[論文レビュー] One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization
フィードフォワード法が単一の画像を約45秒で完全な360°テクスチャ付き3Dメッシュに変換します。ビュー条件付きの2D拡散モデルと一般化可能なSDFベースの再構築を組み合わせ、形状ごとの最適化を回避します。
Single image 3D reconstruction is an important but challenging task that requires extensive knowledge of our natural world. Many existing methods solve this problem by optimizing a neural radiance field under the guidance of 2D diffusion models but suffer from lengthy optimization time, 3D inconsistency results, and poor geometry. In this work, we propose a novel method that takes a single image of any object as input and generates a full 360-degree 3D textured mesh in a single feed-forward pass. Given a single image, we first use a view-conditioned 2D diffusion model, Zero123, to generate multi-view images for the input view, and then aim to lift them up to 3D space. Since traditional reconstruction methods struggle with inconsistent multi-view predictions, we build our 3D reconstruction module upon an SDF-based generalizable neural surface reconstruction method and propose several critical training strategies to enable the reconstruction of 360-degree meshes. Without costly optimizations, our method reconstructs 3D shapes in significantly less time than existing methods. Moreover, our method favors better geometry, generates more 3D consistent results, and adheres more closely to the input image. We evaluate our approach on both synthetic data and in-the-wild images and demonstrate its superiority in terms of both mesh quality and runtime. In addition, our approach can seamlessly support the text-to-3D task by integrating with off-the-shelf text-to-image diffusion models.
