[論文レビュー] Guiding Large Language Models via Directional Stimulus Prompting
DSP は、小さな調整可能なポリシーモデルを用いて、インスタンス固有の方向性プロンプトを生成し、ブラックボックス型の LLM を望ましい出力へと導く。要約、対話、推論タスクにおいて、限られたラベル付きデータで性能を向上させる。
We introduce Directional Stimulus Prompting, a novel framework for guiding black-box large language models (LLMs) toward specific desired outputs. Instead of directly adjusting LLMs, our method employs a small tunable policy model (e.g., T5) to generate an auxiliary directional stimulus prompt for each input instance. These directional stimulus prompts act as nuanced, instance-specific hints and clues to guide LLMs in generating desired outcomes, such as including specific keywords in the generated summary. Our approach sidesteps the challenges of direct LLM tuning by optimizing the policy model to explore directional stimulus prompts that align LLMs with desired behaviors. The policy model can be optimized through 1) supervised fine-tuning using labeled data and 2) reinforcement learning from offline or online rewards based on the LLM's output. We assess our method across summarization, dialogue response generation, and chain-of-thought reasoning tasks. Our experiments demonstrate that the framework consistently improves LLMs' (e.g., ChatGPT, Codex, InstructGPT) performance on these supervised tasks using minimal labeled data. Notably, using just 80 dialogues on the MultiWOZ dataset, our approach enhances ChatGPT's performance by an impressive 41.4%, matching or surpassing some fully supervised start-of-the-art models. Additionally, the instance-specific chain-of-thought prompt generated by our approach improves InstructGPT's reasoning accuracy compared to human-crafted or automatically generated prompts. The code and data are publicly available at \url{https://github.com/Leezekun/Directional-Stimulus-Prompting}.
研究の動機と目的
- ブラックボックス LLM をファインチューニングせずに誘導する軽量手法を動機づける。
- プロンプトにインスタンス固有のヒントを提供する方向刺激を導入する。
- 小さなポリシーモデルを、教師付きファインチューニングと強化学習によって最適化できることを示す。
- 要約、対話応答生成、連鎖思考推論の改善を示す。
提案手法
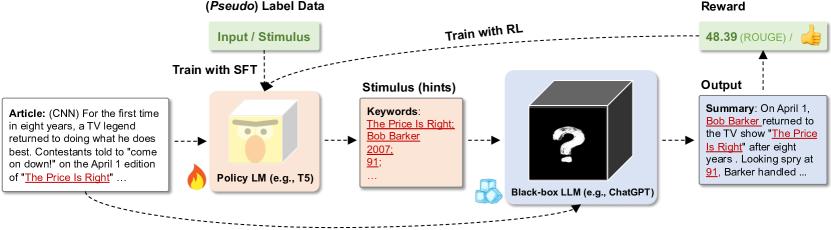
- 入力 x ごとに方向刺激 z を生成する調整可能な小さなポリシーモデルを導入する。
- 刺激 z を x に連結してブラックボックス LLM のプロンプトを形成する。LLM のパラメータにはアクセスできない。
- x, z* のペアに対して教師ありファインチューニングでポリシーモデルを訓練し、 downstream 報酬 R を最適化するために強化学習を任意で適用する。
- R を LLM の出力に基づいて定義する(例:要約には ROUGE、対話にはタスク成功指標、連鎖思考の有効性など)。
- 大規模なアクション空間に対応するためにトップ-p マスキングを用いた PPO(NLPO 変種)を用い、初期化からポリシーを近づけるために KL 発散ペナルティを適用する。

実験結果
リサーチクエスチョン
- RQ1小さなポリシーモデルは、ブラックボックス LLM を望ましい出力へと誘導するインスタンス固有のプロンプトを生成できるか。
- RQ2方向刺激の RL ベースの最適化は、監督付きプロンプトより LLM の誘導で優れているか。
- RQ3限られたラベル付きデータで、要約・対話システム・連鎖思考タスクの改善は一貫しているか。
主な発見
| Method | #Training data | MultiWOZ 2.0 Inform | MultiWOZ 2.0 Succ. | MultiWOZ 2.0 BLEU | MultiWOZ 2.0 Comb. | MultiWOZ 2.1 Inform | MultiWOZ 2.1 Succ. | MultiWOZ 2.1 BLEU | MultiWOZ 2.1 Comb. |
|---|---|---|---|---|---|---|---|---|---|
| Codex Standard Prompting | - | 76.7 | 41.5 | 7.7 | 66.8 | 74.2 | 41.9 | 7.8 | 65.9 |
| DSP w/ SFT | 1% (80) | 74.9 | 66.3 | 11.1 | 81.7 | 72.0 | 66.0 | 11.3 | 80.1 |
| DSP w/ SFT+RL | 1% (80) | 91.0 | 76.0 | 9.8 | 93.3 | 89.7 | 78.6 | 9.4 | 93.4 |
| DSP w/ SFT | 10% (800) | 79.4 | 71.9 | 11.3 | 87.0 | 72.0 | 67.0 | 13.1 | 82.6 |
| DSP w/ SFT+RL | 10% (800) | 96.0 | 86.9 | 10.7 | 102.2 | 94.0 | 86.0 | 9.2 | 99.2 |
| ChatGPT Standard Prompting | - | 71.8 | 44.1 | 10.5 | 68.4 | 72.8 | 44.2 | 10.4 | 68.9 |
| DSP w/ SFT | 1% (80) | 76.6 | 66.5 | 11.2 | 82.8 | 76.0 | 64.3 | 11.3 | 81.4 |
| DSP w/ SFT+RL | 1% (80) | 90.9 | 82.2 | 10.2 | 96.7 | 87.3 | 78.7 | 10.7 | 93.7 |
| DSP w/ SFT | 10% (800) | 72.7 | 64.7 | 11.8 | 80.5 | 75.0 | 67.7 | 12.6 | 83.9 |
| DSP w/ SFT+RL | 10% (800) | 95.3 | 82.3 | 10.9 | 99.6 | 95.0 | 84.0 | 10.7 | 100.2 |
- DSP は最小限のラベル付きデータにもかかわらず、要約、対話、および推論タスクで LLM の性能を向上させる。
- 要約では、CNN/Daily Mail の 4,000 件のラベル付きペアで ChatGPT に対して ROUGE/BLEU が 4-13% 向上。
- MultiWOZ 対話で RL 指導のプロンプトを用いると、わずか 80 対話で ChatGPT の総合指標が最大 41.4% 向上。
- DSP によって生成されたインスタンス固有の連鎖思考トリガは、InstructGPT のための人手作成または自動生成プロンプトを上回った。
- RL ファインチューニングは SFT のみを上回る利得を一貫して生み出し、特に訓練データ量が増えると顕著になる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。