[論文レビュー] Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
本論文は、知識をLLMに注入する手法として、無監督微調整と取得拡張生成(RAG)を比較し、RAGが一貫して微調整を上回すこと、未知の知識を含む場合でも上回ることを示している。
Large language models (LLMs) encapsulate a vast amount of factual information within their pre-trained weights, as evidenced by their ability to answer diverse questions across different domains. However, this knowledge is inherently limited, relying heavily on the characteristics of the training data. Consequently, using external datasets to incorporate new information or refine the capabilities of LLMs on previously seen information poses a significant challenge. In this study, we compare two common approaches: unsupervised fine-tuning and retrieval-augmented generation (RAG). We evaluate both approaches on a variety of knowledge-intensive tasks across different topics. Our findings reveal that while unsupervised fine-tuning offers some improvement, RAG consistently outperforms it, both for existing knowledge encountered during training and entirely new knowledge. Moreover, we find that LLMs struggle to learn new factual information through unsupervised fine-tuning, and that exposing them to numerous variations of the same fact during training could alleviate this problem.
研究の動機と目的
- 事前学習済みのLLMに対して、知識集約的なタスクへ知識をどの程度うまく注入できるかを評価する。
- 知識注入手法として、無監督微調整と取得拡張生成(RAG)を比較する。
- 既知の知識と新規の知識の両方の状況で性能を評価する。
- 新しい事実の学習に対するデータ拡張(パラフレーズ)の影響を調査する。
- 実務における知識注入の際に、どのアプローチがより信頼性が高いかについて指針を提供する。
提案手法
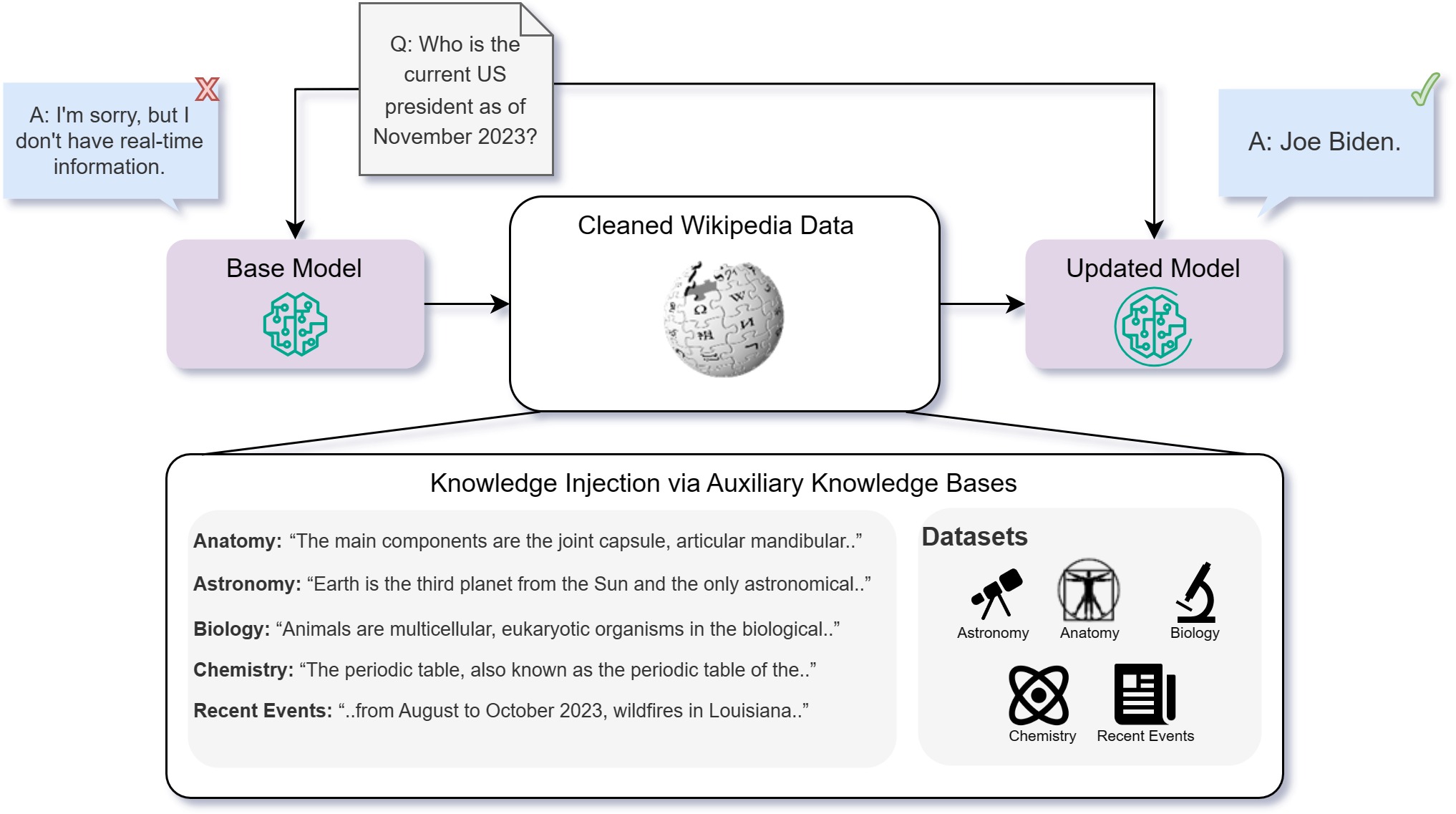
- 質問応答(Q&A)レンズと知識ベース B_Q を用いた知識注入フレームワークを定義する。
- 事前学習済みモデル M と基礎知識に適用される2つの変換 F を比較する:微調整(FT)と取得拡張生成(RAG)。
- 知識を注入するために、低い学習率で無監督微調整(継続的事前学習)を実装する。
- 事前学習済み埋め込みモデル(faissベースのベクトルストア)を用いたRAGで、B_Q から上位K文書を取得し入力クエリを拡張する。
- トピックごとにWikipediaから補助知識ベースを作成し、QAデータセットとパラフレーズベースの拡張を頑健性のために行う。
- MMLUの科目と時事データセットでLM-Evaluation-Harnessフレームワークを用いて評価し、0-shotおよび5-shot設定を用いる。
実験結果
リサーチクエスチョン
- RQ1知識集約的なタスク全般において、LLM への知識注入に関してRAGは無監督微調整より優れているか?
- RQ2無監督微調整は新しい事実情報を効果的に学習できるか、あるいは既知・新規の事実の双方についてRAGのほうが信頼性が高いか?
- RQ3パラフレーズによるデータ拡張は、微調整を通じて新しい知識を学習し記憶する能力を向上させるか?
- RQ40-shotと5-shotの設定が、FTとRAGの知識注入性能にどのように影響するか?
主な発見
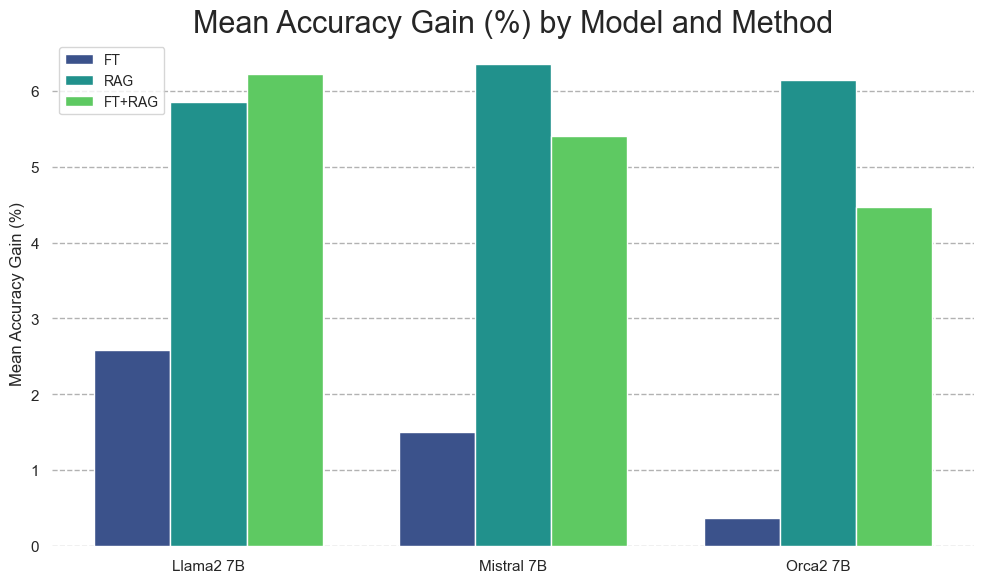
- RAGは一貫してベースモデルを上回り、MMLUタスクと時事問題全般で無監督微調整を上回ることが多い。
- 微調整はベースモデルより改善をもたらすが、RAGには及ばず、FTとRAGを組み合わせると不安定になることがある。
- パラフレーズベースのデータ拡張は時事問題の性能を単調に向上させ、反復を通じて新しい情報の学習を支援する。
- 微調整による新しい情報の学習は複数のパラフレーズのバリエーションから恩恵を受け、フォーマットを変えて繰り返すことが知識獲得に役立つことを示唆している。
- 時事データの結果は、補助データセットが質問と密接に一致する場合にRAGが特に有効であることを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。