[論文レビュー] Octo: An Open-Source Generalist Robot Policy
Octo は大規模なトランスフォーマーベースの、オープンソースの汎用ロボットポリシーで、800k のデモンストレーションで事前学習され、新しいロボット、観測、行動空間へ効率的にファインチューニング可能。言語またはゴール画像条件付けをサポート。
Large policies pretrained on diverse robot datasets have the potential to transform robotic learning: instead of training new policies from scratch, such generalist robot policies may be finetuned with only a little in-domain data, yet generalize broadly. However, to be widely applicable across a range of robotic learning scenarios, environments, and tasks, such policies need to handle diverse sensors and action spaces, accommodate a variety of commonly used robotic platforms, and finetune readily and efficiently to new domains. In this work, we aim to lay the groundwork for developing open-source, widely applicable, generalist policies for robotic manipulation. As a first step, we introduce Octo, a large transformer-based policy trained on 800k trajectories from the Open X-Embodiment dataset, the largest robot manipulation dataset to date. It can be instructed via language commands or goal images and can be effectively finetuned to robot setups with new sensory inputs and action spaces within a few hours on standard consumer GPUs. In experiments across 9 robotic platforms, we demonstrate that Octo serves as a versatile policy initialization that can be effectively finetuned to new observation and action spaces. We also perform detailed ablations of design decisions for the Octo model, from architecture to training data, to guide future research on building generalist robot models.
研究の動機と目的
- embodiment and taskを横断する汎用ロボットポリシーの必要性を動機付ける。
- 新しいセンサー、アクチュエータ、ドメインへファインチューニング可能な、オープンソースのトランスフォーマーベースポリシーを開発する。
