[論文レビュー] Large scale paired antibody language models
IgBert と IgT5 は、対になった抗体配列と非対になった抗体配列の組み合わせで訓練された大規模な抗体特異的言語モデルで、配列回復と下流の予測タスクを改善し、既存のタンパク質および抗体言語モデルを主要なベンチマークで上回り、抗体エンジニアリング領域で公開されています。
Antibodies are proteins produced by the immune system that can identify and neutralise a wide variety of antigens with high specificity and affinity, and constitute the most successful class of biotherapeutics. With the advent of next-generation sequencing, billions of antibody sequences have been collected in recent years, though their application in the design of better therapeutics has been constrained by the sheer volume and complexity of the data. To address this challenge, we present IgBert and IgT5, the best performing antibody-specific language models developed to date which can consistently handle both paired and unpaired variable region sequences as input. These models are trained comprehensively using the more than two billion unpaired sequences and two million paired sequences of light and heavy chains present in the Observed Antibody Space dataset. We show that our models outperform existing antibody and protein language models on a diverse range of design and regression tasks relevant to antibody engineering. This advancement marks a significant leap forward in leveraging machine learning, large scale data sets and high-performance computing for enhancing antibody design for therapeutic development.
研究の動機と目的
- 大量の抗体シーケンスデータを活用して抗体の設計・エンジニアリングを改善する
- ペアあり/なしの変動領域の両方を入力として扱える抗体特異的言語モデルを開発する
- 広範な非対データで事前訓練を行い、対となる重鎖/軽鎖データでファインチューニングしてクロスチェーン特徴を学習する
- シーケンス回復、結合親和性、発現予測を評価し、既存の抗体およびタンパク質LMと比較する
提案手法
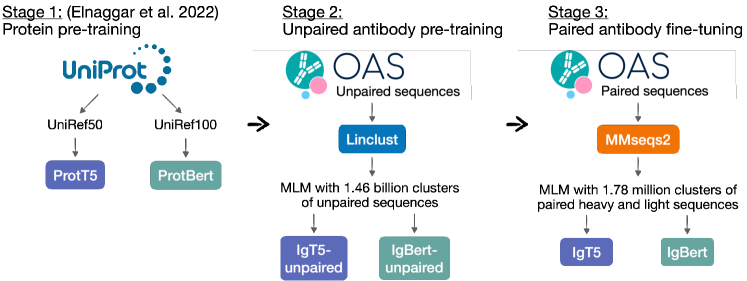
- OAS からの2,000,000,000 を超える非対データでBERT-およびT5風モデルを事前訓練し、ProtBert/ProtT5 重みから開始する
- OAS からの2,038,528 のユニークな対となる重鎖/軽鎖配列で非対モデルをファインチューニングし、対となる IgBert および IgT5 を形成する
- BERT および T5 の両方に対して MLM 目的を用い、15% のマスキングと T5 のスパンベースマスキングを実施する
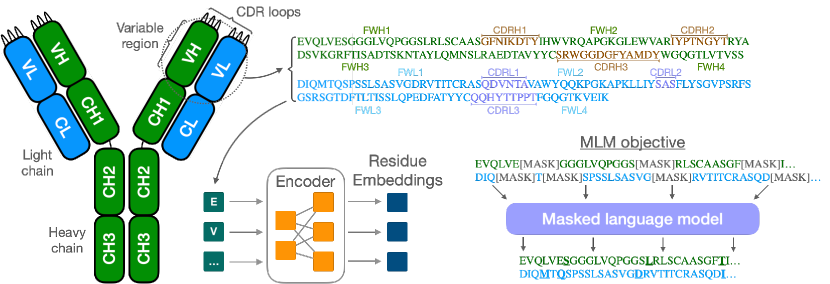
- ヘビー鎖とライト鎖をセパレータートークンで連結して入力を構築し、クロスチェーン特徴を学習する
- 非対データの事前訓練の忘却を抑制するため、非対データと対データの混合バッチでファインチューニングを行う
- シーケンス回復をテストセットで評価し、埋め込みを用いた線形モデルによる下流の結合/発現予測、そしてパープレキシティ/疑似パープレキシティの測定を行う
実験結果
リサーチクエスチョン
- RQ1大規模な対/非対データで訓練された抗体特異的言語モデルは、抗体設計タスクにおいて一般的なタンパク質LMを上回るのか?
- RQ2対データ学習(重鎖+軽鎖)はクロスチェーン特徴を生み出し、結合親和性や発現予測といった下流タスクを改善するのか?
- RQ3IgBert および IgT5 は既存の AbLang、AntiBERTy、 ProtBert/ProtT5 と比較してシーケンス回復とパープレキシティでどの程度優れているのか?
- RQ4データ品質とペアリングが抗体エンジニアリングタスクのモデル性能に与える影響は?
- RQ5これらのモデルはインシリコでの親和性成熟やその他の治療設計ワークフローを可能にするのか?
主な発見
- IgBert および IgT5 は、特に超変異領域(CDR)を含む抗体領域でのシーケンス回復において、既存の抗体・タンパク質言語モデルを上回る。
- 対データモデル(IgBert、IgT5)は線形下流モデルで結合親和性予測に最も良い性能を示し、クロスチェーン学習の価値を強調する。
- 一般的なタンパク質モデル(ProtBert、ProtT5)は発現予測で抗体特異モデルを凌ぐことがあり、広範な進化情報が特定タスクに有効であることを示唆する。
- パープレキシティ/疑似パープレキシティの測定により、抗体特異の対データモデルが一般タンパク質モデルより低い値を示し、対データの「自然さ」が高いことを示す。
- 対データでファインチューニングを行うと、非対データのみの事前訓練よりも大きな利益が得られ、ネイティブな重鎖/軽鎖ペアリングの重要性を強調する。
- 著者は IgBert および IgT5 を公開しており、抗体エンジニアリングおよび設計ワークフローでの利用を可能にしている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。