[論文レビュー] Learning Robust Statistics for Simulation-based Inference under Model Misspecification
この論文は、シミュレーションベースの推論(SBI)において、SBI 手法(NPE、ABC など)全体のモデルミススペシフィケーションを緩和するため、MMD ベースのミススペシフィケーションペナルティで統計学習目的を正則化し、ロバストな統計量を学習する一般的なアプローチを提案する。
Simulation-based inference (SBI) methods such as approximate Bayesian computation (ABC), synthetic likelihood, and neural posterior estimation (NPE) rely on simulating statistics to infer parameters of intractable likelihood models. However, such methods are known to yield untrustworthy and misleading inference outcomes under model misspecification, thus hindering their widespread applicability. In this work, we propose the first general approach to handle model misspecification that works across different classes of SBI methods. Leveraging the fact that the choice of statistics determines the degree of misspecification in SBI, we introduce a regularized loss function that penalises those statistics that increase the mismatch between the data and the model. Taking NPE and ABC as use cases, we demonstrate the superior performance of our method on high-dimensional time-series models that are artificially misspecified. We also apply our method to real data from the field of radio propagation where the model is known to be misspecified. We show empirically that the method yields robust inference in misspecified scenarios, whilst still being accurate when the model is well-specified.
研究の動機と目的
- ミススペシフィケーションがまとめ統計量を用いた SBI に与える影響を特定する。
- ロバストな統計量を得るための正則化学習目的を開発する。
- NPE と ABC(RNPE との比較を含む)にわたって手法のロバスト性を実証する。
- 合成時系列モデルと実データの無線伝搬データセットへの適用性を示す。
提案手法
- SBI におけるモデルとまとめ統計量のペアのミススペシフィケーションを定義し、それをミススペシフィケーションマージンで定量化する。
- 観測統計量とシミュレーション統計量のずれをペナルティ化する正則化項を追加したロバスト統計量(RS)loss を導入する。
- 観測統計量とシミュレーション統計量の分布を比較する正則化距離として最大平均差異(MMD)を用いる。
- RS loss を用いて、NPE の場合はサマリーネットワークと推論ネットワークを共同学習、AE の場合はオートエンコーダと共同学習する。
- MMD 項の閉形式推定量を提供し、実務的な選択(カーネル、サブセットサイズ l など)を説明する。
- 正則化ウェイト λ がロバスト性と情報量のトレードオフをどう制御し、NPE/ABC と事前分布の間を補間するかを示す。
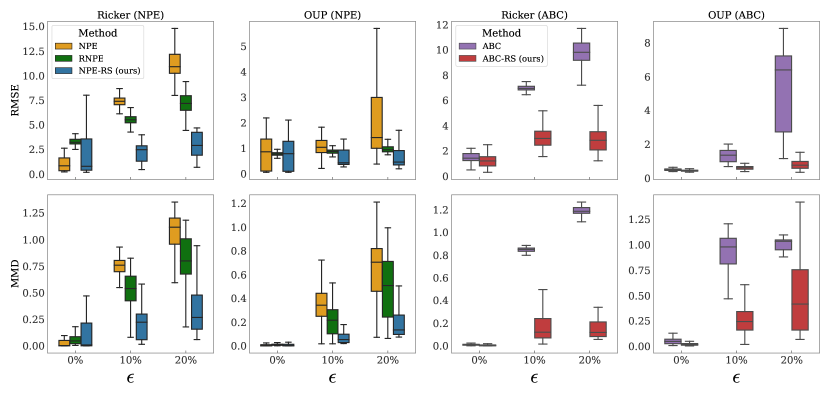
実験結果
リサーチクエスチョン
- RQ1ミススペシフィケーションは NPE および ABC によって生成される SBI の後方分布にどのような影響を及ぼすか?
- RQ2RS loss を用いたロバストな統計量の学習は、ミススペシフィケーション下で後方偏りを低減しつつ、適切に指定された場合には性能を維持できるか?
- RQ3RS アプローチは SBI の手法(NPE、ABC)を越えて一般的で、さまざまなデータモダリティにも適用可能か?
- RQ4実務的には正則化ウェイト λ をどのように選ぶべきか?
主な発見
- NPE-RS および ABC-RS は、ミススペシフィケーション(ε > 0)の下で、非ロバストな counterparts より RMSE および MMD 指標で上回る。
- 適切に仕様された設定では、NPE-RS および ABC-RS は標準の NPE および ABC と同等の性能を発揮する。
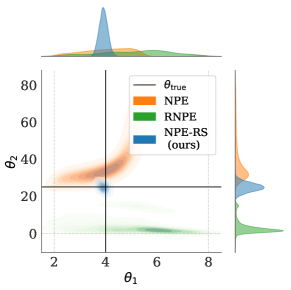
- RNPE は標準の NPE よりロバスト性を向上させるが、真のパラメータから依然として外れる可能性がある一方、NPE-RS は真の値に近い状態を保つ。
- RS フレームワークは事前分布のミススペシフィケーションにも頑健で、事前分布が真のパラメータを除外する場合にもポスト分布を真のパラメータ付近に保つ。
- このアプローチはモデルが正しく指定されている場合にも精度を維持し、時系列モデル(Ricker、OU)および実データの無線伝搬データセットにも対して頑健な推論を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。