FedAIoT, an FL benchmark for AIoT. FedAIoT includes eight datasets collected from a wide range of IoT devices. These datasets cover unique IoT modalities and target representative applications of AIoT. FedAIoT also includes a unified end-to-end FL framework for AIoT that simplifies benchmarking the performance of the datasets. Our benchmark results shed light on the opportunities and challenges of FL for AIoT. We hope FedAIoT could serve as an invaluable resource to foster advancements in the important field of FL for AIoT. The repository of FedAIoT is maintained at https://github.com/AIoT-MLSys-Lab/FedAIoT.
研究の動機と目的
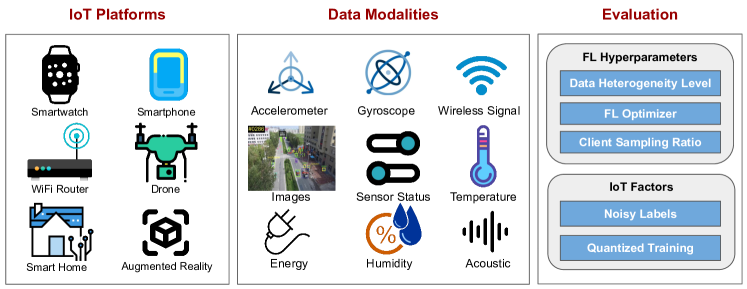
- 異なるモダリティとアプリケーションを網羅する八つの authentic IoTデータセットを提供し、AIoTにおける連合学習のためのデータ分散を促進する。
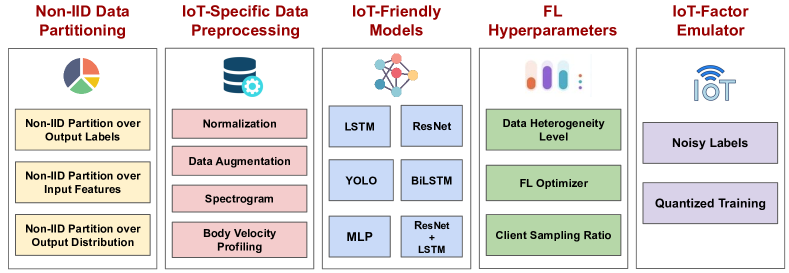
- 非IIDデータ分割、前処理、IoTに適したモデル、ハイパーパラメータ、IoTファクター仮想化を含む統一的なエンドツーエンドFLフレームワークを提供する。
- さまざまな非IID性、オプティマ、クライアントサンプリング比率の下でデータセット間のFL性能をベンチマークし、機会と課題を明らかにする。
- 誤ラベル耐性と量子化(FP32対 FP16)によるIoTデバイスでの学習影響を検討する。
提案手法
- Accelerometer、無線信号、ドローン画像、音声、スマートホームセンサーなどのモダリティを含む八つのIoT由来データセットをキュレーションする。
- 分類、回帰、検出タスクに合わせた三つの非IIDデータ分割方式を提案する。
- リソース制約デバイスに適したAIoT対応モデルを設計する(例:LSTM、ResNet18、YOLOv8n、BiLSTM、MLP)。
- データ前処理、ハイパーパラメータ、IoTファクターエミュレーターを網羅するエンドツーエンドFLフレームワークを統合する。
- 誤ラベルを Centralized-trained confusion matrix によってエミュレートする等の現実的なIoTファクターを組み込み、メモリ効率のためのFP16量子化トレーニングをサポートする。
実験結果
リサーチクエスチョン
- RQ1データヘテロ性(非IID性)は、さまざまなAIoTタスクとモダリティ全体のFL性能にどう影響するのか?
- RQ2標準的なFLオプティマ(FedAvg、FedOPT)は異なるヘテロ性下でどう比較されるのか、クライアントサンプリング比は精度と収束にどのように影響するのか?
- RQ3誤ラベルと量子化トレーニングがAIoTデータセットのFL性能に与える影響は?
- RQ4どのIoTモダリティとタスクが量子化とレジリエントな学習戦略から最も恩恵を受けるのか?
主な発見
- FedAvgは低ヘテロ性下でより安定した性能を示し、中央集権的な結果に近づくことが多い。一方、FedOPTは高ヘテロ性下で複数のデータセットで発散する可能性がある。
- クライアントサンプリング比が高いほど最終精度が向上する傾向があるが、収束を必ずしも速めるとは限らず、モダリティ依存の効果がある。
- 誤ラベルはUT-HARやEPIC-SOUNDSなどのいくつかのデータセットで性能を大幅に低下させる。ラベルノイズ耐性を持つFL手法の必要性を示す。
- 量子化トレーニング(FP16)はメモリ使用量を大幅に削減(60%以上)し、精度にはデータセット間で混在した影響を与える。あるデータセットはFP32と同等以上の性能を維持するが、他は影響を受ける。
- ベンチマークは、ヘテロ性、ノイズ、圧縮に対するデータセットおよびモダリティ特有の耐性を強調し、AIoTにおける特化したFL戦略の必要性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。