[논문 리뷰] Learning Controllable Fair Representations
본 논문은 보호 속성에 대해 제어 가능한 공정성을 갖는 최대 표현력을 학습하기 위한 정보 이론적 objective를 도입하고, 표현력과 공정성의 균형을 맞추기 위한 이중 최적화 접근법을 제안한다.
Learning data representations that are transferable and are fair with respect to certain protected attributes is crucial to reducing unfair decisions while preserving the utility of the data. We propose an information-theoretically motivated objective for learning maximally expressive representations subject to fairness constraints. We demonstrate that a range of existing approaches optimize approximations to the Lagrangian dual of our objective. In contrast to these existing approaches, our objective allows the user to control the fairness of the representations by specifying limits on unfairness. Exploiting duality, we introduce a method that optimizes the model parameters as well as the expressiveness-fairness trade-off. Empirical evidence suggests that our proposed method can balance the trade-off between multiple notions of fairness and achieves higher expressiveness at a lower computational cost.
연구 동기 및 목표
- 태스크 간 전이 가능하도록 표현을 학습하는 동시에 민감 속성에 대한 공정성 제약을 만족한다.
- 상호 정보(mutual information)를 사용해 표현력과 공정성을 정량화하고 최적화를 위한 실현 가능한 하한과 상한을 도출한다.
- 사용자가 지정한 공정성 한계와 표현력 간의 트레이드오프를 허용하는 이중 최적화 프레임워크를 제공한다.
제안 방법
- 공정성과 표현력을 I(x; z|u) 및 I(z; u)에 대한 엄격한 제약과 함께 상호 정보 항으로 형식화한다.
- 변이 분포와 KL 발산을 이용해 I(x; z|u)와 I(z; u)의 계산 가능한 하한과 상한을 도출한다.
- 모델과 함께 학습되는 예측기 pψ(u|z)를 통해 I(z; u) 경계를 강화하는 적대적 학습 경계를 도입한다.
- I(x; z|u)에 대한 변분 경 bounds를 최소화하는 실용적 목적함수를 제안하고, I(z; u)를 C1 및 hat{C2}로 제약하도록 한다.
- 공정성 제약을 정확히 만족시키기 위한 모델 매개변수와 라그랑주 승수를 동시에 최적화하는 이중 최적화 스킴을 개발한다.
- 본 접근 방식이 동일한 정보이론적 프레임워크의 특수한 경우로써 이전의 공정한 표현 방법들을 통합한다는 것을 보인다.
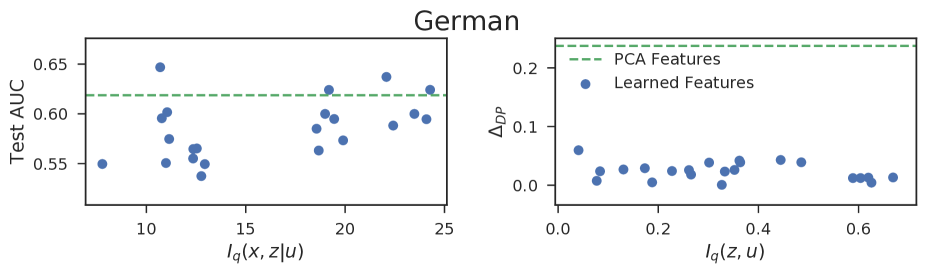
실험 결과
연구 질문
- RQ1정보 이론적 목표를 통해 공정성 제약을 표현학습에 어떻게 통합할 수 있는가?
- RQ2학습된 표현에서 공정성 수준을 제어하면서 다운스트림 작업에 대한 높은 표현력을 유지할 수 있는가?
- RQ3이중 최적화와 적대적 경계가 고정 계수 접근법보다 표현력-공정성의 트레이드오프를 개선하는가?
- RQ4다른 공정성 개념(인구통계적 동등성, 동등화된 오차, 동등화된 기회)이 상호 정보 기반 메트릭과 어떻게 정렬되는가?
- RQ5다중 보호 속성(이진이 아닌 경우 포함)을 프레임워크가 다룰 수 있는가?
주요 결과
- 제안된 정보이론적 목표가 기존의 공정성 개념과 정렬되며 공정성 제약 하에서 더 표현력 있는 표현을 얻는다.
- 이중 최적화 접근이 epsilon과 적응적 승수를 통한 표현력-공정성의 트레이드오프를 직접 제어 가능하게 한다.
- 적대적 경계가 I(z; u) 제약의 타이트함을 향상시키면서 표현력을 희생하지 않아 다중 제약 공정성 제어를 가능하게 한다.
- L-MIFR(이중 최적화)이 유사한 계산에서 MIFR(고정 승수)보다 표현력 면에서 우수하며 그리드 탐색의 필요성을 줄인다.
- 데이터셋 전반에 걸쳐 공정성 예산 epsilon를 증가시키면 일반적으로 측정된 불공정성(Delta DP)이 증가하는 경향을 보이지만 더 정보-rich한 표현이 가능해진다.
- 프레임워크는 여러 공정성 개념을 동시에 균형 있게 다룰 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.