[論文レビュー] Harnessing Artificial Intelligence to Combat Online Hate: Exploring the Challenges and Opportunities of Large Language Models in Hate Speech Detection
この論文は、 HateCheck データセットに対して GPT-3.5、Llama-2、Falcon をゼロショットのヘイトスピーチ検出器として実証的に評価し、 prompting 戦略を分析し、LLMベースのヘイトスピーチ分類の頑健性とバイアスを議論する。
Large language models (LLMs) excel in many diverse applications beyond language generation, e.g., translation, summarization, and sentiment analysis. One intriguing application is in text classification. This becomes pertinent in the realm of identifying hateful or toxic speech -- a domain fraught with challenges and ethical dilemmas. In our study, we have two objectives: firstly, to offer a literature review revolving around LLMs as classifiers, emphasizing their role in detecting and classifying hateful or toxic content. Subsequently, we explore the efficacy of several LLMs in classifying hate speech: identifying which LLMs excel in this task as well as their underlying attributes and training. Providing insight into the factors that contribute to an LLM proficiency (or lack thereof) in discerning hateful content. By combining a comprehensive literature review with an empirical analysis, our paper strives to shed light on the capabilities and constraints of LLMs in the crucial domain of hate speech detection.
研究の動機と目的
- LLM がヘイトスピーチ検出器およびアノテータとしてどのように機能するかを検討する。
- ヘイトスピーチ検出性能において、オープンソースと独自(商用)LLMを実証的に比較する。
