[論文レビュー] Limitations of the LLM-as-a-Judge Approach for Evaluating LLM Outputs in Expert Knowledge Tasks
この論文は、ダイエット学と精神保健の領域固有タスクにおける判定者としてのLLMを評価し、SMEとLLMの合意は限定的であり、専門家の関与を継続するべきだと提案している。
The potential of using Large Language Models (LLMs) themselves to evaluate LLM outputs offers a promising method for assessing model performance across various contexts. Previous research indicates that LLM-as-a-judge exhibits a strong correlation with human judges in the context of general instruction following. However, for instructions that require specialized knowledge, the validity of using LLMs as judges remains uncertain. In our study, we applied a mixed-methods approach, conducting pairwise comparisons in which both subject matter experts (SMEs) and LLMs evaluated outputs from domain-specific tasks. We focused on two distinct fields: dietetics, with registered dietitian experts, and mental health, with clinical psychologist experts. Our results showed that SMEs agreed with LLM judges 68% of the time in the dietetics domain and 64% in mental health when evaluating overall preference. Additionally, the results indicated variations in SME-LLM agreement across domain-specific aspect questions. Our findings emphasize the importance of keeping human experts in the evaluation process, as LLMs alone may not provide the depth of understanding required for complex, knowledge specific tasks. We also explore the implications of LLM evaluations across different domains and discuss how these insights can inform the design of evaluation workflows that ensure better alignment between human experts and LLMs in interactive systems.
研究の動機と目的
- LLMベースの評価が、領域特有で専門知識を要するタスクにおけるSMEの判断とどのように一致するかを評価する。
- ダイエット学と精神保健の領域におけるSMEとLLMジャッジの間での合意/不一致を導く要因を調査する。
- 専門家ペルソナがLLMジャッジとSMEとの整合性に与える影響を検討する。
- 評価の差異を理解するために、SMEとLLMの両方の定性的説明を分析する。
提案手法
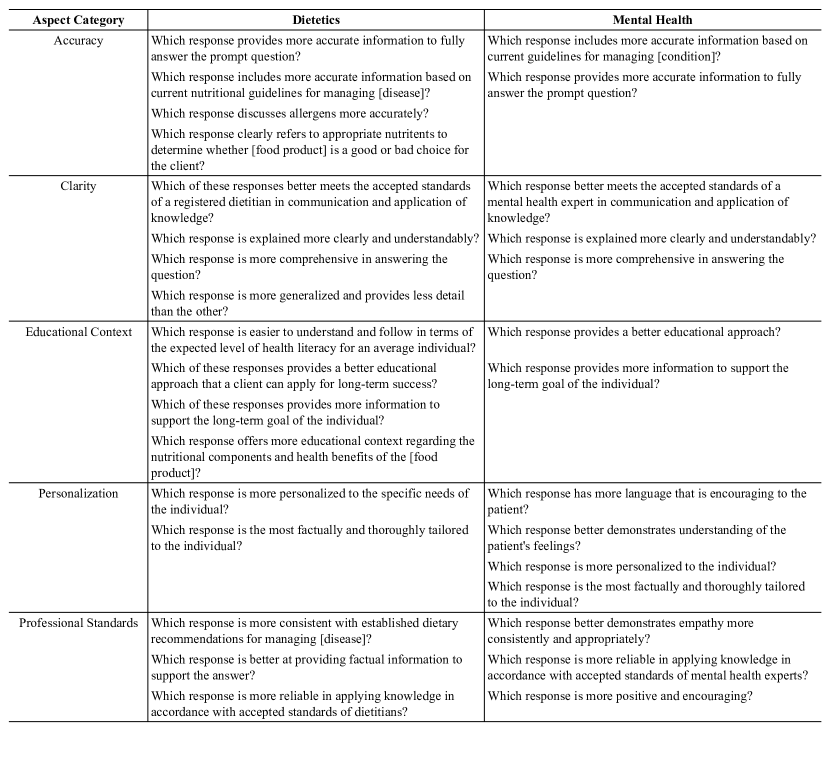
- ダイエット学と精神保健の領域特有の指示を25件厳選した。
- 各指示に対して、指示ごとに2つのモデル出力を、SMEとLLMジャッジによるペア評価で比較した。
- 合意への影響を検証するために専門家ペンプソナプロンプトを使用した。
- explanationsのためのLLMベースランキングにAlpacaEvalフレームワークを適用した。
- ランキング説明の帰納的テーマ分析を実施して、テーマを特定した。
実験結果
リサーチクエスチョン
- RQ1RQ1: LLM-ジャッジとしての評価は、領域特有タスクにおいてSMEの評価とどのように比較されるか。
- RQ2RQ2: LLMとSMEの間の評価差と説明に寄与する要因は何か。
主な発見
| 質問タイプ | Dietetics (General Model) | Dietetics (Expert Persona) | Mental Health (General Model) | Mental Health (Expert Persona) |
|---|---|---|---|---|
| Clarity | 55% | 60% | 70% | 40% |
| Accuracy | 56% | 67% | 80% | 80% |
| Professional Standards | 80% | 80% | 64% | 73% |
| Education Context | 55% | 45% | 60% | 70% |
| Personalization | 56% | 44% | 67% | 67% |
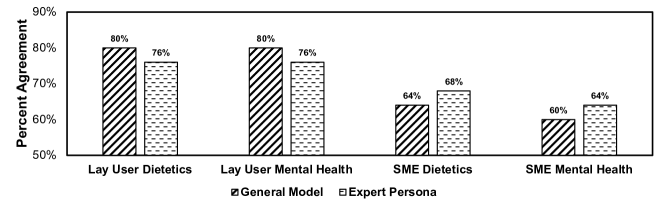
| General Preference | 64% | 68% | 60% | 64% |
- SMEsは、ダイエット学でLLMジャッジと全体的な好みについて68%、精神保健で64%の同意を示した。
- SMEs同士の合意は、精神保健で72%、ダイエット学で75%だった。
- 専門家ペルソナプロンプトは一般的な好みに対するSME–LLMの合意を約4%改善した。
- 合意は領域特有の側面によって異なり、いくつかのカテゴリで精神保健の方がダイエット学より高い傾向にあった。
- SMEsは正確性、最新のエビデンス、専門基準、明確なコミュニケーションを優先した。一方、LLMsは指示の遵守と詳細を重視することが多かった。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。