[論文レビュー] Overcoming catastrophic forgetting with hard attention to the task
この論文は、層ごとにほぼバイナリの注意マスクを学習するタスクベースのハードアテンション機構(HAT)を導入し、前のタスクからの情報を保持しつつ新しいタスクを学習することで忘却を大幅に削減し、モデル圧縮を可能にする。
Catastrophic forgetting occurs when a neural network loses the information learned in a previous task after training on subsequent tasks. This problem remains a hurdle for artificial intelligence systems with sequential learning capabilities. In this paper, we propose a task-based hard attention mechanism that preserves previous tasks' information without affecting the current task's learning. A hard attention mask is learned concurrently to every task, through stochastic gradient descent, and previous masks are exploited to condition such learning. We show that the proposed mechanism is effective for reducing catastrophic forgetting, cutting current rates by 45 to 80%. We also show that it is robust to different hyperparameter choices, and that it offers a number of monitoring capabilities. The approach features the possibility to control both the stability and compactness of the learned knowledge, which we believe makes it also attractive for online learning or network compression applications.
研究の動機と目的
- 逐次タスク学習における壊滅的な忘却を動機づけ、対処する。
- タスク識別に条件付けされた軽量で学習可能なハードアテンション機構を開発する。
- 勾配更新を制約することで、古いタスクの再訓練なしに同時学習を可能にする。
- モデルのスパース性を促進し、実用的な展開のための監視・圧縮機能を提供する。
提案手法
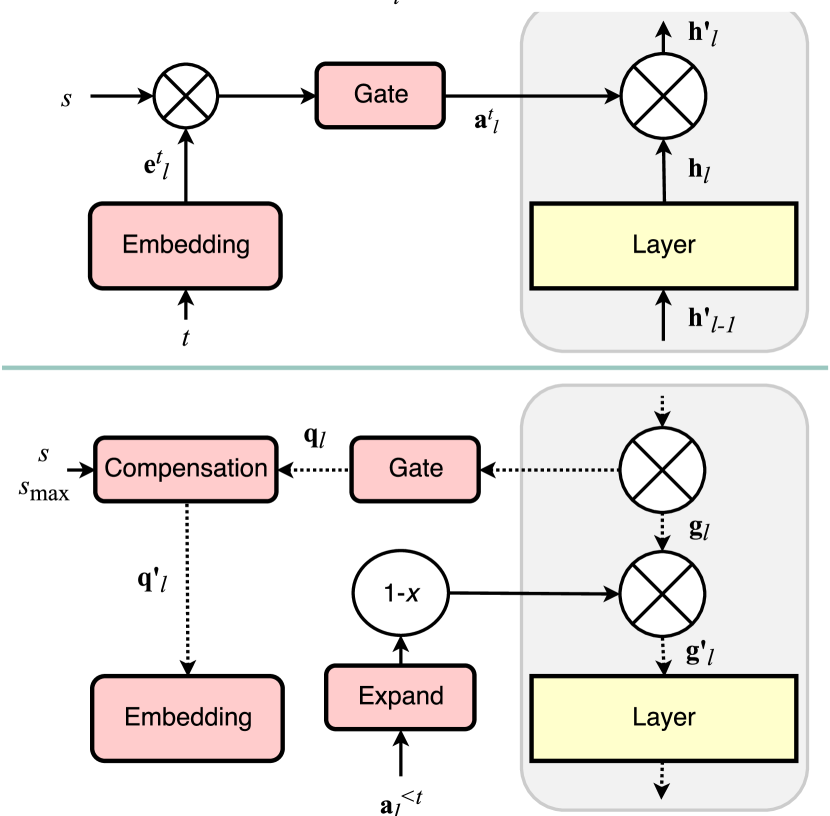
- 層ごとのハードアテンションマスク a_l^t を、スケーリングパラメータ s を用いたシグモイドゲートを使って微分可能なタスク埋め込み e_l^t から導出する。
- 過去のタスクに対して要素ごとの最大をとって累積アテンション a^≤t を計算し、重要なユニットを保持する。
- 前タスクで重要なユニットの更新を抑制するゲーティング項を用いて、a^≤t によって勾配を修正する。
- 訓練エポックにわたってゲーティングパラメータ s をアニールし、可塑性と安定性のバランスを取るとともに、効果的な学習信号を維持するために埋め込み勾配補償を実施する。
- タスク間でのユニットの疎な使用を促す注意重み付きL1正則化項を追加し、圧縮可能性パラメータ c を導入する。
- 標準化されたアーキテクチャと評価プロトコルで、8つの多様な画像データセットに対してHATをベースライン(EWC、SI、LWF、LFL、PathNet、PNN、IMMの派生)と比較する。
実験結果
リサーチクエスチョン
- RQ1HATは、複数タスクの系列にわたって、最先端のベースラインと比較して壊滅的な忘却をどの程度効果的に低減できるか?
- RQ2忘却削減はハイパーパラメータの選択やタスク順序に対して頑健か?
- RQ3HATは容量使用量や重み再利用の監視機能を提供し、精度を犠牲にせずにモデル圧縮をサポートできるか?
- RQ4異なる評価設定(マルチタスク、インクリメンタルクラス、置換データセット)でのHATの性能はどうか?
主な発見
| アプローチ | rho≤2 | rho≤8 |
|---|---|---|
| LFL | -0.73 (0.29) | -0.92 (0.08) |
| LWF | -0.14 (0.13) | -0.80 (0.06) |
| SGD | -0.20 (0.08) | -0.66 (0.03) |
| IMM-Mode | -0.11 (0.08) | -0.49 (0.05) |
| IMM-Mean | -0.12 (0.10) | -0.42 (0.04) |
| EWC | -0.08 (0.06) | -0.25 (0.03) |
| PathNet | -0.09 (0.16) | -0.17 (0.23) |
| PNN | -0.11 (0.10) | -0.11 (0.01) |
| HAT | -0.02 (0.03) | -0.06 (0.01) |
- HATはt≥2タスクのときに一貫してベースラインを上回り、主な8タスクシーケンスでρ≤2 が -0.02、ρ≤8 が -0.06 を達成(ベースラインに対する忘却削減は55%–75%)。
- 8タスク全体の平均で、設定により忘却を45%〜75%削減し、多くのベースラインより分散が小さい。
- HATはタスク間のネットワーク容量使用と重み再利用の監視を可能にし、元のサイズの1%〜21%へ圧縮しつつ高い精度を維持することをサポートする。
- 追加設定(インクリメンタルクラス、パーミューテッドMNIST、スプリットMNIST)でも、HATは強力なベースラインに対して顕著な改善を達成(CIFARインクリメンタルクラス: 約55%忘却削減、パーミューテッドMNIST: 約52%削減、スプリットMNIST: 約80%削減)。
- HATの2つのハイパーパラメータ(安定性 s_max と圧縮可能性 c)は、広い範囲で頑健な性能を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。