[論文レビュー] Improving Code Generation by Training with Natural Language Feedback
本論文は Imitation Learning from Language Feedback (ILF) を提案する。訓練時に人間が作成した自然言語のフィードバックとリファインメントが不正確なコードを修正し、CodeGen モデルのパス率を向上させ、ベースラインのファインチューニングを上回る。
The potential for pre-trained large language models (LLMs) to use natural language feedback at inference time has been an exciting recent development. We build upon this observation by formalizing an algorithm for learning from natural language feedback at training time instead, which we call Imitation learning from Language Feedback (ILF). ILF requires only a small amount of human-written feedback during training and does not require the same feedback at test time, making it both user-friendly and sample-efficient. We further show that ILF can be seen as a form of minimizing the KL divergence to the ground truth distribution and demonstrate a proof-of-concept on a neural program synthesis task. We use ILF to improve a Codegen-Mono 6.1B model's pass@1 rate by 38% relative (and 10% absolute) on the Mostly Basic Python Problems (MBPP) benchmark, outperforming both fine-tuning on MBPP and fine-tuning on repaired programs written by humans. Overall, our results suggest that learning from human-written natural language feedback is both more effective and sample-efficient than training exclusively on demonstrations for improving an LLM's performance on code generation tasks.
研究の動機と目的
- トレーニング時に人間が書いたフィードバックを活用してコード生成を改善する動機付け。
- ILF を、より高品質なコードの真の分布への KL 発散を最小化する形式として定式化する。
- _示す ILF は MBPP および人間が修正したデータで標準的なファインチューニングを上回ること_。
提案手法
- リファインメントがユニットテストのパス率を高める報酬ベースの目的を定義する。
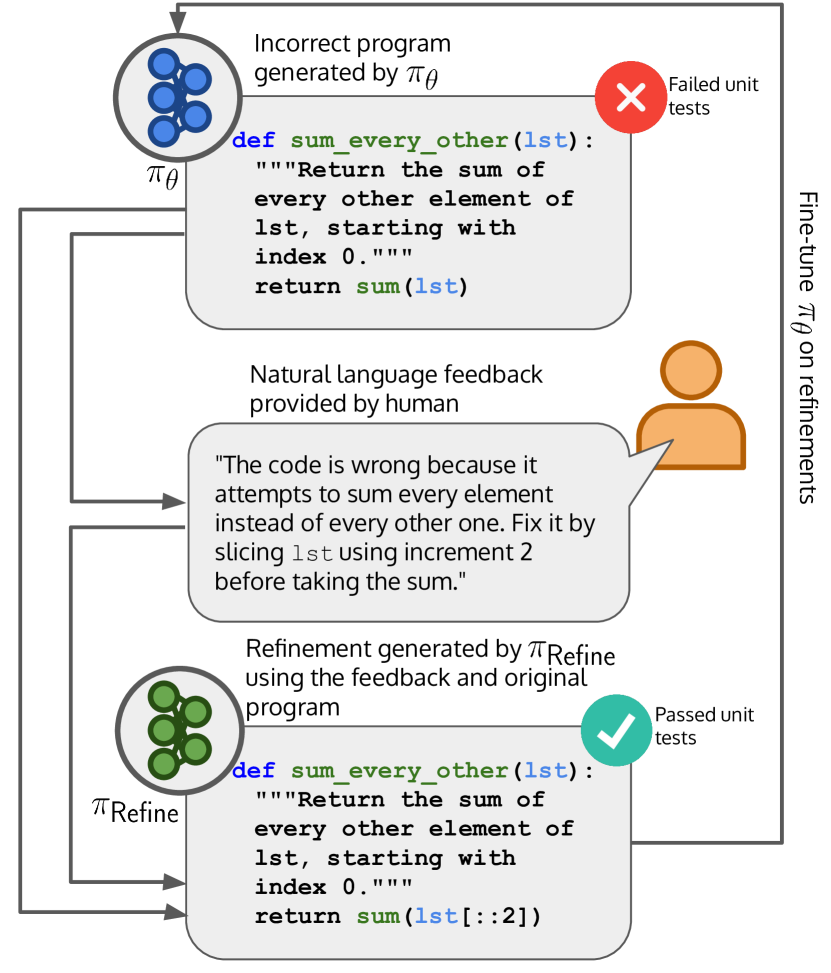
- フィードバック f を用いて不正確なコード x0 を正しいコード x1 に変換するよう訓練されたリファインメントモデル πRefine を作成する。
- フィードバックを取り込む高品質なリファインメントを優先的にサンプリングする提案分布 qt を構築する。
- πRefine が生成するリファインメントで基礎モデル θ をファインチューニングして θ* を得、反復的な改善を可能にする。
- CodeGen-Mono 6.1B をベースモデルとして MBPP を使用し pass@k 指標を評価する。
- ILF を、zero-shot、MBPP Gold ファインチューニング、および InstructGPT が生成したリファインメント を含むベースラインと比較する。
実験結果
リサーチクエスチョン
- RQ1人間が書いた自然言語のフィードバックを用いた訓練は、標準的なデモンストレーションを超えてコード生成の性能を向上させるか。
- RQ2ILF は MBPP のゴールドデータでの訓練や人間が書いたリファインメント単独での訓練とどう比較されるか。
- RQ3最終的な Pass 率に対する人間とモデル生成のフィードバックの影響は何か。
- RQ4複数のバグを扱うリファインメントの品質と処理は ILF の有効性にどう影響するか。
主な発見
| 手法 | フィードバック元 | ファインチューニングデータ | Pass@1 | Pass@10 |
|---|---|---|---|---|
| ILF | 人間 | πRefine Refinements | 36% | 68% |
| アブレーション | 1-shot InstructGPT | 1-shot InstructGPT Refinements | 19% | 55% |
| アブレーション | 2-shot InstructGPT | 2-shot InstructGPT Refinements | 25% | 59% |
| ゴールドスタンダード | - | MBPP Gold | 22% | 63% |
| ゴールドスタンダード | - | Human Refinements | 33% | 68% |
| ベースライン(ゼロショット) | - | - | 26% | 59% |
- ILF は MBPP の pass@1 を zero-shot と比べて相対的に 38%(絶対で 10%)改善する。
- ILF は MBPP ゴールドプログラムでのファインチューニングおよび人間リファインメントでのファインチューニングより、pass@1 で ILF が上回る(それぞれ絶対 14%、相対 64%、および絶対 3%、相対 9%)。
- πRefine が生成したリファインメントでのファインチューニングは、単発のフィードバックより大幅な向上をもたらし、リファインメントのパス率を改善する(Pass@1: 19% 対 0%、Pass@10: 47% 対 0%)。
- 人間が書いたフィードバックは、InstructGPT のフィードバックより多くのバグを修正し、より有益であり、より高い改善に寄与する。
- 少数の人間が書いたリファインメントを用いた訓練でも競争力のある改善をもたらし、ILF は比較的少ないフィードバックサンプル(合計 122 件)でも有効である。
- ILF は、より高品質なコード分布への KL 発散を最小化する現実的な、サンプル効率の良い教師あり学習の一形態と見なせる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。