[論文レビュー] IML-ViT: Benchmarking Image Manipulation Localization by Vision Transformer
IML-ViT は高解像度を保持する ViT ベースの画像操作局在モデルを導入し、多段 supervision, エッジに焦点を当てた監督を使用し、複数の公開データセットで最先端の結果を達成する。IML の新しいベンチマークとして提案される。
Advanced image tampering techniques are increasingly challenging the trustworthiness of multimedia, leading to the development of Image Manipulation Localization (IML). But what makes a good IML model? The answer lies in the way to capture artifacts. Exploiting artifacts requires the model to extract non-semantic discrepancies between manipulated and authentic regions, necessitating explicit comparisons between the two areas. With the self-attention mechanism, naturally, the Transformer should be a better candidate to capture artifacts. However, due to limited datasets, there is currently no pure ViT-based approach for IML to serve as a benchmark, and CNNs dominate the entire task. Nevertheless, CNNs suffer from weak long-range and non-semantic modeling. To bridge this gap, based on the fact that artifacts are sensitive to image resolution, amplified under multi-scale features, and massive at the manipulation border, we formulate the answer to the former question as building a ViT with high-resolution capacity, multi-scale feature extraction capability, and manipulation edge supervision that could converge with a small amount of data. We term this simple but effective ViT paradigm IML-ViT, which has significant potential to become a new benchmark for IML. Extensive experiments on three different mainstream protocols verified our model outperforms the state-of-the-art manipulation localization methods. Code and models are available at https://github.com/SunnyHaze/IML-ViT.
研究の動機と目的
- Image Manipulation Localization (IML) と従来のセグメンテーションとの間の主要な相違点を特定する。
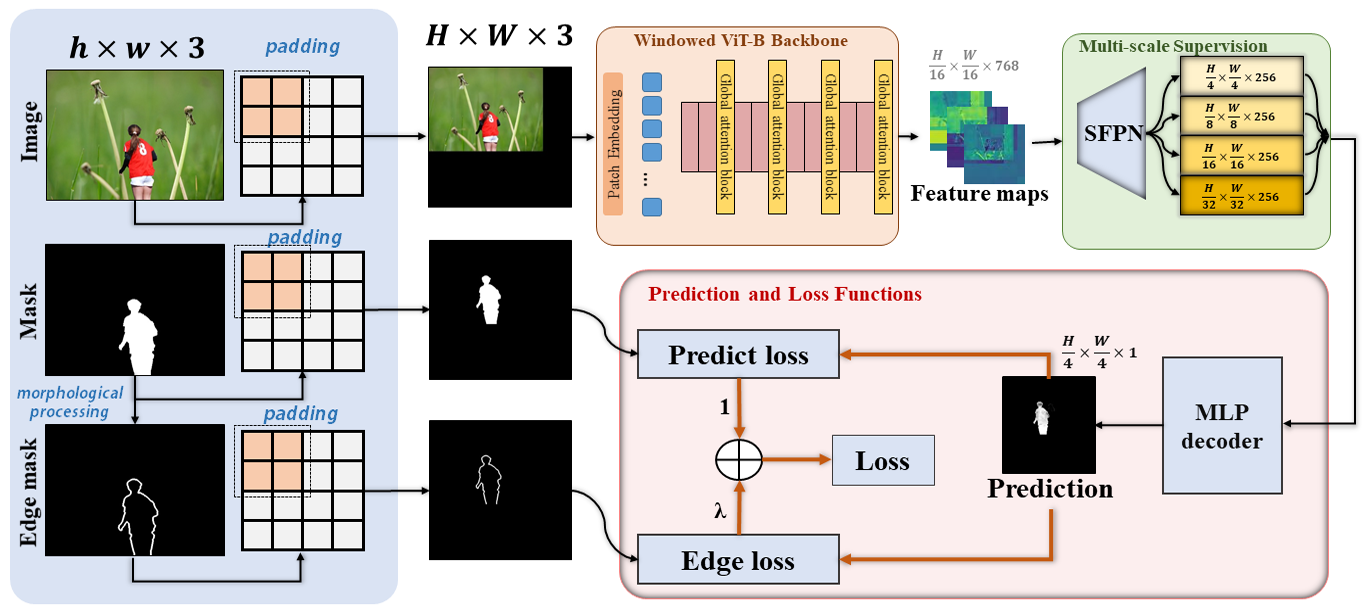
- 解像度を保持し、エッジ監督を使用し、マルチスケール機能を取り込む ViT ベースの IML モデルを提案する。
- 窓付きアテンションを持つ ViT と MAE pre-training が、クロスデータセットのベンチマークで CNN ベースの IML 手法を上回ることを示す。
- 一般的な歪み(JPEG、Gaussian blur)に対する頑健性を示し、オープンなベンチマークと公正なクロスデータセット評価を提唱する。
提案手法
- 精度と計算量のバランスをとるため、窓付きアテンションを備えた高解像度の Vision Transformer (ViT) を使用する。
- アーティファクトを保持するため、リサイズアーティファクトを生じさせないよう画像を固定の 1024x1024 解像度にパディングする。
- マルチスケール監督のために簡易 Feature Pyramid Network (SFPN) を取り入れる。
- 最終的なピクセル単位の予測には、軽量な MLP デコーダーヘッド(SegFormer のように)を採用する。
- 形態学ベースのエッジ損失を用いたエッジ監督を導入し、改ざん領域の境界を強調してセグメンテーション損失と組み合わせる。
- 小規模な IML データセットでの一般化を改善するため、ImageNet-1k で MAE を用いて ViT を事前学習する。

実験結果
リサーチクエスチョン
- RQ1純粋な ViT バックボーンは IML タスクの非意味論的アーティファクトを効果的にモデル化できるか?
- RQ2画像全体の解像度を保持しエッジ監督を追加することは、多様なデータセットにわたる改ざん領域の局在化を改善するか?
- RQ3IML のクロスデータセット一般化へのマルチスケール監督の影響は何か?
- RQ4限られたデータで MAE ベースの事前学習は ViT ベースの IML パフォーマンスにどのような影響を与えるか?
主な発見
- IML-ViT は five public IML benchmarks で F1 と AUC の両方で最先端の性能を達成する。
- 元の画像解像度をゼロパディング(1024x1024)で保持することは、アーティファクトの保持とモデル学習に有益である。
- エッジ監督は安定した収束と高い性能にとって重要であり、これがないと訓練が発散することがある。
- マルチスケール監督は、特に多様な改ざんタイプを含むデータセットで一般化効果を提供する。
- MAE プレトレーニングは ImageNet-1k で、限られたデータの IML に不可欠で、収束と一般化を向上させる。
- IML-ViT は JPEG 圧縮や Gaussian blur への耐性を含む、強いクロスデータセットの頑健性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。