- prompting 戦略と分類有効性への影響を調査する。
- LLMをヘイトスピーチのモデレーションに展開する際の制限事項、バイアス、ベストプラクティスを特定する。
提案手法
- LLMをテキスト分類器およびヘイトスピーチ検出器として扱う文献の調査(LLM以前の時代対LLM時代)。
- HateCheck におけるゼロショットのヘイトスピーチ検出を用いた GPT-3.5、Llama-2、Falcon の実証的評価。
- 直接的で簡潔なプロンプト、コンテキストプロンプト、およびGPT-3.5を用いた思考過程プロンプトを含むプロンプト設計実験。
- LLM出力をヘイト/非ヘイトラベルへマッピングする分類ラベリング戦略。
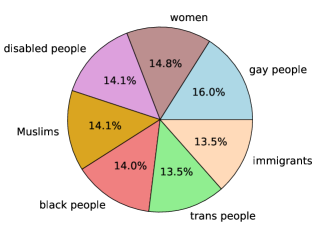
- 方向性およびターゲットバイアスのための HateCheck アノテーションを用いた誤り分析。
実験結果
リサーチクエスチョン
- RQ1RQ1: 一般的なヘイトスピーチとターゲットを絞ったカテゴリの検出において、LLMはどれくらい頑健ですか?
- RQ2RQ2: prompting 技術はLLMのヘイトスピーチ検出の有効性にどのように影響しますか?
主な発見
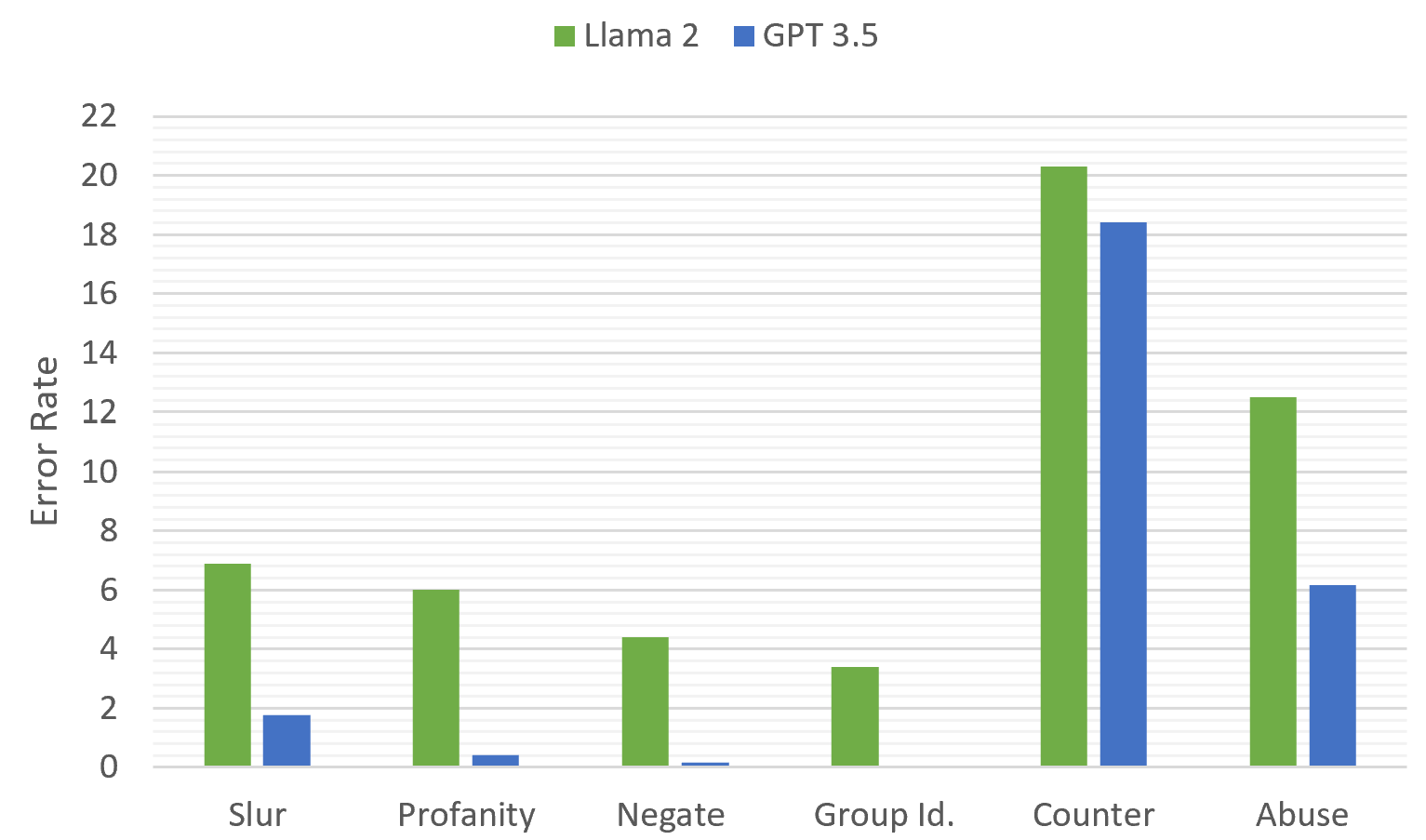
| LLM | ヘイト P | ヘイト R | ヘイト F1 | 非ヘイト P | 非ヘイト R | 非ヘイト F1 | 精度 | AUROC |
|---|---|---|---|---|---|---|---|---|
| Falcon | 0.69 | 0.43 | 0.53 | 0.30 | 0.56 | 0.40 | 0.47 | 0.49 |
| Llama 2 | 0.80 | 1.00 | 0.89 | 0.99 | 0.46 | 0.63 | 0.83 | 0.73 |
| GPT 3.5 | 0.89 | 0.98 | 0.93 | 0.93 | 0.73 | 0.82 | 0.89 | 0.85 |
- GPT-3.5 は、テスト対象モデルの中で総合的なヘイトスピーチ検出性能が最も高い(報告された F1 など 83? から 93?)、Llama-2 は GPT-3.5 の性能に接近。
- Llama-2 (7B) はヘイトスピーチ検出に強力だが、非ヘイト内容を識別する際に虚偽の相関により依存する傾向を示す。
- Falcon は ヘイトスピーチ分類では GPT-3.5 および Llama-2 に対して性能が劣る。
- prompting の影響: 直接的で簡潔なプロンプトが全体的に最良の性能をもたらす一方で、コンテキストプロンプトや思考過程プロンプトは一貫して結果を改善しない。
- 誤り分析は、指向型と一般型のヘイトスピーチの扱いの違い、および対象となるヘイトのターゲット(例: 女性、ムスリムなど)における性能の差を示す。
- 研究は潜在的なガードレール相互作用と、虚偽の手掛かりを軽減するためのラベリング機能とバランスの取れたファインチューニングの重要性を強調している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。