[論文レビュー] Integrating Large Language Models in Causal Discovery: A Statistical Causal Approach
本論文は、統計的因果発見とGPT-4を介した知識ベースの因果推論を、統計的因果 prompting を用いて結合する枠組みを提案し、偏りのあるデータセットや未見データセットにおいても因果グラフを改善する。
In practical statistical causal discovery (SCD), embedding domain expert knowledge as constraints into the algorithm is important for reasonable causal models reflecting the broad knowledge of domain experts, despite the challenges in the systematic acquisition of background knowledge. To overcome these challenges, this paper proposes a novel method for causal inference, in which SCD and knowledge-based causal inference (KBCI) with a large language model (LLM) are synthesized through ``statistical causal prompting (SCP)'' for LLMs and prior knowledge augmentation for SCD. The experiments in this work have revealed that the results of LLM-KBCI and SCD augmented with LLM-KBCI approach the ground truths, more than the SCD result without prior knowledge. These experiments have also revealed that the SCD result can be further improved if the LLM undergoes SCP. Furthermore, with an unpublished real-world dataset, we have demonstrated that the background knowledge provided by the LLM can improve the SCD on this dataset, even if this dataset has never been included in the training data of the LLM. For future practical application of this proposed method across important domains such as healthcare, we also thoroughly discuss the limitations, risks of critical errors, expected improvement of techniques around LLMs, and realistic integration of expert checks of the results into this automatic process, with SCP simulations under various conditions both in successful and failure scenarios. The careful and appropriate application of the proposed approach in this work, with improvement and customization for each domain, can thus address challenges such as dataset biases and limitations, illustrating the potential of LLMs to improve data-driven causal inference across diverse scientific domains. The code used in this work is publicly available at: www.github.com/mas-takayama/LLM-and-SCD
研究の動機と目的
- 統計的因果発見(SCD)にドメイン知識を統合して、より意味のある因果モデルを得る動機付け。
- LLMベースの背景知識をSCDに生成・統合するための方法論(統計的因果 prompting)を提案。
- LLM誘導背景知識がSCDの性能とデータセットのバイアスに対する頑健性を向上させることを示す。
- SCPが複数のアルゴリズムとデータセットに渡ってLLM-KBCI出力とSCD結果の両方を強化できることを示す。
提案手法
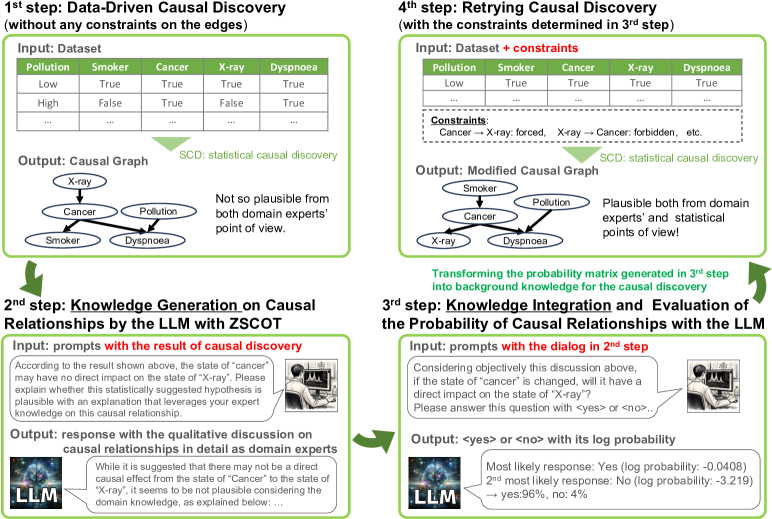
- 前知識なしでデータXに対して初期のSCDをPC、Exact Search、またはDirectLiNGAM(S)で実行する。
- 初期SCD結果(GKP)に基づき、零ショット連鎖推論プロンプトを用いてLLM(GPT-4)からすべての変数対間の詳細な因果知識を生成する。
- CAusality linksの確率を推定するために複数の試行でLLMの応答を評価する(統計的因果 prompting、SCP)。
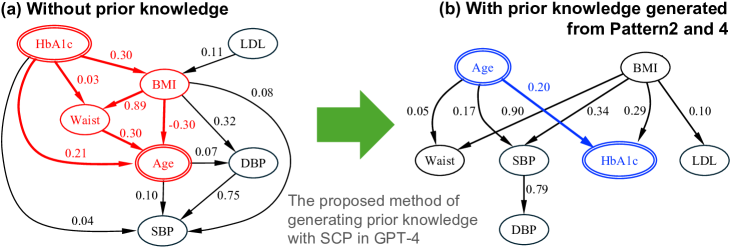
- LLM由来の確率マトリクスを変換規則を介して事前知識(PK)マトリクスに変換し、PKを用いてSCDを再実行して洗練されたグラフを得る。
- ブートストラップ再サンプリングを利用してエッジの確率を定量化し、規則ベースの制約(禁制/強制エッジ)を通じてそれらを前知識へ統合する。
- 複数のデータセット(DWD 気候データ、健康スクリーニングのサブセット)とSCDアルゴリズムを横断して頑健性と一般性を評価する。
実験結果
リサーチクエスチョン
- RQ1SCPで促されたGPT-4由来の背景知識は、SCDが学習する因果グラフの精度を改善できるか?
- RQ2SCPは相互改善を可能にするか、すなわち改善されたSCD結果がLLM-KBCI出力をさらに改善するか?
- RQ3提案されたLLM支援SCDは、LLMの事前学習データに含まれていないデータセットやバイアスが存在するデータセットで有効か?
- RQ4LLMに提供する情報の量と種類など、異なるSCPパターンは性能にどう影響するか?
- RQ5統計的妥当性(例:CFI、RMSEA、BIC)を維持しつつ、LLM由来の事前知識を活用できるか?
主な発見
- SCPで補強されたLLM-guided background knowledgeは、PKなしのSCDと比較して地上真実に近い結果をもたらす。
- PKを組み込んだSCDは、精度とF1を向上させ、BICを低減させることが多く、ドメイン知識によるモデル適合が改善される。
- SCPはLLM-KBCI出力と下流のSCD結果の双方を高め、相互の性能向上を示す。
- GPT-4の事前学習データに含まれていないデータセット(健康スクリーニングのサブセット)でも方法は有効で、偏りがある可能性がある。
- DirectLiNGAMは特定の prompting パターンの下でSCPの恩恵を特に受け、パターン依存の改善を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。