[論文レビュー] Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation
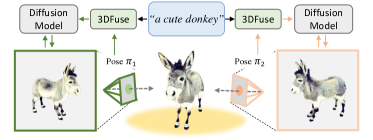
3DFuse は coarse 3D priors からの深度マップを条件として用い、語彙の埋め込みを意味コード化して LoRA を使用することで SDS ベースのテキスト-to-3D 生成における 3D 一貫性を向上させます。
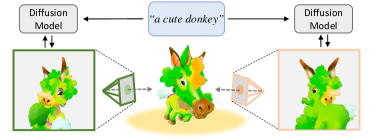
Text-to-3D generation has shown rapid progress in recent days with the advent of score distillation, a methodology of using pretrained text-to-2D diffusion models to optimize neural radiance field (NeRF) in the zero-shot setting. However, the lack of 3D awareness in the 2D diffusion models destabilizes score distillation-based methods from reconstructing a plausible 3D scene. To address this issue, we propose 3DFuse, a novel framework that incorporates 3D awareness into pretrained 2D diffusion models, enhancing the robustness and 3D consistency of score distillation-based methods. We realize this by first constructing a coarse 3D structure of a given text prompt and then utilizing projected, view-specific depth map as a condition for the diffusion model. Additionally, we introduce a training strategy that enables the 2D diffusion model learns to handle the errors and sparsity within the coarse 3D structure for robust generation, as well as a method for ensuring semantic consistency throughout all viewpoints of the scene. Our framework surpasses the limitations of prior arts, and has significant implications for 3D consistent generation of 2D diffusion models.
研究の動機と目的
- SDS ベースのテキスト-to-3D 生成における3D不整合性(“Janus problem”)を動機づけ、対処する。
- 事前学習済みの2D 拡散モデルへ3D認識をもつ条件付けの機構を導入する。
- 視点を跨いで頑健で幾何的に一貫した3Dシーン生成を実現する。
- 意味コード化と LoRA による3D生成の意味的一貫性と制御性を向上させる。
提案手法
- 意味コードサンプリングを用いて生成画像に適合させるテキスト埋め込みを最適化し、曖昧さを低減して semantic code s=(hat{x}, hat{e}) を得る。
- セマンティックコード画像から粗い3D点群を構築し、オフ・ザ・シェルフの3Dモデルを用いて各ビューの深度マップ p を投影する。
- ControlNet 風の残差的な 3D 念 conditioning を提供するよう、投影深度マップを diffusion U-net に供給するスパース深度インジェクターモジュールを組み込む。
- diffusion モデルを凍結したまま深度インジェクターのみを訓練(必要に応じて LoRA 層も含む)し、効率的なファインチューニングを可能にする。
- LoRA を diffusion U-net に適用して、低ランク適応層を調整することで視点間の意味的一貫性を向上させる。
- 複数の SDS ベースのベースライン(DreamFusion, SJC, ProlificDreamer)および MCC ベースの3D priors へ適応を実証する。
実験結果
リサーチクエスチョン
- RQ1 coarse 3D priors からのビュー特異的深度マップを条件付けすることで、SDS ベースのテキスト-to-3D 生成における3D一貫性は向上するか?
- RQ2意味コード化は prompts の曖昧さを低減し、視点を跨いで意味的に一貫した3Dシーンを生み出すか?
- RQ33D認識の条件付けは、異なるベースライン間で忠実度と幾何学的頑健性にどう影響するか?
- RQ43D生成における意味的一貫性のための LoRA の効果はどのようなものか?
- RQ5提案手法はさまざまな2D拡散バックボーンと3D priors に対してスケーラブルか?
主な発見
| Method | Variance |
|---|---|
| SJC + 3DFuse (Ours) | 0.0499 |
| SJC (Wang et al. 2022a) | 0.0870 |
- 3DFuse は DreamFusion, SJC, ProlificDreamer のベースラインを横断して3D一貫性と忠実度を大幅に向上させる。
- COLMAP ベースの指標により、3DFuse はベースライン SJC メソッドよりも3D不整合の分散を小さく抑える(0.0499 対 0.0870)。
- ユーザ調査(102 名の参加者)は、3DFuse 強化結果を3Dの一貫性、プロンプト順守、全体品質で有利と評価。
- 意味コード化は視点特有の意味的・幾何的不整合を削減する。
- LoRA ベースのファインチューニングは、Diffusion モデルの大規模な変更を伴わずに意味的一貫性をさらに向上させる。
- MCC ベースの3D priors に対しても定性的結果が拡張され、priors への堅牢性を確認。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。