[論文レビュー] Generative models improve fairness of medical classifiers under distribution shifts
本論文は、拡散型生成モデルをラベルや敏感属性で条件付けしてトレーニングデータを増強することが、分布シフトの下で、組織病理学、胸部放射線学、および皮膚科の医療分類器の頑健性と公正性を向上させることを示している。
A ubiquitous challenge in machine learning is the problem of domain generalisation. This can exacerbate bias against groups or labels that are underrepresented in the datasets used for model development. Model bias can lead to unintended harms, especially in safety-critical applications like healthcare. Furthermore, the challenge is compounded by the difficulty of obtaining labelled data due to high cost or lack of readily available domain expertise. In our work, we show that learning realistic augmentations automatically from data is possible in a label-efficient manner using generative models. In particular, we leverage the higher abundance of unlabelled data to capture the underlying data distribution of different conditions and subgroups for an imaging modality. By conditioning generative models on appropriate labels, we can steer the distribution of synthetic examples according to specific requirements. We demonstrate that these learned augmentations can surpass heuristic ones by making models more robust and statistically fair in- and out-of-distribution. To evaluate the generality of our approach, we study 3 distinct medical imaging contexts of varying difficulty: (i) histopathology images from a publicly available generalisation benchmark, (ii) chest X-rays from publicly available clinical datasets, and (iii) dermatology images characterised by complex shifts and imaging conditions. Complementing real training samples with synthetic ones improves the robustness of models in all three medical tasks and increases fairness by improving the accuracy of diagnosis within underrepresented groups. This approach leads to stark improvements OOD across modalities: 7.7% prediction accuracy improvement in histopathology, 5.2% in chest radiology with 44.6% lower fairness gap and a striking 63.5% improvement in high-risk sensitivity for dermatology with a 7.5x reduction in fairness gap.
研究の動機と目的
- 医用機械学習モデルにおける分布シフトと潜在的なバイアスを動機づけ、対処する。
- サブグループのデータ分布をモデル化するために拡散モデルを用いたラベル効率の良い拡張手法を開発する。
- 学習された拡張がヒューリスティックな拡張を上回り、精度を犠牲にせず公正性を改善できることを示す。
- 難易度と解像度が異なる複数の画像モダリティにわたってこの手法の一般化を示す。
提案手法
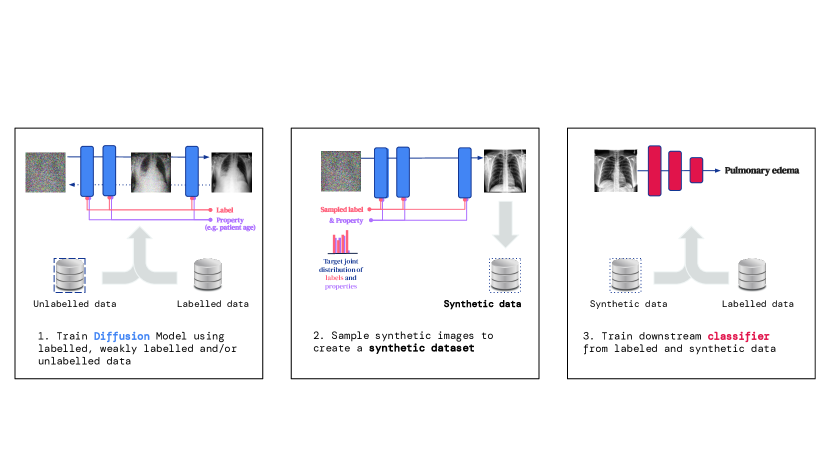
- 診断ラベルまたは診断ラベルと敏感属性の両方に条件付けて、ラベル付きデータとラベルなしデータの両方で拡散モデルを学習させる。
- 拡散モデルから公正なサンプリング戦略に従って合成画像をサンプリングする。
- 実データのラベル付きデータと合成データの混合で下流の分類器を学習し、混合比をハイパーパラメータとする。
実験結果
リサーチクエスチョン
- RQ1ラベルと敏感属性で拡散モデルの拡張を条件付けることは、分布シフト下で性能を向上させるか。
- RQ2学習された拡張は組織病理学、胸部放射線学、皮膚科のサブグループ間の公正性の差を縮小するか。
- RQ3高解像度・難易度の高い皮膚科タスクにおける本手法の性能は、他のベースラインと比較してどうか。
- RQ4合成データを色拡張や他のヒューリスティックと組み合わせることが、精度と公正性に与える影響は何か。
主な発見
- 合成データとカラー拡張を用いた場合、組織病理学のテストセット精度が7.7パーセンテージポイント向上。
- 分布外の胸部放射線学で平均AUCが5.2パーセントポイント改善、フェアネスギャップを44.6%低減。
- 分布シフト下の皮膚科でハイリスク感度が63.5%改善、フェアネスギャップを7.5倍削減。
- 拡散ベースの拡張はベースラインを上回り、モダリティと分布シフトのシナリオ全体で公正性ギャップを縮小する。
- 高解像度の皮膚科結果では連鎖型拡散アップサンプリングを256x256に適用し、OOD設定で顕著な向上を達成。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。