研究の動機と目的
- オブジェクトカテゴリを問わず機能する一般的な単一画像からの3D再構成ソリューションを動機付ける。
- 強力な2D拡散事前知識を活用して、3Dリフティングのための多視点予測を生成する。
- フィードフォワードで最適化不要の360°メッシュ再構成パイプラインを開発する。
- 入力画像に密着しつつ、幾何品質と3D一貫性を向上させることを保証する。
提案手法
- 単一の入力画像から複数視点の画像を生成するために、ビュー条件付き2D拡散モデル(Zero123)を使用する。
- 入力ビューの高度を推定し、多視点セットのカメラポーズを構築する。
- コストボリュームベースの一般化可能なニューラル表面再構成(SparseNeuS)を適用して、1回のパスでテクスチャ付き3Dメッシュを生成する。
- 不一致な多視点予測を扱うため、2段階のソースビュー選択とグラウンドトゥルー予測混合監督で訓練する。
- Zero123の視点を再構成座標系に合わせる高度推定モジュールを導入する。
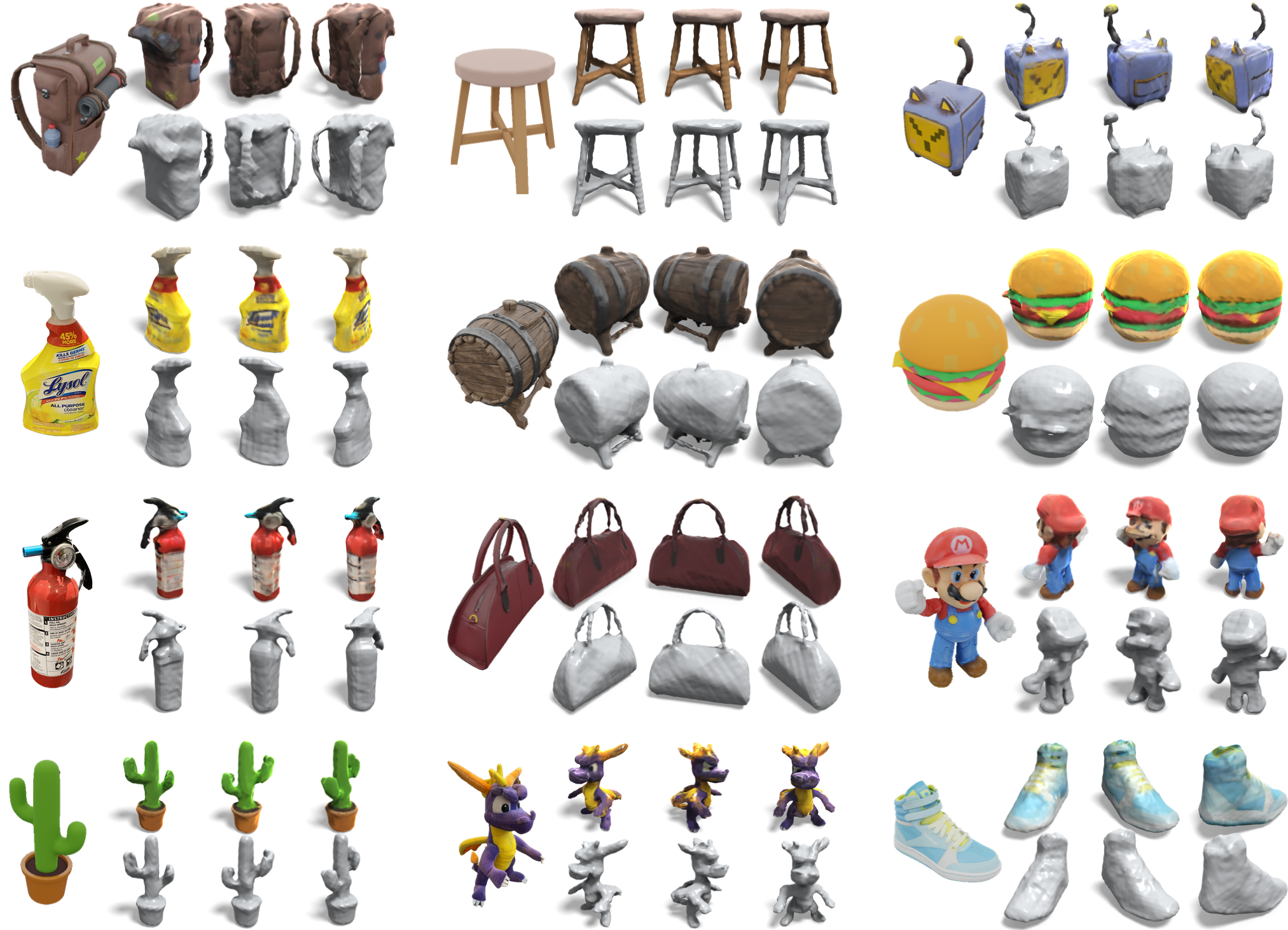
実験結果
リサーチクエスチョン
- RQ1単一画像を高品質でテクスチャ付きの360°メッシュに、形状ごとの最適化なしでリフトできるか?
- RQ2未見の物体カテゴリに跨って、2D拡散事前知識をいかに効果的に活用して頑健な3D再構成を実現するか?
- RQ3不完全な多視点予測を単一の前方伝搬再構成と調和させるために、どのような訓練戦略と姿勢推定機構が必要か?
主な発見
- 本手法は、単一画像から約45秒で完全な360°テクスチャ付きメッシュを再構成し、形状ごとの最適化を必要としない。
- 2段階の視点選択と深度監視付きSparseNeuSを用いると、予測視点に対するNeRF/SDF最適化よりも360°の幾何と3D一貫性が向上する。
- 高度推定は、安定したカメラポーズを可能にするのに十分な精度であり、正しい3D再構成には不可欠である。
- 本手法は、競合するゼロショットおよび最適化ベースのベースラインと比較して、幾何学的忠実度と入力画像への適合性が優れており、実行時間も競争力がある。
- 既製の2Dテキストから画像拡散モデルと統合することで、テキストから3Dへの拡張が可能。
![Figure 2: Our method consists of three primary components: (a) Multi-view synthesis : we use a view-conditioned 2D diffusion model, Zero123 [ 36 ] , to generate multi-view images in a two-stage manner. The input of Zero123 includes a single image and a relative camera transformation, which is parame](https://ar5iv.labs.arxiv.org/html/2306.16928/assets/figures/pipeline.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。