[論文レビュー] GPT as Knowledge Worker: A Zero-Shot Evaluation of (AI)CPA Capabilities
この論文はGPT-3.5(text-davinci-003)を2つのCPA式評価から実験的に評価し、AICPA Blueprintsに基づくゼロショット能力を財務、法務、会計、倫理のタスクで測定しています。算術的課題は控えめだが、Assessment 2での全体の正確度は約57%近く、トップ2の解答正確性で高い非含意を示します。
The global economy is increasingly dependent on knowledge workers to meet the needs of public and private organizations. While there is no single definition of knowledge work, organizations and industry groups still attempt to measure individuals' capability to engage in it. The most comprehensive assessment of capability readiness for professional knowledge workers is the Uniform CPA Examination developed by the American Institute of Certified Public Accountants (AICPA). In this paper, we experimentally evaluate OpenAI's `text-davinci-003` and prior versions of GPT on both a sample Regulation (REG) exam and an assessment of over 200 multiple-choice questions based on the AICPA Blueprints for legal, financial, accounting, technology, and ethical tasks. First, we find that `text-davinci-003` achieves a correct rate of 14.4% on a sample REG exam section, significantly underperforming human capabilities on quantitative reasoning in zero-shot prompts. Second, `text-davinci-003` appears to be approaching human-level performance on the Remembering & Understanding and Application skill levels in the Exam absent calculation. For best prompt and parameters, the model answers 57.6% of questions correctly, significantly better than the 25% guessing rate, and its top two answers are correct 82.1% of the time, indicating strong non-entailment. Finally, we find that recent generations of GPT-3 demonstrate material improvements on this assessment, rising from 30% for `text-davinci-001` to 57% for `text-davinci-003`. These findings strongly suggest that large language models have the potential to transform the quality and efficiency of future knowledge work.
研究の動機と目的
- GPT-3.5(text-davinci-003)のAICPA Uniform CPA Examination Blueprintsに基づく知識作業タスクのゼロショット性能を評価する。
- 4つのCPAセクション(AUD、BEC、FAR、REG)および2つの評価デザインに渡る能力を評価する。
- 再現とさらなる研究を可能にするオープンソースデータとプロンプトを提供する。
- GPT-3.5の性能を古いGPT-3世代および利用可能な人間のベースラインと比較する。
提案手法
- CPA試験の構造を模した2つの評価:Assessment 1(算術的推論を含む規制重視)とAssessment 2(208問のMCQが4つのBlueprints全体をカバー)。
- text-davinci-003のゼロショット promptingを用い、さまざまなプロンプト、文脈付け、正当化戦略を組み合わせ;ハイパーパラメータを複数設定(temperature 0.0/0.5/1.0; best_of 1/2/4)。
- 従来のGPT-3モデル(text-davinci-001、curie、babbage、ada)との比較で進歩を示す。
- Assessment 2のオープンソースのソースコードと問題を提供;再現性の詳細は補足情報に記載。
実験結果
リサーチクエスチョン
- RQ1ゼロショット設定で知識労働者として多分野横断のCPA領域でGPT-3.5は機能するか。
- RQ2CPAセクション(AUD、BEC、FAR、REG)および評価デザイン(定量的対定性的タスク)によってゼロショットのGPT-3.5性能はどのように異なるか。
- RQ3専門知識タスクにおけるプロンプト設計とモデルハイパーパラメータがゼロショット性能に与える影響は。
- RQ4GPT-3.5のトップツー正解率はセクション間の単一回答正解率および推測ベースラインと比較してどうか。
主な発見
| Section | Accuracy | Accuracy - Top Two |
|---|---|---|
| AUD | 57.1% | 84.9% |
| BEC | 69.7% | 85.7% |
| FAR | 51.0% | 82.4% |
| REG | 53.1% | 75.8% |
- GPT-3.5はAssessment 1の規制重視・算術重視タスクで14.4%の正解率を示し、定量的推論で人間受験者を下回る。
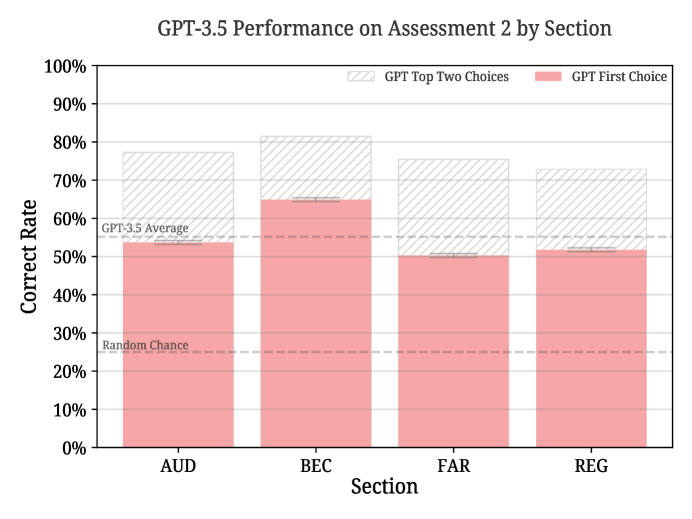
- Assessment 2(全セクションを跨ぐ208問MCQ)ではGPT-3.5は51.1%-57.6%の正解率を達成し、平均約57%でトップ2正解は約82%である。
- セクション別の最良プロンプト/パラメータでの性能:AUD 57.1%(トップツー 84.9%)、BEC 69.7%(85.7%)、FAR 51.0%(82.4%)、REG 53.1%(75.8%)。
- GPT-3.5は強い非含意(トップツー正解性)を示し、説明の向上した説明が得られる一方で、参考文献の幻覚は説明の約37%で発生。
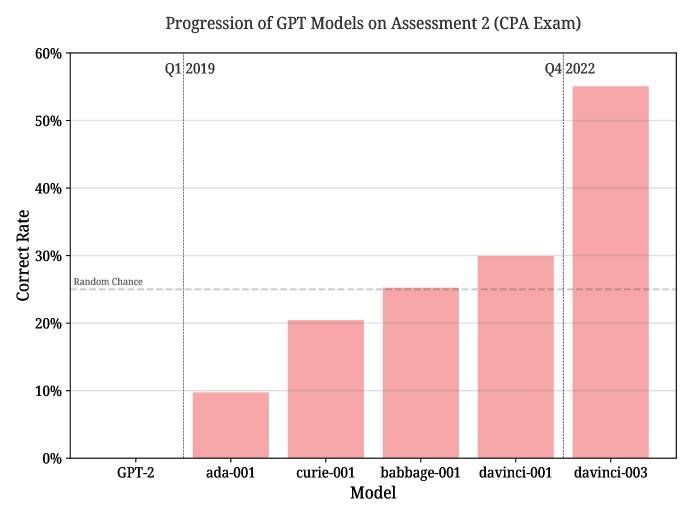
- GPT-3世代の進行に伴い、text-davinci-003はこの知識作業タスク群でtext-davinci-001および従来モデルを大幅に上回る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。