[論文レビュー] Interpretable and Explainable Logical Policies via Neurally Guided Symbolic Abstraction
NUDGE は、 pretrained ニューラルポリシーを用いた微分可能な前向き推論を導くことにより、解釈可能で説明可能な論理ポリシーを学習し、関連性強化学習タスク全般で競争力のある性能と堅牢な適応を実現します。
The limited priors required by neural networks make them the dominating choice to encode and learn policies using reinforcement learning (RL). However, they are also black-boxes, making it hard to understand the agent's behaviour, especially when working on the image level. Therefore, neuro-symbolic RL aims at creating policies that are interpretable in the first place. Unfortunately, interpretability is not explainability. To achieve both, we introduce Neurally gUided Differentiable loGic policiEs (NUDGE). NUDGE exploits trained neural network-based agents to guide the search of candidate-weighted logic rules, then uses differentiable logic to train the logic agents. Our experimental evaluation demonstrates that NUDGE agents can induce interpretable and explainable policies while outperforming purely neural ones and showing good flexibility to environments of different initial states and problem sizes.
研究の動機と目的
- 強化学習において、解釈可能かつ説明可能なポリシーの必要性を動機づける。
- ニューロン導 guided differentiable logic フレームワーク(NUDGE)を提案し、論理ベースのポリシーを学習する。
- pretrained neural policies によるシンボリック抽象化を誘導して、効率的なルール発見を実現する。
- NUDGE がニューラルベースラインと競合し、環境変化に適応できることを示す。
- 読みやすいルール集合と勾配ベースの説明を通じて解釈性を示す。
提案手法
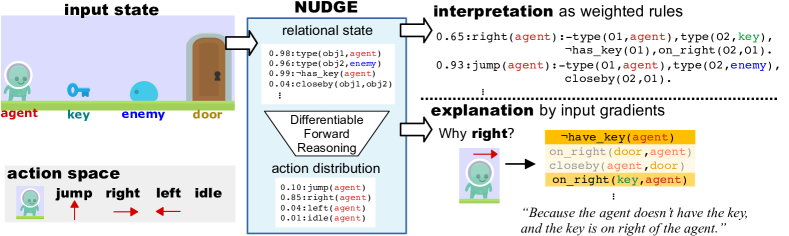
- アクション述語と状態述語を分離する一階述語論理のアクション-状態言語を定義する。
- 確率的事実からのアクション分布を微分可能な前向き推論で計算する。
- ニューラリ guided symbolic abstraction を実装して、ニューラルポリシーに基づいて候補ルールのコンパクトな集合を選択する。
- ニューラルクリティックを用いた PPO アクター-クリティック更新でルール重みを学習してリターンを最大化する。
- 確率論的論理表現に対して入力寄与度スコアを計算することで、勾配ベースの説明を提供する。
実験結果
リサーチクエスチョン
- RQ1Q1: NUDGE は標準タスクおよび論理志向タスクでニューラルおよび純粋論理ベースラインとどう比較されるか?
- RQ2Q2: 環境変化に対して再訓練なしで適応できるか?
- RQ3Q3: NUDGE ポリシーは解釈可能で、意思決定に対する説明を提供できるか?
主な発見
| Score (↑) | Random | DQN | NUDGE |
|---|---|---|---|
| Asterix | 235 ± 134 | 124.5 | 6259 ± 1150 |
| Freeway | 0.0 ± 0 | 25.8 | 21.4 ± 0.8 |
- NUDGE はいくつかの論理環境でニューラルベースラインを上回り、他の環境ではニューラル性能に匹敵するかそれを超える。
- NUDGE は再訓練なしで環境変化に対して堅牢であることを示す。
- NUDGE は解釈可能なポリシーを重み付けされたルール集合として生成し、アクション選択の勾配ベースの説明を可能にする。
- ニューロン導 guided 抽象化を用いる NUDGE はコンパクトなルール集合と効率的な学習を実現する。
- NUDGE は固定テンプレートに依存する非微分可能なシンボリックベースラインを大幅に上回る。
- 実験には OCAtari ベンチマークと三つのオブジェクト中心論理環境が含まれ、関係推論能力を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。