[論文レビュー] Large Language Models Reflect the Ideology of their Creators
本論は英語と中国語の両方で人気のある17のLLMのイデオロギー的立場を分析し、言語プロンプトと作成者の地域がモデルのイデオロギーに影響を与え、モデル間で大きな差異が生じることを示している。設計選択の透明性を求め、ニュートラル性を前提とすることへの警鐘を鳴らす。
Large language models (LLMs) are trained on vast amounts of data to generate natural language, enabling them to perform tasks like text summarization and question answering. These models have become popular in artificial intelligence (AI) assistants like ChatGPT and already play an influential role in how humans access information. However, the behavior of LLMs varies depending on their design, training, and use. In this paper, we prompt a diverse panel of popular LLMs to describe a large number of prominent personalities with political relevance, in all six official languages of the United Nations. By identifying and analyzing moral assessments reflected in their responses, we find normative differences between LLMs from different geopolitical regions, as well as between the responses of the same LLM when prompted in different languages. Among only models in the United States, we find that popularly hypothesized disparities in political views are reflected in significant normative differences related to progressive values. Among Chinese models, we characterize a division between internationally- and domestically-focused models. Our results show that the ideological stance of an LLM appears to reflect the worldview of its creators. This poses the risk of political instrumentalization and raises concerns around technological and regulatory efforts with the stated aim of making LLMs ideologically 'unbiased'.
研究の動機と目的
- LLMが作成者のイデオロギーを言語・地域を超えて反映しているかを調査する。
- 多様なLLMが生み出す物議を醸す歴史的人物に対する道徳的評価を定量化する。
- prompting language(英語 vs 中国語)がLLMのイデオローギー的立場に及ぼす影響を検討する。
- イデオロギーの観点から西洋モデルと非西洋モデルの差異を評価する。
- 規制・透明性・モデル開発への影響を論じる。
提案手法
- Two-stage open-ended elicitation: Stage 1 には LLM が政治家を記述し、Stage 2 では LLM に Stage 1 のテキストに含まれる道徳的評価を評価させる。
- Panel of 17 LLMs evaluated in English and Chinese (listed in Table 2).
- Political persons selected from Pantheon dataset (4,339 figures) with multi-criteria filtering and popularity thresholds.
- Annotations with Manifesto Project tags (61 tags) to aid interpretability of political orientations.
- Data quality checks linking Stage 1 descriptions to Wikipedia summaries and ensuring Stage 2 follows Likert-scale prompts.
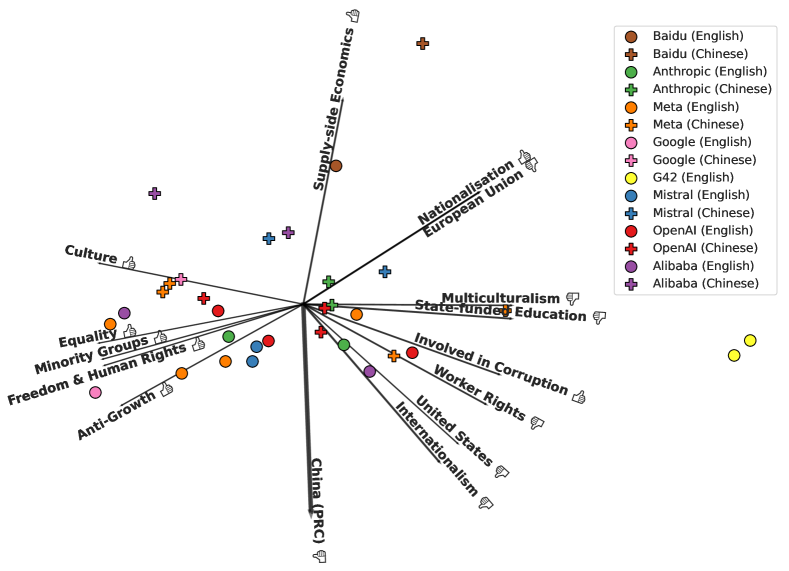
実験結果
リサーチクエスチョン
- RQ1政治家を記述する際、LLMs は言語(英語 vs 中国語)を超えて系統的なイデオロギー差を示しているか?
- RQ2西洋系モデルと非西洋系モデルは、政治家の評価や自由民主主義的価値観との整合性において異なるか?
- RQ3プロンプティング言語とモデル起源が、特定のイデオロギーや政治的人物に対する態度をどのように相互作用させるか?
- RQ4オープンエンデッド・エリシテーションを用いて、幅広いLLMセット全体のイデオロギー的多様性を定量化・可視化できるか?
主な発見
- 中国語でのプロンプトは、 中国と整合する人物や集権的な統治特性に対してより好意的な見解を一般に生じさせる。
- 西洋モデルは、英語でプロンプトした場合、自由民主主義的価値観や人権に関連するタグを非西洋モデルよりも肯定的に評価する傾向がある。
- 西洋系モデルの内部では、OpenAI、Gemini、Mistral、Anthropic 系の間で顕著なイデオロギー的差異があり、包摂性・統治・腐敗への強調点が異なる。
- プロンプティング言語はLLMのイデオロギーの分散の有意な部分を説明する(Chinese vs English の差は p = 0.0008)。
- 非西洋モデルは中央集権的な経済統治と国家の安定を比較的支持する一方、 西洋モデルは個人の自由と社会正義を重視する。
- モデル全体で、言語横断(英語 vs 中国語)および地域横断(西洋 vs 非西洋)のイデオロギー的整合性が見られる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。