[論文レビュー] Learning Longer-term Dependencies in RNNs with Auxiliary Losses
本論文は、RNN(r-LSTMとp-LSTM)に追加された教師なし補助損失を導入し、 subsequences を再構成または予測可能にすることで、切り捨てられたBPTTを用いた長期依存の学習を可能にし、効率を改善し、長い系列でいくつかのベースラインを上回る。
Despite recent advances in training recurrent neural networks (RNNs), capturing long-term dependencies in sequences remains a fundamental challenge. Most approaches use backpropagation through time (BPTT), which is difficult to scale to very long sequences. This paper proposes a simple method that improves the ability to capture long term dependencies in RNNs by adding an unsupervised auxiliary loss to the original objective. This auxiliary loss forces RNNs to either reconstruct previous events or predict next events in a sequence, making truncated backpropagation feasible for long sequences and also improving full BPTT. We evaluate our method on a variety of settings, including pixel-by-pixel image classification with sequence lengths up to 16\,000, and a real document classification benchmark. Our results highlight good performance and resource efficiency of this approach over competitive baselines, including other recurrent models and a comparable sized Transformer. Further analyses reveal beneficial effects of the auxiliary loss on optimization and regularization, as well as extreme cases where there is little to no backpropagation.
研究の動機と目的
- 長い系列における長期依存の学習を、時系列を通じた誤差伝搬(BPTT)と高いメモリコストの課題に対処する。
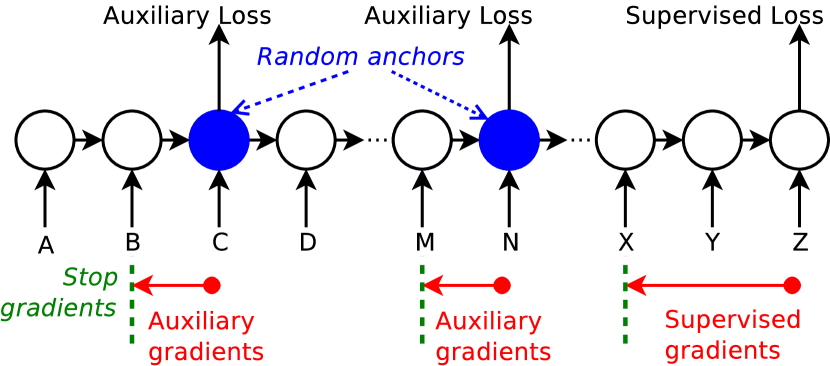
- ランダムなアンカーポイントで過去の部分列を再構成する、または未来の部分列を予測する補助的な教師なし損失を提案する。
- これらの補助損失が切り捨てられたBPTTを用いた効果的な学習を可能にし、最適化と汎化を改善することを示す。
- 非常に長い系列タスク(最大16,000ステップ)で評価し、リカレントベースラインおよび Transformer 系と比較する。
提案手法
- 入力系列にランダムなアンカー点を導入する。
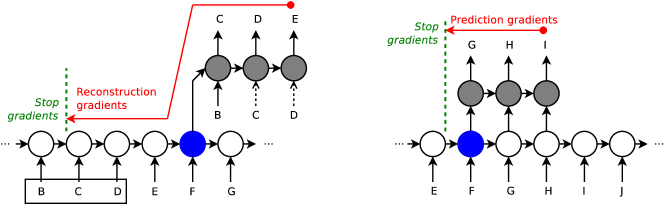
- アンカー点から過去の部分列を再構成する再構成補助損失を追加する。
- アンカー点から未来の部分列を予測する予測補助損失を追加する。
- 2段階で訓練する:補助損失の教師なし事前学習、続いて主監視損失と補助損失を組み合わせた半教師付き訓練。
- シーケンス長に関係なくBPTTコストを一定に保つために切り捨てた誤差伝搬を用いる。
- 長い系列でr-LSTM(再構成)とp-LSTM(予測)を用いて評価し、LSTMベースラインおよびTransformerと比較する。
実験結果
リサーチクエスチョン
- RQ1切り捨てられたBPTTを用いた場合、教師なし補助損失はRNNの長距離依存の学習を改善できるだろうか?
- RQ2再構成補助損失と予測補助損失は、長い系列のモデリングにおいて最適化上または正則化上の利点を提供するか?
- RQ3長い系列のベンチマークにおいて、精度と効率の観点からr-LSTMとp-LSTMはLSTMやTransformerとどう比較されるか?
- RQ4補助損失の有効性に対するサンプリング頻度と部分列長の影響は何か?
- RQ5これらの手法は非常に長い系列(最大16,000ステップ)および異なるデータドメイン(画像、テキスト)に対してどれだけスケーラブルか?
主な発見
- 補助損失は切り捨てられたBPTTで強い性能を実現し、いくつかのタスクで完全に逆伝播されたRNNに匹敵する、またはそれに近づく。
- 長い系列を持つMNIST、pMNIST、CIFAR10、StanfordDogsでは、r-LSTMとp-LSTMが切り捨て下の完全訓練LSTMを上回し、系列長が増えるにつれてより良いスケーラビリティを示す。
- 長い系列では、r-LSTMとp-LSTMは相当な計算効率を示し、全BPTTが実行不能になる場所でも訓練時間を manageable に保つ。
- DBpedia の文字レベル分類では、切り捨てBPTTを用いた補助損失がLSTMおよびSA-LSTM、LM-LSTMを含む他のベースラインを顕著に上回る。
- Transformerのベースラインと比較すると、短い系列では高い精度を達成するかもしれないが、長い系列では性能が低下する一方で、r-LSTM/p-LSTMは堅牢でメモリ効率が高いままである。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。