- 言語/ゴール条件付けタスクを含む複数ロボットでゼロショット制御を実証する。
- 大規模かつ多様なデータセットから novel ロボット設定へのデータ効率的なファインチューニングを示す。
- 汎用ロボットポリシーの設計判断(アーキテクチャ、データ、目的、スケール)に関する指針を提供する。
提案手法
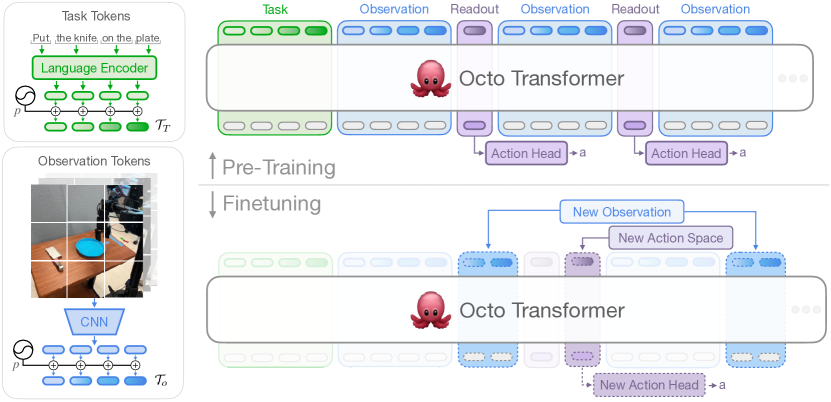
- 言語目標と観測を共通のトークン列へトークン化するトランスフォーマーポリシー。
- 入力トークナイザー: 言語は t5-base、画像は軽量 CNN パッチ、位置埋め込みを使用。
- ファインチューニング時に入力の追加/削除を柔軟に行えるよう、読み出しトークンを備えたブロック単位のマスキング付きトランスフォーマー・バックボーン。
- DDPM 目的で連続的な複数のアクションを一括で予測する拡散ベースのアクションデコードヘッド。
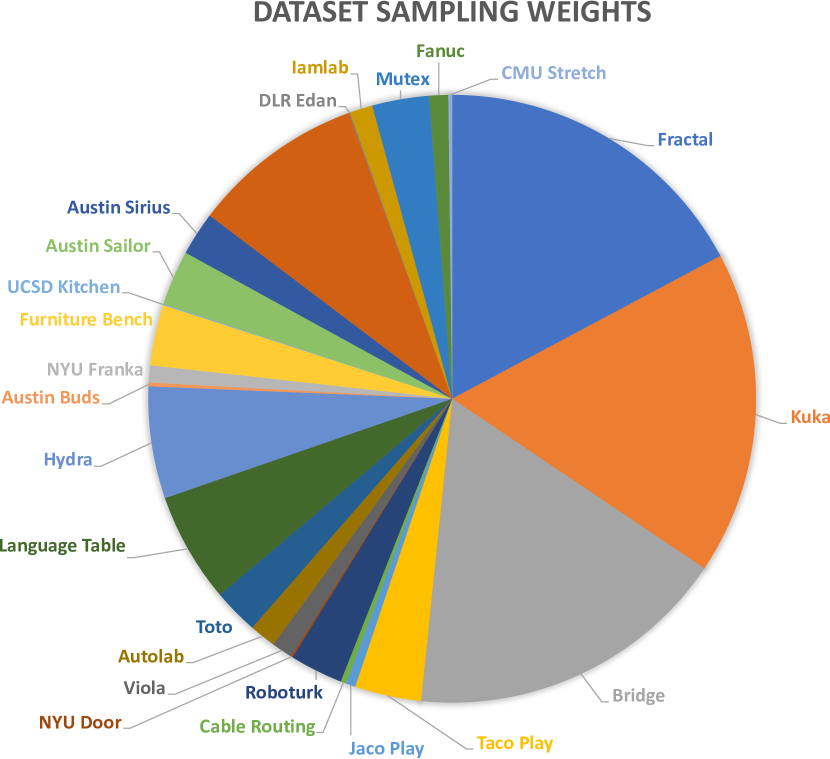
- 欠損モダリティに対してゼロパディングを用いた、多様な Open X-Embodiment データミックス(25 データセット、約800k デモンストレーション)で学習。
- ファインチューニング時は同じ拡散目的、ターゲットドメインあたり約100 traj、コンシューマー GPU で約5万ステップ; 新しい入力/出力には再初期化せずにアダプターを追加。
実験結果
リサーチクエスチョン
- RQ1Octo は言語と目標画像条件付けを用いてゼロショットで複数のロボットを制御できるか。
- RQ2 Octo は unseen なロボット、観測、アクション空間へデータ効率的なファインチューニングの良い初期値となるか。
- RQ3 どの設計選択(アーキテクチャ、データ混合、目的)が汎用ロボットポリシーの性能に最も影響するか。
- RQ4 モデルサイズとデータ多様性はゼロショットおよびファインチューニング性能の改善にどう影響するか。
主な発見
| Berkeley Insertion | Stanford Coffee | CMU Baking | Berkeley Pick-Up | Berkeley Coke | Berkeley Bimanual | Average | |
|---|---|---|---|---|---|---|---|
| ResNet+Transformer Scratch | 10% | 45% | 25% | 0% | 20% | 20% | 20% |
| VC-1 [57] | 5% | 0% | 30% | 0% | 10% | 50% | 15% |
| Octo (Ours) | 70% | 75% | 50% | 60% | 100% | 80% | 72% |
- -Octo は 9 ロボットと 4 拠点におけるゼロショット制御を実現し、言語条件付きタスクで以前のオープンに利用可能な汎用ポリシーを上回る。
- 約100 デモ/ドメインでのファインチューニングは、ゼロショットまたは pretrained VC-1 visuals からの学習よりも優れた性能を顕著な差で示す。
- 拡散ベースの連続アクションヘッドと広範なデータミックス、トランスフォーマー中心のアーキテクチャは強い結果を生み、モデルが大きいほどゼロショットのロバスト性が向上する。
- トランスフォーマー中心設計、拡散アクションヘッド、広範なデータミックスを備えたアーキテクチャが、アブレーションで最良の性能を示す。
- Octo-Base(93M パラメータ)を含むモデルスケーリングは、より小さな変種よりもゼロショット性能とロバスト性を一般的に改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。