[論文レビュー] Local Aggregation for Unsupervised Learning of Visual Embeddings
この論文は Local Aggregation (LA) を導入し、動的にソフトな局所クラスタを形成することで視覚埋め込みを学ぶ無教師あり学習法を提案し、ImageNet、Places 205、PASCAL VOC での無監督転移で最先端を達成した。
Unsupervised approaches to learning in neural networks are of substantial interest for furthering artificial intelligence, both because they would enable the training of networks without the need for large numbers of expensive annotations, and because they would be better models of the kind of general-purpose learning deployed by humans. However, unsupervised networks have long lagged behind the performance of their supervised counterparts, especially in the domain of large-scale visual recognition. Recent developments in training deep convolutional embeddings to maximize non-parametric instance separation and clustering objectives have shown promise in closing this gap. Here, we describe a method that trains an embedding function to maximize a metric of local aggregation, causing similar data instances to move together in the embedding space, while allowing dissimilar instances to separate. This aggregation metric is dynamic, allowing soft clusters of different scales to emerge. We evaluate our procedure on several large-scale visual recognition datasets, achieving state-of-the-art unsupervised transfer learning performance on object recognition in ImageNet, scene recognition in Places 205, and object detection in PASCAL VOC.
研究の動機と目的
- 教師あり手法との差を埋める深い視覚表現のための無監督学習を動機づけ、開発する。
- 埋め込み空間内で近くのデータがクラスタ化され、異なるデータが分離するよう、局所的なノンパラメトリック集約を活用する。
- 動的でマルチスケールなソフトクラスタリング構造が、タスクやアーキテクチャを横断した転送性能を改善することを示す。
- より深いネットワークはLAの恩恵をより受け、ラベルなしで競争力のある、あるいは優れた結果を達成することを示す。
提案手法
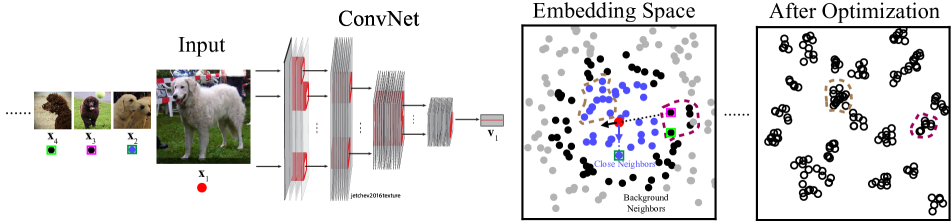
- 入力をニューラルネットワークを介して非線形に D 次元の単位球面へ埋め込み v_i を得る。
- 各埋め込みについて、近傍集合として C_i(近傍)と B_i(背景近傍)の2つを特定する。C_i は V 上のロバストなクラスタリングを複数のクラスタリングにまたがって集約して計算され、B_i は埋め込み上の k 最近傍を用いる。
- 局所的集約損失 L(C_i, B_i | θ, x_i) を、背景近傍であることが前提されたときに v_i が C_i に近いことの負の対数尤度比として定義する。τ の温度を持つコサイン類似度のノンパラメトリックソフトマックスに基づく。
- θ に対する L2 正則化を用いて L を最適化し、埋め込み関数を学習する。訓練中は V を効率的に近似するメモリーバンクを使用する。
- 埋め込みの移動平均を格納するメモリーバンク V̄ を維持し、毎ステップすべての特徴量を再計算することなく近傍識別を安定化させる。
- 訓練はウォームアップとしてインスタンス認識損失から開始し、次に局所集約損失に切り替える。ハイパーパラメータには τ=0.07、D=128、B_i の k=4096、m 個のクラスタを持つ多重クラスタリング H を含む。
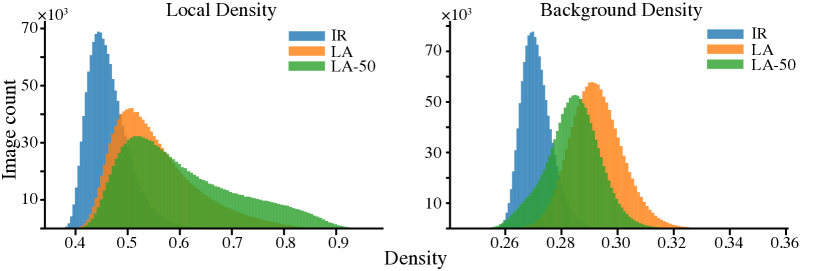
実験結果
リサーチクエスチョン
- RQ1埋め込み空間における局所的でノンパラメトリックな集約は、高品質な無監督視覚表現を生み出せるのか。
- RQ2動的でマルチスケールなクラスタリングは、学習された埋め込み空間の幾何学と下流の転送性能にどのような影響を与えるか。
- RQ3より深いネットワークは、浅いネットワークと比較してLA目的により恩恵を受けるのか。
- RQ4LAアプローチはクラスタリングの選択や近傍の定義に対して頑健ですか。
- RQ5LAで訓練された表現は、画像分類、シーン認識、物体検出タスクへ効果的に転移できるか。
主な発見
- LAは複数のアーキテクチャにおいて、ImageNetとPlaces 205の分類で無監督転移学習の最先端を達成した。
- LAを訓練したResNet-50は、ラベルなしで ImageNet のトップ1精度 60.2% を達成し、AlexNet の教師あり訓練を上回る。
- 微調整後、PASCAL VOC 2007 での物体検出性能を向上させ、このタスクの無監督転移で最先端を達成。
- LAはより深いアーキテクチャから恩恵を受け、conv1 から conv5 層まで一貫した性能向上を示す。
- LA 表現はさまざまな視覚タスクに良く一般化し、データセット間で強い KNN および線形読出しの転移結果を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。